Hadoop集群安装
一.环境准备
[注意]我的主机系统就是linux,如果是windows需要自己下载一些终端连接的工具
二.安装
1.虚拟机准备

直接finish,开始配置网卡。
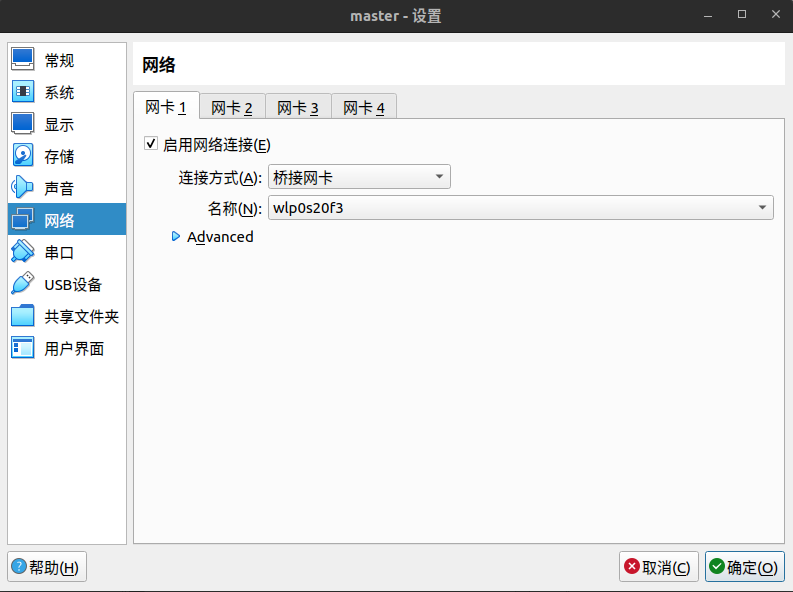
简单点说,桥接网络我们用来上网的,其次是host-only,我们拿来和宿主机进行通信用。
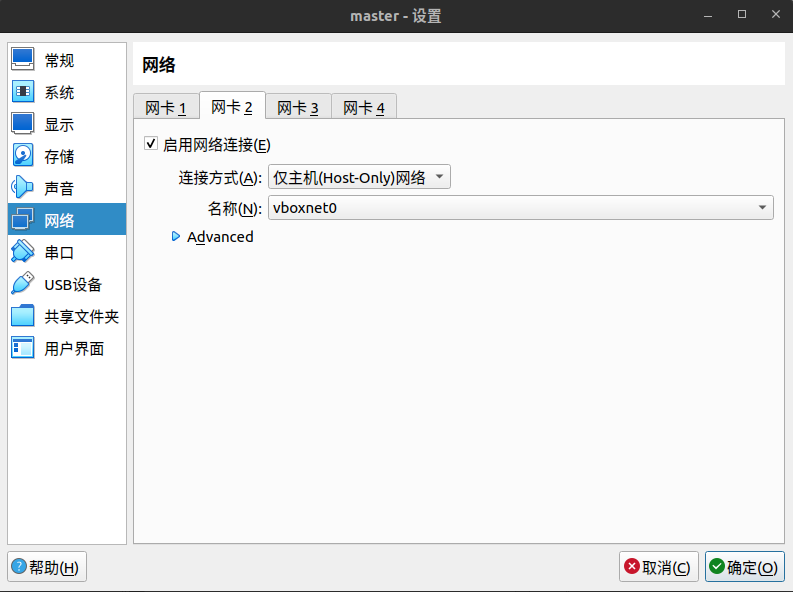
host-only的网卡需要单独设置,在 工具->网络 里面,创建
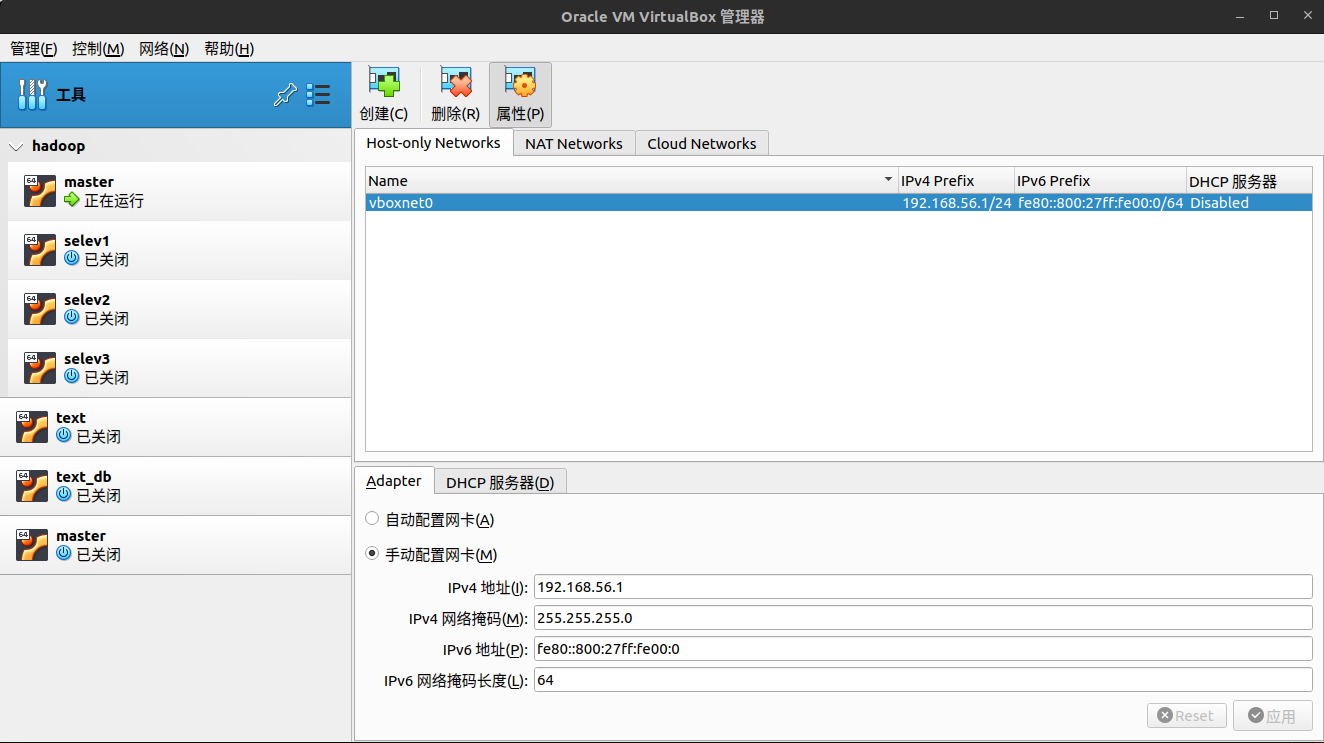
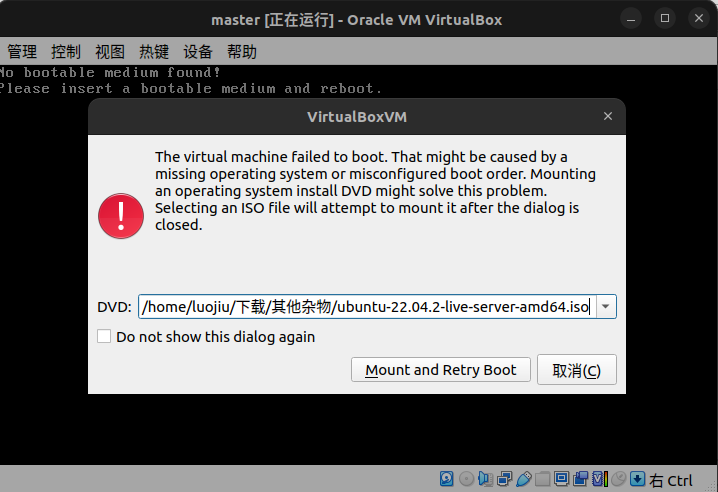
需要你配置网卡的ip4的信息,需要和你那几个机器的静态ip在同一个网段下,然后启动机器,会让你选择镜像,然后Mount and Retry Boot。
第一个直接回车,选择语言,我们选英语,然后回车

这个是网络,第一个是升级,第二个是跳过,直接跳过
下面是键盘布局不用管直接跳过
这里可以选择安装模式,有正常安装和最小化安装,我们选择最小化安装,方向键控制光标移动,空格键为选中,回车确定。
网络配置,先不用管,跳过
proxy地址,直接跳过
镜像源,这里我使用的是阿里源
磁盘分区,由于我们是虚拟机,直接干就完了,不用考略分区,啥都不动,下一步即可,有需求可以自己改分区
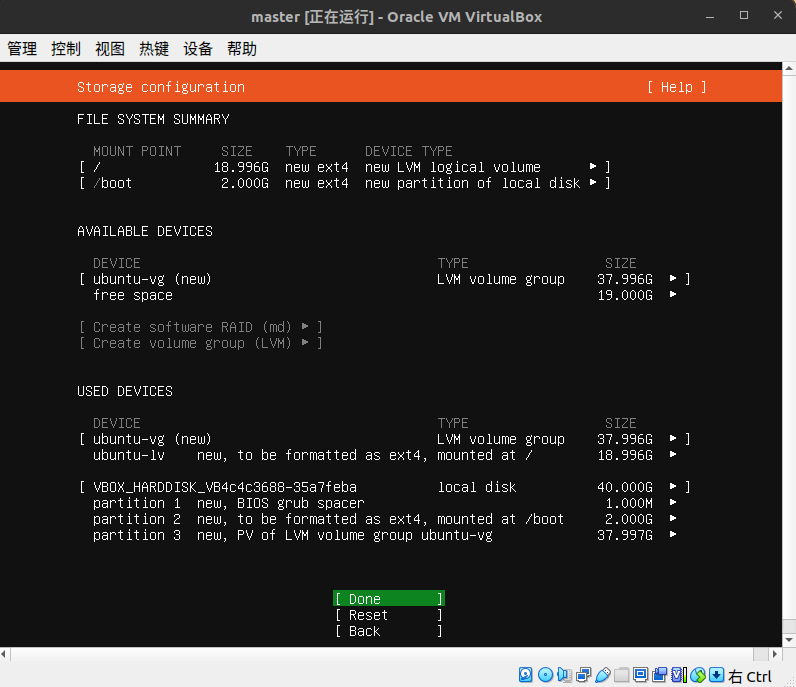
这里是点continue
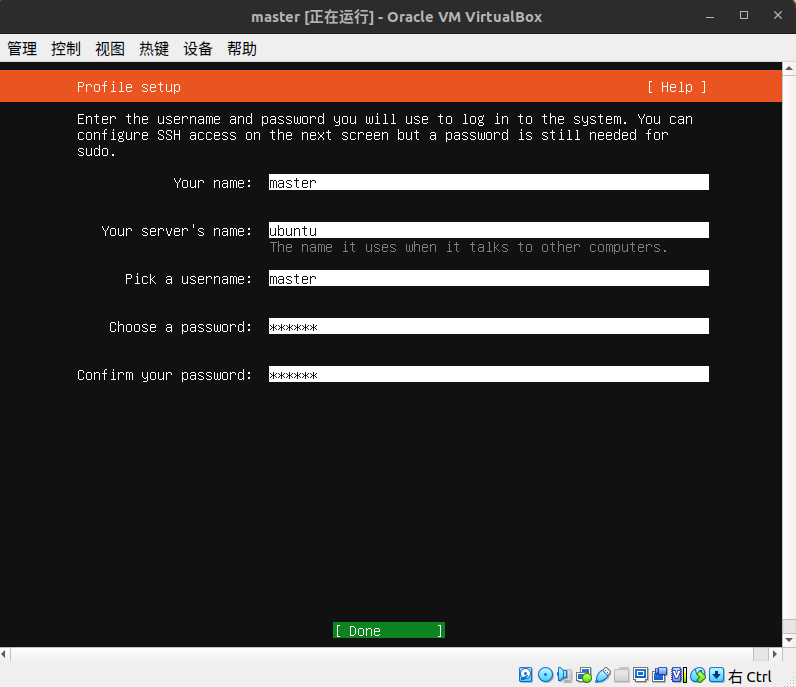
配置信息,最下面三个就是你的初始用户的用户名和密码
安装ssh远程工具
这一页不用管直接下一步
开始等待安装系统
安装成功,重启机器
这个界面敲一下回车,就那个叫entry的
至此,装机结束,我们开始为hadoop安装做准备
- 先设置root密码(输入密码是不显示的,不要以为键盘有问题)
sudo passwd
- 执行拉取软件列表以及更新命令
sudo apt-get update
sudo apt-get upgrade # 该命令需要在弹出安装内容后,你输入"y"回车确定安装
- 安装常用工具(好奇的可以自行去查阅每个工具的作用)
sudo apt install vim gcc g++ make cmake netcat net-tools
开始配置静态ip(要和你一开始做的host-only的网卡在同一个网段下)
ifconfig # 查看网卡名字
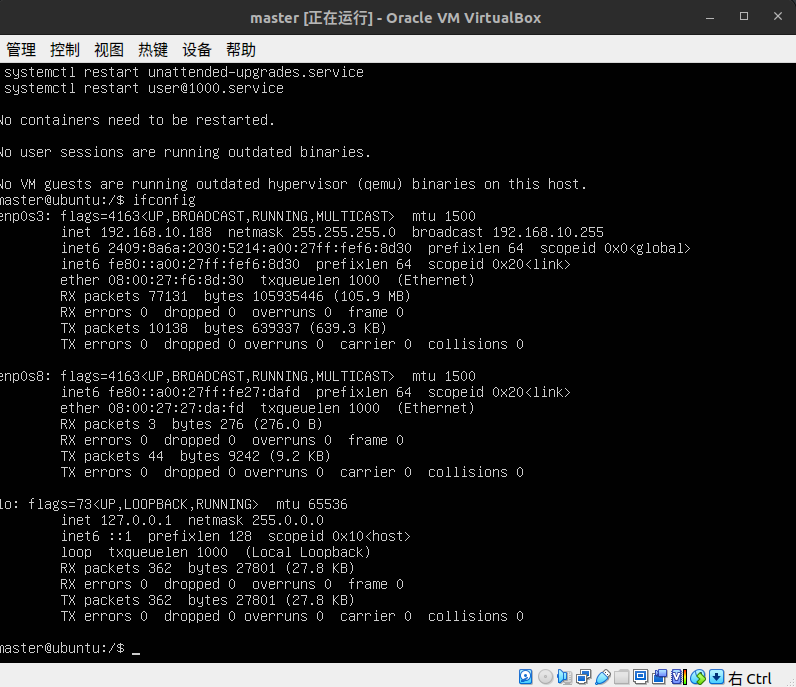
这里可以看到三张网卡,一张是enp0s3,一张是enp0s8,还有一张本地回环网卡,其中enp0s3就是我们那个桥接网卡,enp0s8是host-only,我们就是要给这张网卡配置为静态的ip,而enp0s3是上网用的不要动
route -n # 查看网关
# 进入配置文件
sudo vim /etc/netplan/00-installer-config.yaml

修改如上图所示,要保证你写的静态ip网段一致
sudo netplan apply # 使其改动生效
ifconfig # 再次查看ip是否生效

当你看见enp08s的inet 192.168.56.17的时候,就明白静态ip配置成功了
ok到这里,我们开始准备其他几个虚拟机,步骤都是一样的,你可以选择虚拟机复制然后修改静态ip的值,最好是准备四台虚拟机,一个为主节点,其他三个为从节点。
我演示一遍复制虚拟机的步骤,如果要完全重做虚拟机可以从头开始做完其他三台虚拟机
由于是完全拷贝,所以虚拟机的登录密码也是一样的,我们要做的就是修改静态ip的值,不能让他们的静态ip一样
sudo vim /etc/netplan/00-installer-config.yuaml
sudo netplan apply
ifconfig
# 步骤都是一样的,我的机器IP分别是
master: 192.168.56.17
slave1: 192.168.56.18
slave2: 192.168.56.19
slave3: 192.168.56.20
# 你可以按照自己需要设置ip
好到这里我们准备好了四台虚拟机,并且静态ip都不一样后,这还没有结束,现在我们开始调配参数
为了方便我使用我本地主机连接这四台机器
想要安装总管终端可以使用以下命令
sudo apt install terminal # 注意主机得是linux,window忽略
在终端中使用ssh连接
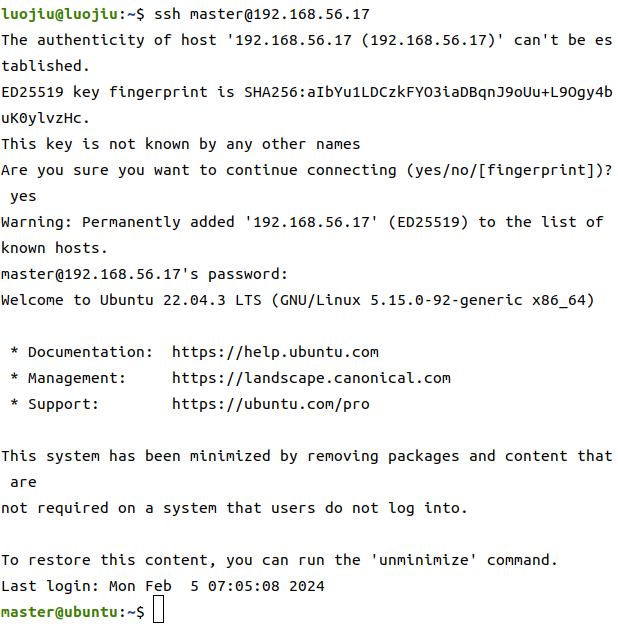
ssh master@192.168.56.17
# 第一次连接需要输入yes 回车
# 然后输入远程用户的密码
# 我们将四台机器同时连接上
# 修改自己名字
sudo vim /etc/hostname
# 分别对应master,slave1,slave2,slave3即可
# 修改结束后需要重启机器
# 修改主机列表
sudo vim /etc/hosts
# 四台机器都需要一样,是为了互相之间可以认识
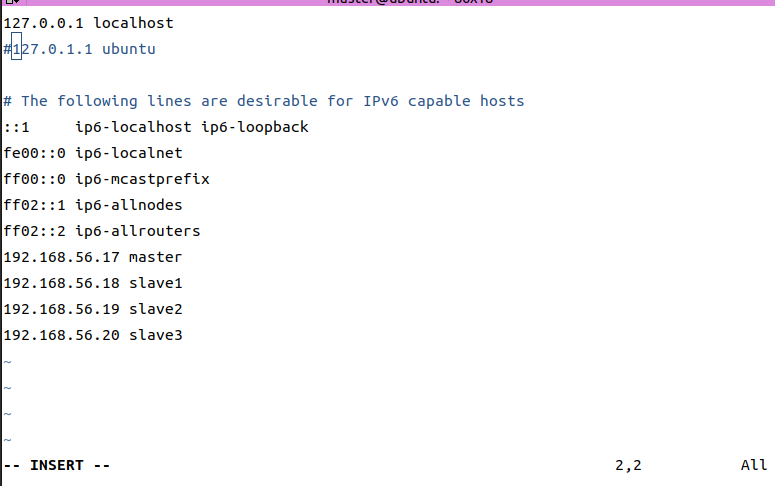
确保四台机器都是一样的,一定一定要给第二行的127.0.0.1 给注释或者删除掉
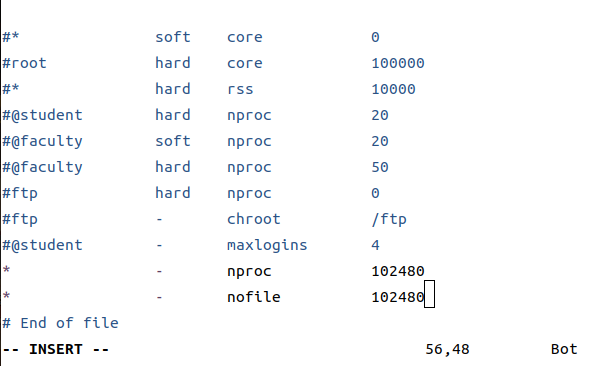
sudo vim /etx/security/limits.conf
# 在配置文件中加上以下参数(也是四台机器都要配置)
* - nproc 102480
* - nofile 102480
关闭防火墙(没有防火墙就跳过此步)
systemctl stop firewalld
systemctl status firewalld
开始配置jdk8
在主机找到你已经下载好的jdk8
使用scp命令发送给master机器
scp ./jdk-8u341-linux-x64.tar.gz master@192.168.56.17:~/

tar zxvf ./jdk-8u341-linux-x64.tar.gz
mv ./jdk1.8.0_341 jdk1.8
sudo mv ./jdk1.8 /opt
sudo vim /etc/proflie # 配置jdk环境变量
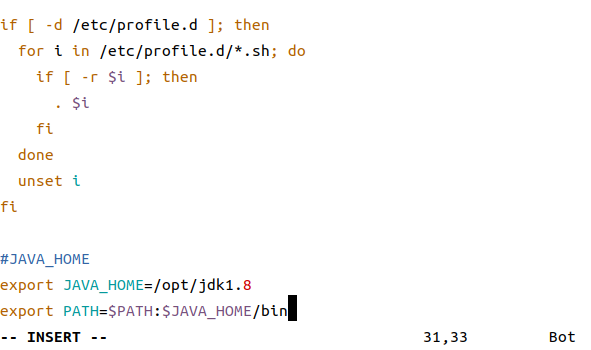
在文件末尾添加上
#JAVA_HOME
export JAVA_HOME=/opt/jdk1.8
export PATH=$PATH:$JAVA_HOME/bin
# 刷新环境变量
source /etc/profile
java -version # 出现java版本号说明成功
请确保四台机器都是做了相同的操作。
ssh免密登录
需要让master对于任何从机都能进行免密登录
(在master机器上):ssh-keygen -t rsa # 生成密钥对
会生成私钥和公钥,我们需要将公钥发送到目标服务器
ssh-copy-id <remote_username>@<remote_server>
该命令会将本地计算机上的公钥复制到目标服务器的 ~/.ssh/authorized_keys文件中。你可能需要输入目标服务器的密码进行确认
我们用master给其他的slave1,slave2,slave3都发一遍,还有master自己,你没听错,自己和自己也必须互通
ssh-copy-id master@slave1
ssh-copy-id master@slave2
ssh-copy-id master@slave3
ssh-copy-id master@master
然后我们用主机测试
ssh master@slav1
如果不需要输入密码直接连接上了从机证明ssh免密配置成功,每台从机都要保证成功
现在正式开始安装hadoop集群
找到hadoop的安装包,通过宿主机发送给master
scp ./hadoop-3.2.3.tar.gz master@192.168.56.17:~/
(在master机器上)
tar -zxvf ./hadoop-3.2.3.tar.gz
mv ./hadoop-3.2.3 hadoop
sudo mv ./hadoop /opt
cd /opt/hadoop # 一定得是755
mkdir -m 755 datadir
mkdir -m 755 tmp
开始配置环境变量
sudo vim /etc/profile
添加一下内容
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
刷新环境变量
source /etc/profile
hadoop # 出现一大堆提示表示环境安装成功
然后我们开始修改hadoop的配置文件
<1> ./hadoop/etc/core-site.xml
---------------------------------------------
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
---------------------------------------------
<2> ./hadoop/etc/hadoop-env.sh
---------------------------------------------
export JAVA_HOME=/opt/jdk1.8
---------------------------------------------
<3> ./hadoop/etc/hdfs-site.xml (私钥需要改位置)
---------------------------------------------
<property>
<name>dfs.namenode.name.dir</name>
<value>/opt/hadoop/namedir</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>/opt/hadoop/datadir</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop/tmp</value>
</property>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.webhdfs.enabled</name>
<value>true</value>
</property>
<property>
<name>dfs.support.append</name>
<value>true</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<property>
<name>dfs.ha.fencing.methods</name>
<value>sshfence</value>
</property>
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
# 私钥的位置
<value>/home/hadoop/.ssh/id_rsa</value>
</property>
---------------------------------------------
<4> ./hadoop/etc/mapred-site.xml
---------------------------------------------
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
---------------------------------------------
<5> ./hadoop/etc/yarn-site.xml
---------------------------------------------
<property>
<name>yarn.resourcemanager.webapp.address</name>
<value>master:8088</value>
</property>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
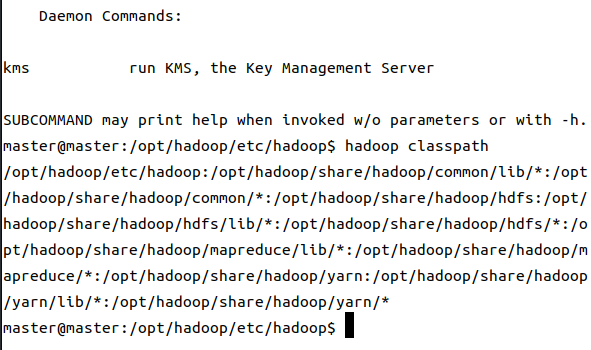
<name>yarn.application.classpath</name>
<value>/opt/hadoop-3.2.3/etc/hadoop:/opt/hadoop-3.2.3/share/hadoop/common/lib/*:/opt/hadoop-3.2.3/share/hadoop/common/*:/opt/hadoop-3.2.3/share/hadoop/hdfs:/opt/hadoop-3.2.3/share/hadoop/hdfs/lib/*:/opt/hadoop-3.2.3/share/hadoop/hdfs/*:/opt/hadoop-3.2.3/share/hadoop/mapreduce/lib/*:/opt/hadoop-3.2.3/share/hadoop/mapreduce/*:/opt/hadoop-3.2.3/share/hadoop/yarn:/opt/hadoop-3.2.3/share/hadoop/yarn/lib/*:/opt/hadoop-3.2.3/share/hadoop/yarn/*</value> #通过hadoop classpath获取value内容
</property>
---------------------------------------------
<6> vim workers
---------------------------------------------
slave1
slave2
slave3
不允许有任何空格
---------------------------------------------
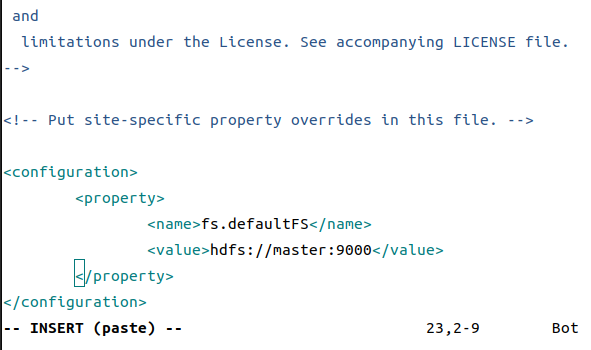
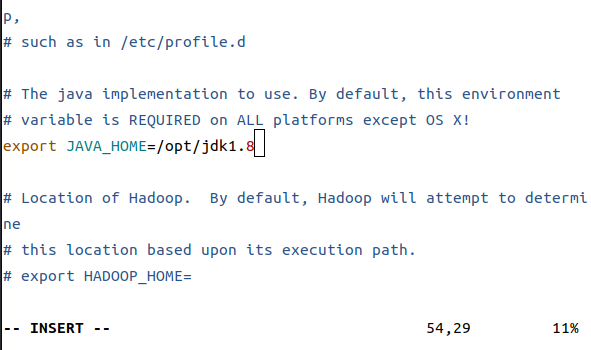
这里注意私钥位置,主机名要换成你自己的主机名
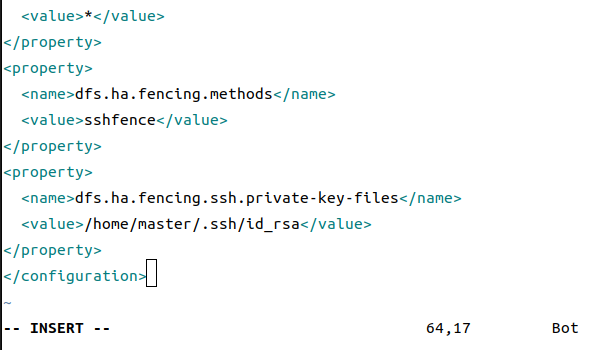
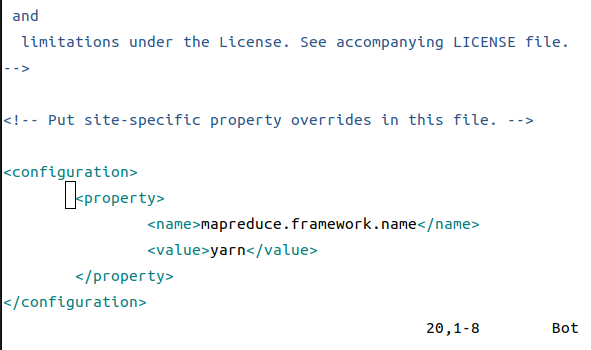
最后这个需要先使用hadooop classpath先获取,然后替换掉原本的
OK,现在大部分工作我们都做完了,现在将master上的hadoop,通过scp发送到其他三台从机上
sudo scp -r ./hadoop/ master@slave1:~
sudo scp -r ./hadoop/ master@slave2:~
sudo scp -r ./hadoop/ master@slave3:~
记得需要给hadoop从~移动到opt下,三台机器都需要
sudo mv ./hadoop /opt
开始为三台从机配置环境
sudo vim /etc/profile
#HADOOP_HOME
export HADOOP_HOME=/opt/hadoop
export PATH=$PATH:$HADOOP_HOME/sbin
export PATH=$PATH:$HADOOP_HOME/bin
刷新环境变量
source /etc/profile
ok,大功告成,我们来试试能不能用吧,成败在此一举
# 格式化(只在主节点上运行)
hdfs namenode -format
start-dfs.sh
start-yarn.sh
# 该命令用于主节点无法正常启动只有SecondNameNode 的情况
hdfs namenode -recover
# 测试
hdfs dfsadmin -report
hdfs: http://master:9870
yarn: http://master:8088
# 如果没有啥报错,恭喜你,成功了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号