
spark sql
1.rdd to dataframe
rdd.toDF(schema=None, sampleRatio=Non)
session.createDataFrame(data, schema=None, samplingRatio=None, verifySchema=True)
rdd转换为dataframe可以声明schema,也可以设置samplingRatio,让系统自己去猜测数据集的结构。(Error: Some of types cannot be determined by the first 100 rows, please try again with sampling)
2.spark sql 读取json文件,要求json文件必须每行都是一个标准的json数据。
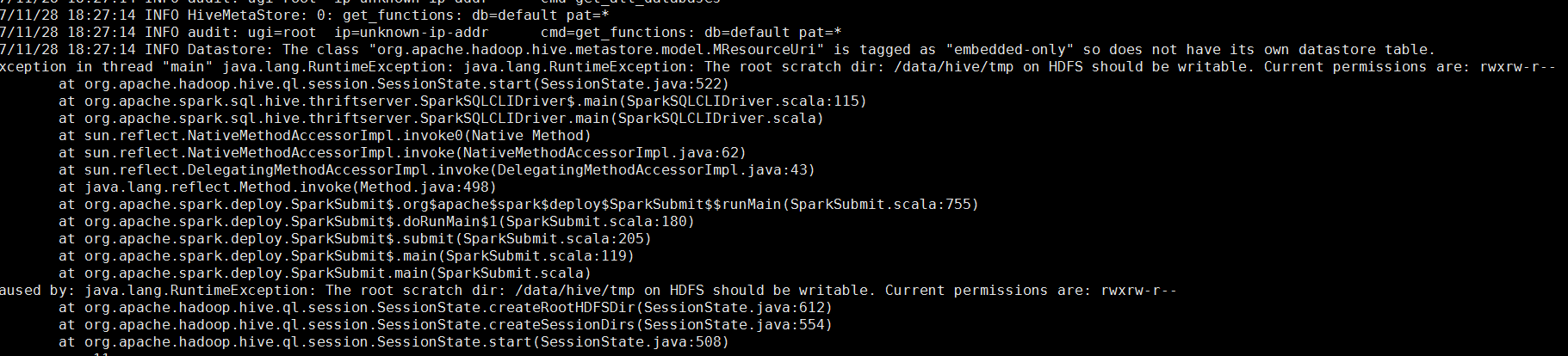
3.spark与hive继承时,如果遇到以下错误:
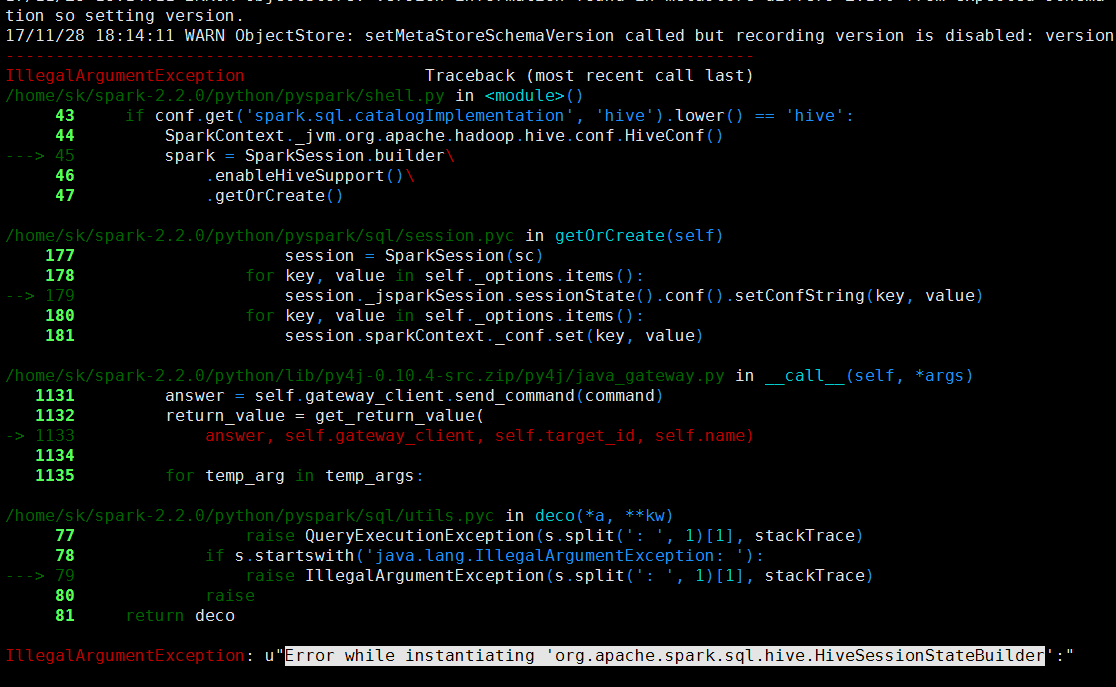
有可能是文件权限不正确,pyspark的日志不准备,可以试试spark-sql或spark shell,

 浙公网安备 33010602011771号
浙公网安备 33010602011771号