

DS博客作业05--查找
0.PTA得分截图

1.本周学习总结
1.1 总结查找内容
静态查找
查找表的分类:
静态查找:
仅作查询和检索操作的查找表。
动态查找:
有时在查询之后,还需要将“查询”结果为“不在查找表中”的数据元素插入到查找表中者,
从查找表中删除其“查询”结果为“在查找表中”的数据元素。
查找算法的评价标准
关键字的平均比较次数,即平均搜索长度(ASL)
计算:
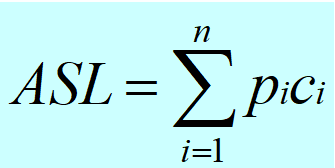
n:记录的个数
pi:查找第i个记录的概率 ( 通常认为pi =1/n )
ci:找到第i个记录所需的比较次数
线性表的查找
查找方法的分类:
*顺序查找
*二分查找
*分块查找
顺序查找
顺序查找的基本操作:从表中最后一个记录开始,逐个进行记录的关键字和给定值的比较,若某个记
录的关键字和给定值比较相等,则查找成功,找到所查记录;反之,若直至第一个记录,其关键字
和给定值比较都不相等,则表明表中没有所查记录,查找不成功
顺序查找的优缺点
优点
·算法实现简单且适应面广
·对表的结构无任何要求,无论记录是否按关键字有序排列
·即适用于顺序表又适用于单链表
缺点
·平均查找长度较大,特别是当n很大时,查找效率较低
·速度慢,平均查找长度为 (n + 1) / 2
时间复杂度
时间复杂度为 O(n)
条件
无序或有序队列。
原理
按顺序比较每个元素,直到找到关键字为止
具体的操作代码
typedef int ElementType;
int sequential(int Array[], ElementType key, int n)
{
int index;
for(index = 0; index < n; index++)
{
if(EQ(Array[index], key))
{
return index + 1;
}
}
return -1;
}
ASL计算

二分查找
二分查找也称为折半查找,要求线性表中的节点必须己按关键字值的递增或递减顺序排列
适用范围
对于规模较大的有序表查找,效率较高。适合很少改动但经常查找的表
优点
·折半查找的效率比顺序查找要高。
·折半查找的时间复杂度为log2(n)
·折半查找的平均查找长度为log2(n+1) - 1
缺点
·折半查找只适用于有序表
·折半查找限于顺序存储结构,对线性链表无法有效地进行折半查找
时间复杂度
O(logn)
对于下列有序序列{10,14,21,38,45,47,53,81,87,99}
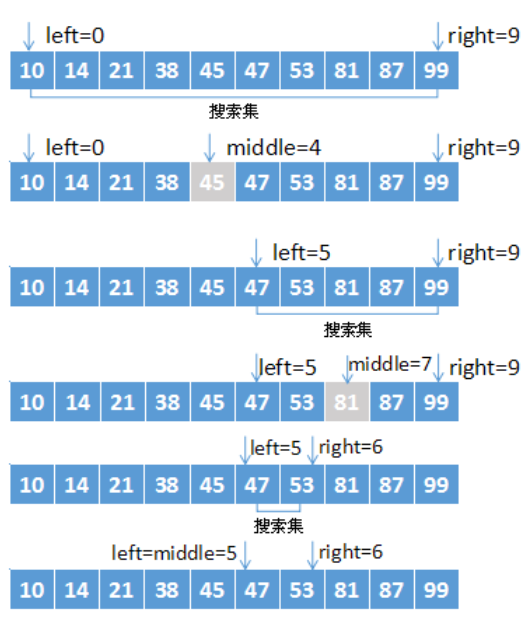
操作的代码
int BinSearch(SeqList R,int n,KeyType k)
{
int low=0,high=n-1,mid;
while (low<=high) //当前区间存在元素时循环
{
mid=(low+high)/2;
{
if (R[mid].key==k)//查找成功
{
return mid+1;
}
if (k<R[mid].key)
{
high=mid-1;
}
else
{
low=min+1;
}
}
return 0;
}
采用递归算法
int BinSearch1(SeqList R,int low,int high,KeyType k)
{
int mid;
if (low<=high)//查找区间存在一个及以上元素
{
mid=(low+high)/2; //求中间位置
if (R[mid].key==k) //查找成功返回其逻辑序号mid+1
{
return mid+1;
}
if (R[mid].key>k) //在R[low..mid-1]中递归查找
{
BinSearch1(R,low,mid-1,k);
}
else//在R[mid+1..high]中递归查找
{
BinSearch1(R,mid+1,high,k);
}
}
else
{
return 0;
}
}
对于下面的序列{1,2,3,4,5,6,7,8,9,10,11}
建立下列二叉搜索树
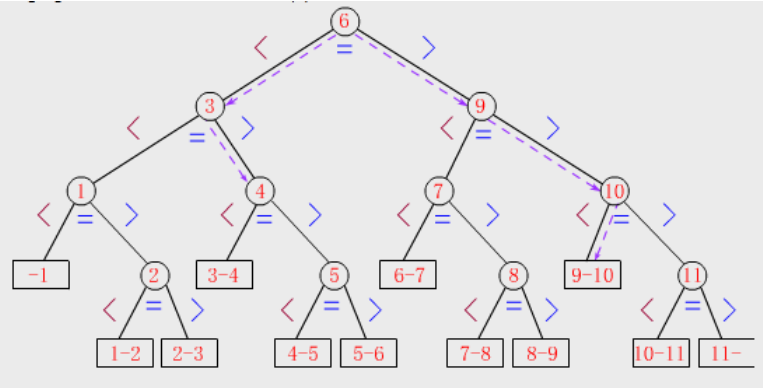
计算ASL
ASLscu=(1/11)(1+22+34+45)=3.36
ASLusc=(1/12)(34+8*4)=4.33
动态查找
二叉搜索树
概念
二叉搜索树(BST树):又叫二叉排序树,二叉查找树。它也可以是一棵空树
该树一般具有以下性质的二叉树:
·每个结点都有一个数据域,且所有节点的数据域互不相同;
·它的左子树不为空,则左子树上的所有结点的值都小于根节点的值;
·若它的右子树不为空,则右子树上的所有节点的值都大于根节点的值;
·左子树和右子树都是二搜索树。
注:对二叉搜索树进行中序遍历的数据是有序的,因此二叉搜索树也可成为二叉排序树。
二叉搜索树的操作
查找
·若根节点为空,即二叉搜索树为空。
·若X>根节点的data,在其右子树查找;
·若X<根节点的data,在其左子树查找;
·若X==根节点的data,则找到
·否则找不到
Position Find(BinTree BST, ElementType X)
{
if (!BST)
{
return NULL;
}
if (BST->Data == X)
{
return BST;
}
else if (X < BST->Data)
{
return Find(BST->Left, X);
}
else if (X > BST->Data)
{
return Find(BST->Right, X);
}
return BST;
}
插入
插入元素在二叉树中插入元素时,需检测该元素在树中是否已经存在,若存在则不进行插入。
·树为空,即二叉树为空时直接插入。
·树不为空
·若X>根节点的data,在右子树插入
·若X<根节点的data,在其左子树插入
·若X==根节点的data,,不插入;
·在找要插入的位置的时候始终记录双亲结点。
·找到要插入的位置之后,判断双亲结点的data和要插入的X的大小
·若X>双亲结点的data,则插入右子树,否则插入左子树。
BinTree Insert(BinTree BST, ElementType X)
{
if (BST == NULL) //空结点
{
BST = new BSTNode; //生成新结点
BST->Data = X;
BST->Left = BST->Right = NULL;
}
else if (X < BST->Data)
{
BST->Left = Insert(BST->Left, X); //插入左子树
}
else if (X > BST->Data)
{
BST->Right = Insert(BST->Right, X); //插入右子树
}
return BST;
}
删除
删除元素X:在二叉树中删除元素时,必须检测该元素在树中是否已经存在,若不存在则直接返回
false,不删除。若存在又分为以下四种情况:
·要删除的结点无孩子结点(叶子结点)。
·要删除的结点只有右孩子结点。
·要删除的结点只有左孩子结点。
·要删除的结点有左,右孩子结点。
情况1可以和情况2或者情况3合并,对于上述情况,相应的删除方法有:
·直接删除该结点
·删除该结点且被删除结点的双亲结点指向被删除孩子的右孩子结点。
·删除该结点且被删除结点的双亲结点指向被删除孩子的左孩子结点。
·在它的右子树中寻找最小的结点,用它的值替换被删除结点的值。
BinTree Delete(BinTree BST, ElementType X)
{
BinTree Tmp;
if (!BST)
{
printf("Not Found\n");
}
else
{
if (X < BST->Data)
{
BST->Left = Delete(BST->Left, X);
}
else if (X > BST->Data)
{
BST->Right = Delete(BST->Right, X);
}
else//考虑如果找到这个位置,并且有左节点或者右节点或者没有节点三种情况
{
if (BST->Left && BST->Right)
{
Tmp = FindMin(BST->Right); // 在右子树中找到最小结点填充删除结点
BST->Data = Tmp->Data;
BST->Right = Delete(BST->Right, BST->Data);// 递归删除要删除结点的右子树中最小元素
}
else
{ //被删除结点有一个或没有子结点
Tmp = BST;
if (!BST->Left)
{
BST = BST->Right;//有右孩子或者没孩子
}
else if (!BST->Right)
{
BST = BST->Left;//有左孩子,一定要加else,不然BST可能是NULL,会段错误
}
free(Tmp); //如无左右孩子直接删除
}
}
}
return BST;
}
找最大值
Position FindMin(BinTree BST)
{
if (BST != NULL)
{
while (BST->Left)
{
BST = BST->Left;
}
}
return BST;
}
找最小值
Position FindMax(BinTree BST)
{
if (BST != NULL)
{
while (BST->Right)
{
BST = BST->Right;
}
}
return BST;
}
平衡二叉树(AVL树)
基本定义
满足条件
·第一个条件是:本身是二叉搜索树
·第二个条件是,所有结点的左右子树高度差不超过1。
AVL树的四种失衡状态
(1)LL(左左)失衡
即插入或删除一个节点后,根节点的左孩子的左孩子还有非空节点,导致根节点的左子树高度与
右子树高度差大于1,致使AVL树失去平衡
(2)RR(右右)失衡
即插入或删除一个节点后,根节点的右孩子的右孩子还有非空节点,导致根节点的右子树高度与
左子树高度差大于1,致使AVL树失去平衡
(3)LR(左右)失衡
即插入或删除一个节点后,根节点的左孩子的右孩子还有非空节点,导致根节点的左子树高度与
右子树高度差大于1,致使AVL树失去平衡
(4)RL(右左)失衡
即插入或删除一个节点后,根节点的右孩子的左孩子还有非空节点,导致根节点的右子树高度与
左子树高度差大于1,致使AVL树失去平衡
四种调整的做法
(1)LL(左左)调整
操作过程:
·将根节点的左孩子作为新根节点
·将新根节点的右孩子作为原根节点的左孩子
·将原根节点作为新根节点的右孩子
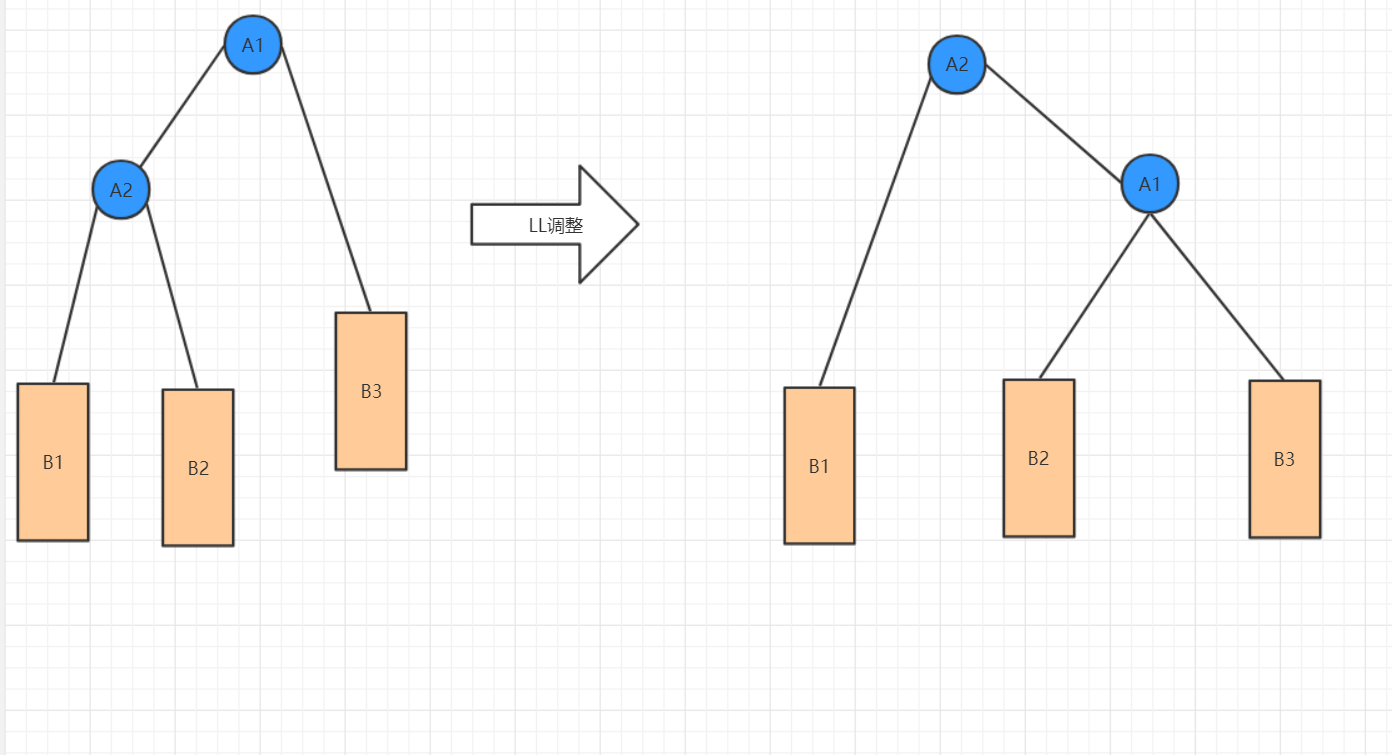
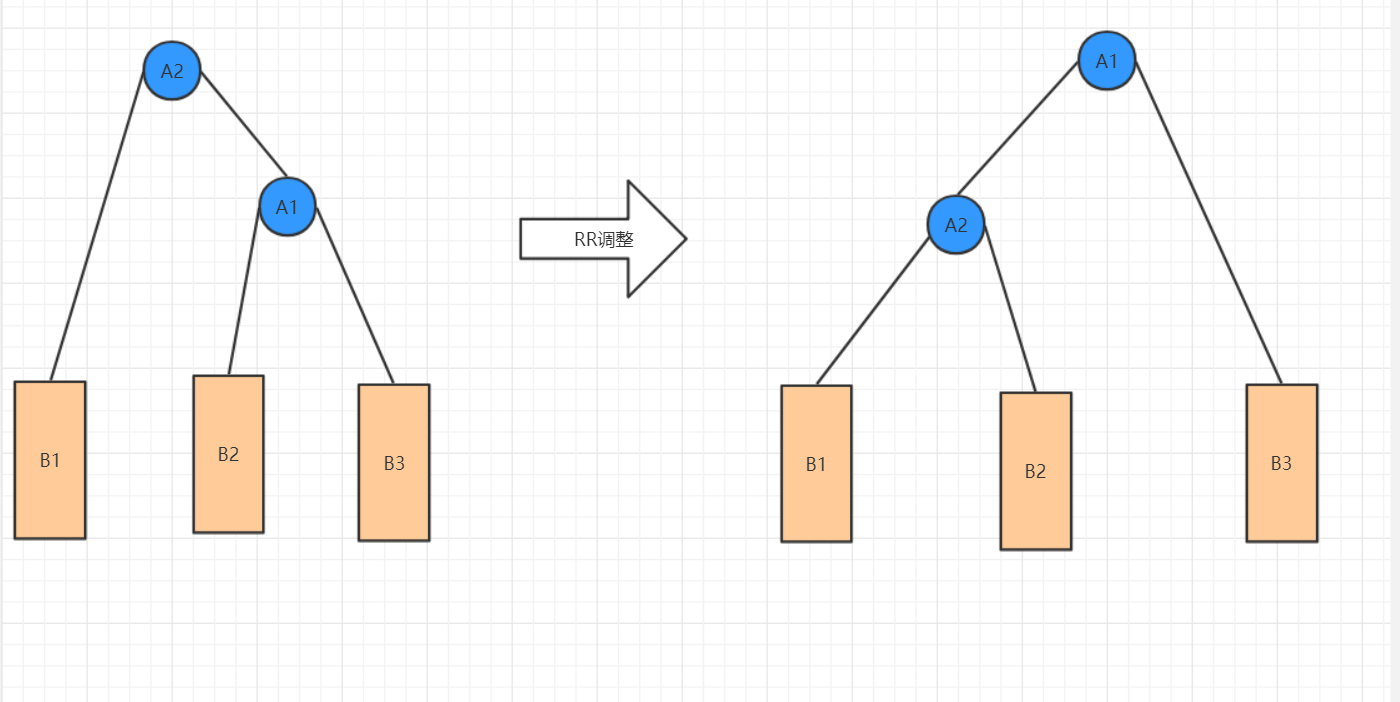
(2)RR(右右)调整
·将根节点的右孩子作为新根节点
·将新根节点的左孩子作为原根节点的右孩子
·将原根节点作为新根节点的左孩子
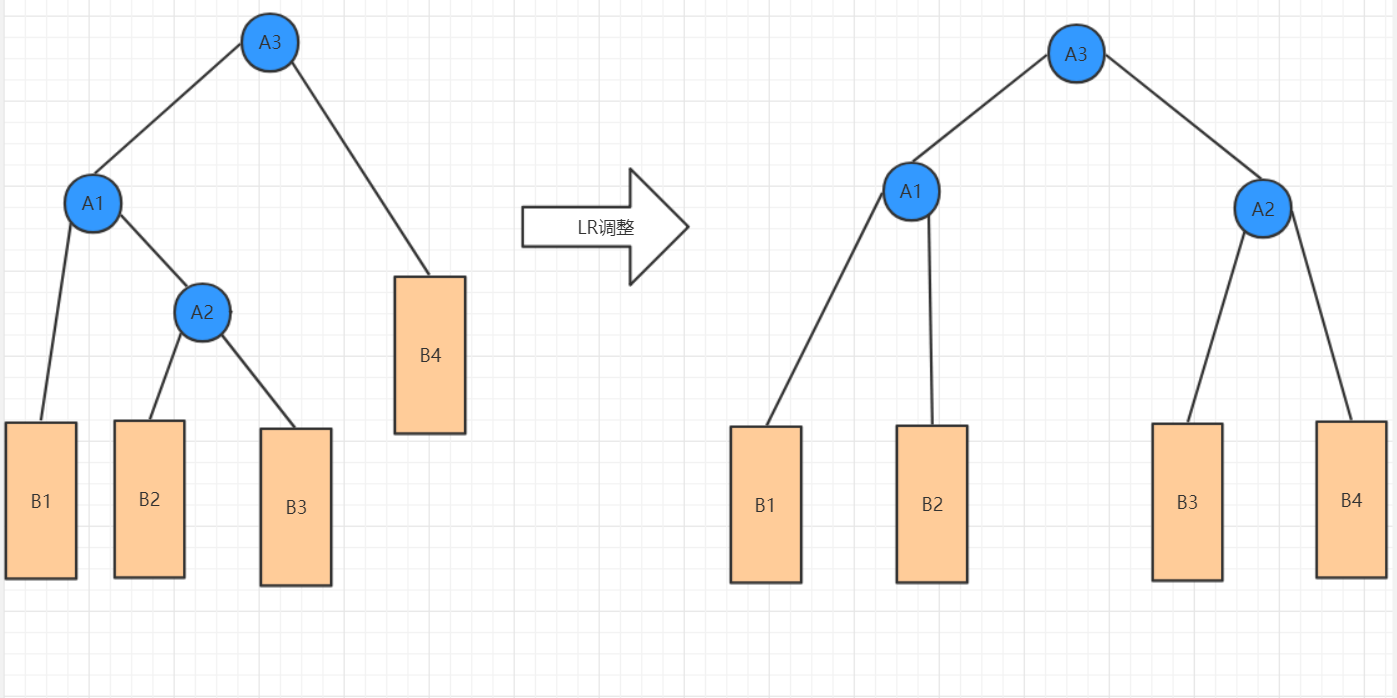
(3)LR(左右)调整
·围绕根节点的左孩子进行RR旋转
·围绕根节点进行LL旋转
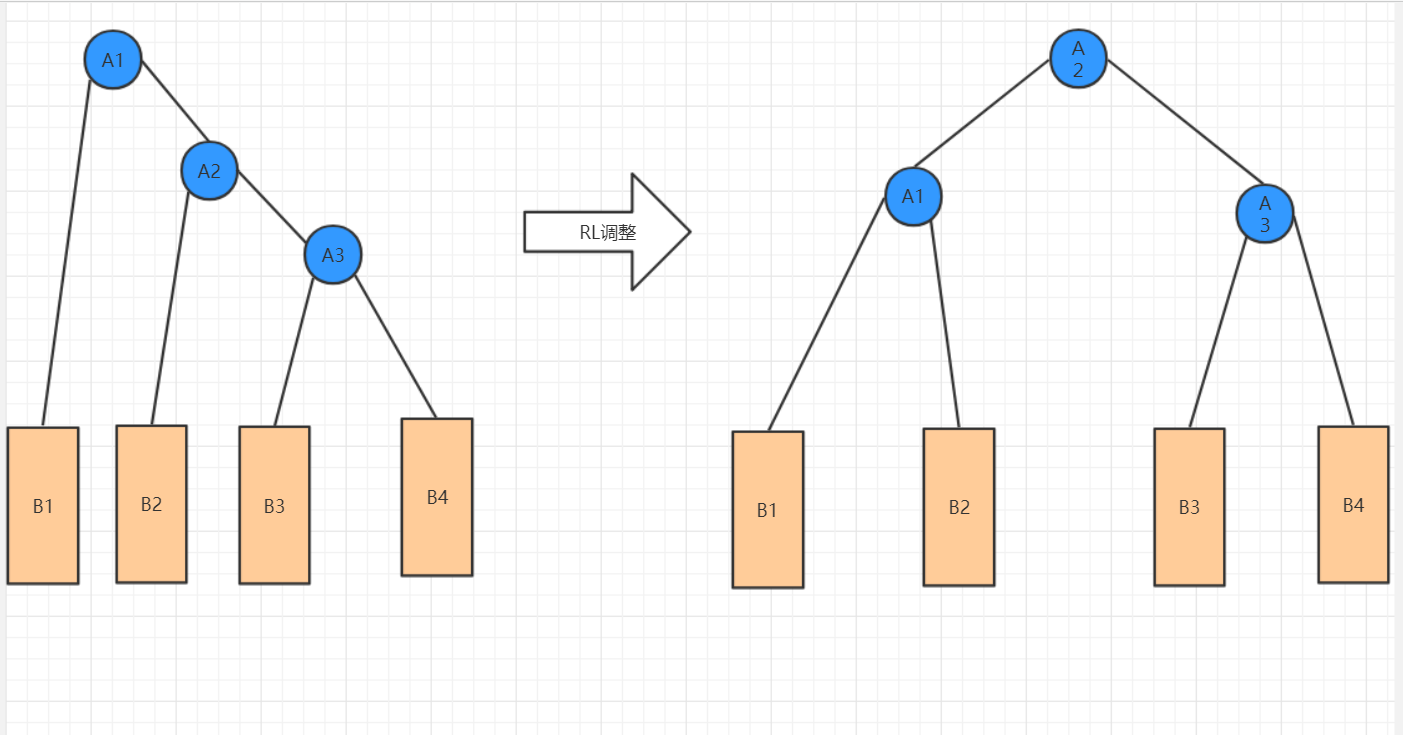
(4)RL(右左)调整
·围绕根节点的右孩子进行LL旋转
·围绕根节点进行RR旋转
B-树和B+树
基本定义
(1)每个结点最多有m-1个关键字。
(2)根结点最少可以只有1个关键字。
(3)每个结点中的关键字都按照从小到大的顺序排列,每个关键字的左子树中的所有关键字都小于
它,而右子树中的所有关键字都大于它。
(4)所有叶子结点都位于同一层,或者说根结点到每个叶子结点的长度都相同
B-树的插入
·B-树也是从空树开始,通过不断地插入新的数据元素构建的。但是 B-树构建的过程同前面章节的
二叉排序树和平衡二叉树不同,B-树在插入新的数据元素时并不是每次都向树中插入新的点
·在插入新的数据元素时,首先向最底层的某个非终端结点中添加,如果该结点中的关键字个数没有
超过 m-1,则直接插入成功,否则还需要继续对该结点进行处理。
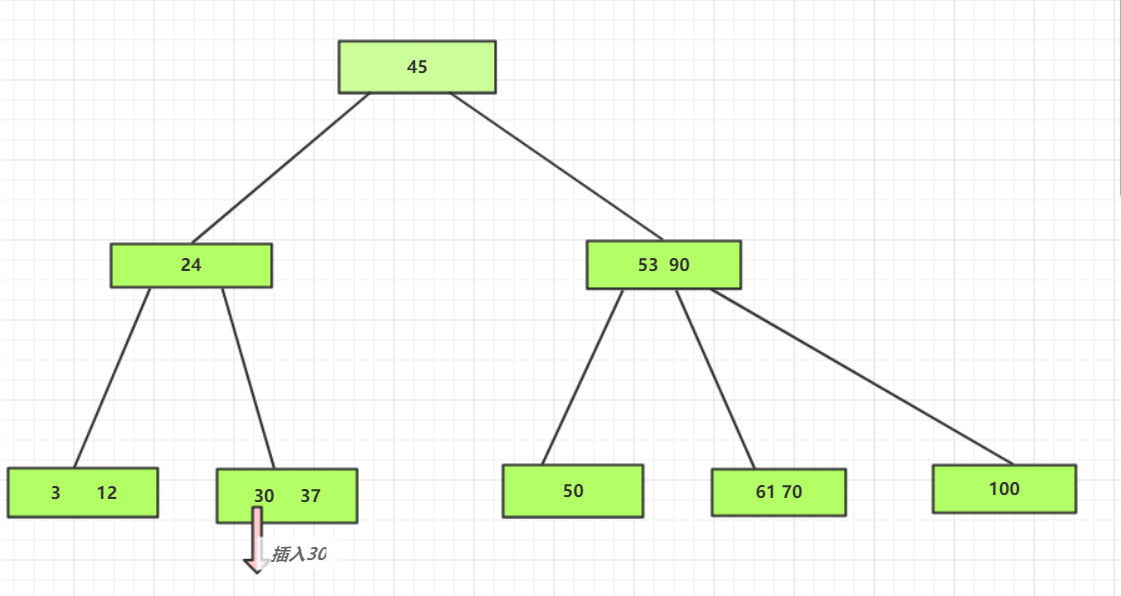
举例:
对于下面的B-树:最大MIN=2;

分别插入30,26,85,7;
(1)插入30
从根结点开始,由于 30 < 45,所以要插入到以 24 结点为根结点的子树中,再由于 24 <
30,插入到以 37结点为根结点的子树中,由于 37结点中的关键字个数小于 m-1=2,所以可以将
键字 30 直接插入到 30结点中
(2)插入26
从根结点开始,由于26<45,所以将26插入到24的子树中,由于26>24,所以将26插入到26的右子树中。
插入后发现M>2,所以进行调整,将30的两个指针储存到两个新的节点中,将30储存到其父节点中。
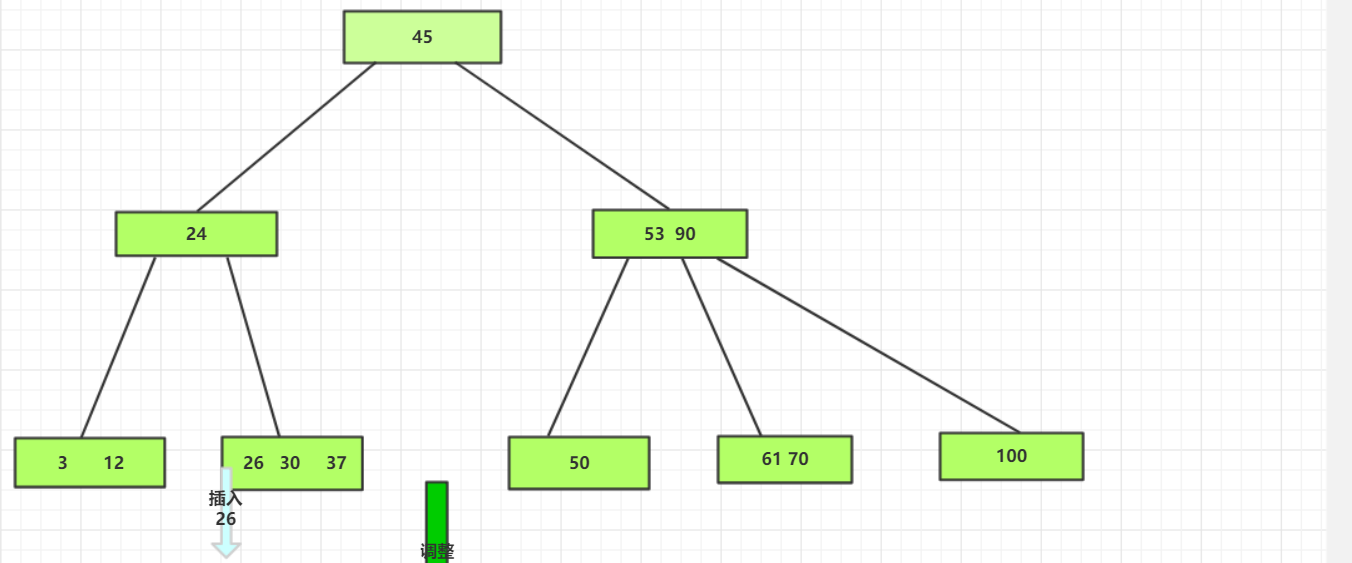
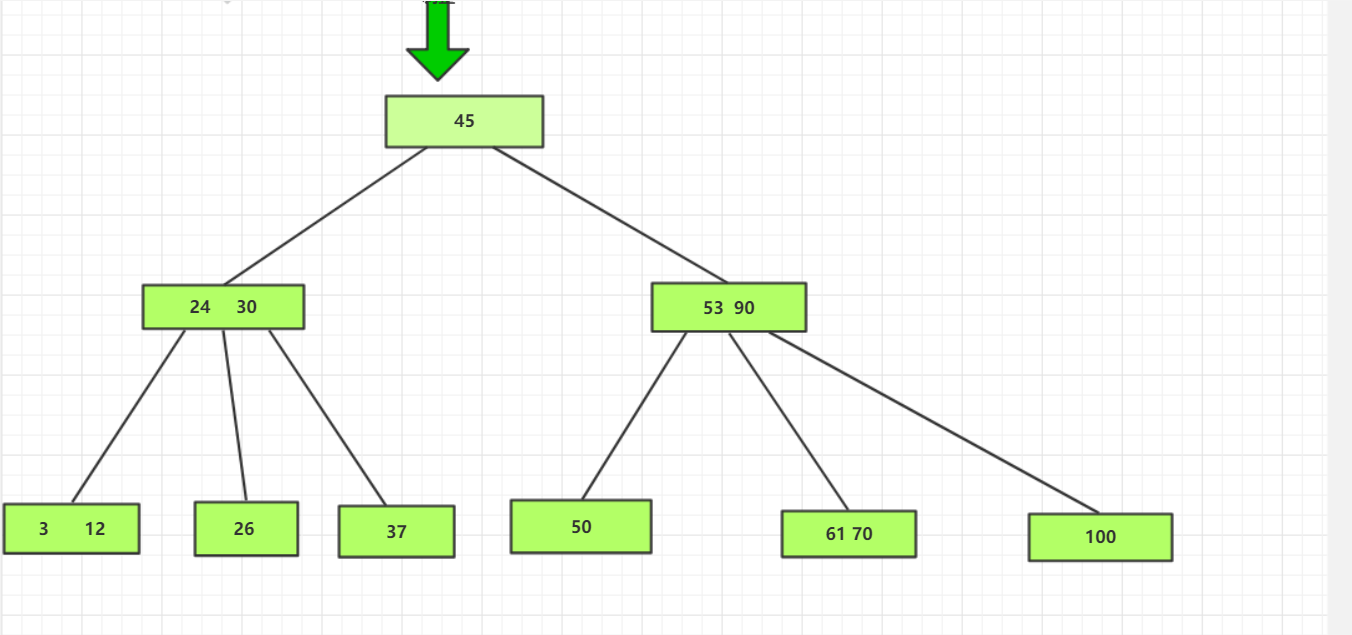
(3)插入85
开始比较,85>45所以将85插入到45的有根节点中,又因为53>85<90,所以将85插入到根节点61 和70中
插入后,该根节点的数m>2,所以要进行调整,将70储存到其父结点中,将61和85作为两个根节点储存到两个根节点
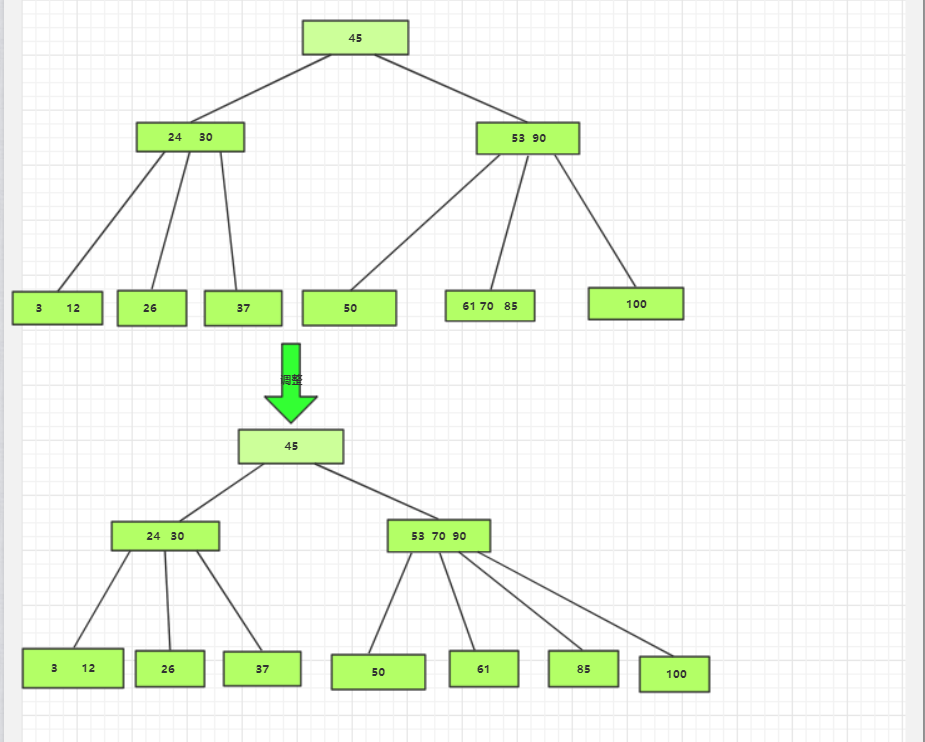
按照以上的方法继续操作

B-树的删除
B-树种删除关键字时,首先前提是找到该关键字所在结点,在做删除操作的时候分为两种情况:
一种情况是删除结点为 B-树的非终端结点(不处在最后一层)
另一种情况是删除结点为 B-树最后一层的非终端结点
如果该结点为非终端结点且不处在最后一层,假设用 Ki 表示,则只需要找到指针 Ai 所指子树中
最小的一个关键字代替 Ki,同时将该最小的关键字删除即可
如果该结点为最后一层的非终端结点,有下列 3 种可能:
·被删关键字所在结点中的关键字数目不小于m/2,则只需从该结点删除该关键字 Ki 以及相应的
指针 Ai
·被删关键字所在结点中的关键字数目等于(m/2)-1,而与该结点相邻的右兄弟结点或者左兄弟
结点中的关键字数目大于(m/2)-1,只需将该兄弟结点中的最小或者最大的关键字上移到双
亲结点中,然后将双亲结点中小于或者大于且紧靠该上移关键字的关键字移动到被删关键字
所在的结点中
·被删除关键字所在的结点如果和其相邻的兄弟结点中的关键字数目都正好等于(m/2)-1,假设
其有右兄弟结点,且其右兄弟结点是由双亲结点中的指针 Ai 所指,则需要在删除该关键字
的同时,将剩余的关键字和指针连同双亲结点中的 Ki 一起合并到右兄弟结点中
例如对于上面的B-树
删除数50
要删除50,我们观察可知,其右兄弟[61 70]的关键字大于2,所以将其中最小的关键字61上移到
其父节点中,,然后将其父结点中的关键字53移动到其左节点中。

删除53
据观察上图B-树,可知,在53的有右兄弟且其含有一个关键字,所以在删除53后,将其合并到其有
兄弟中,并将其父结点中的61,也合并到一起
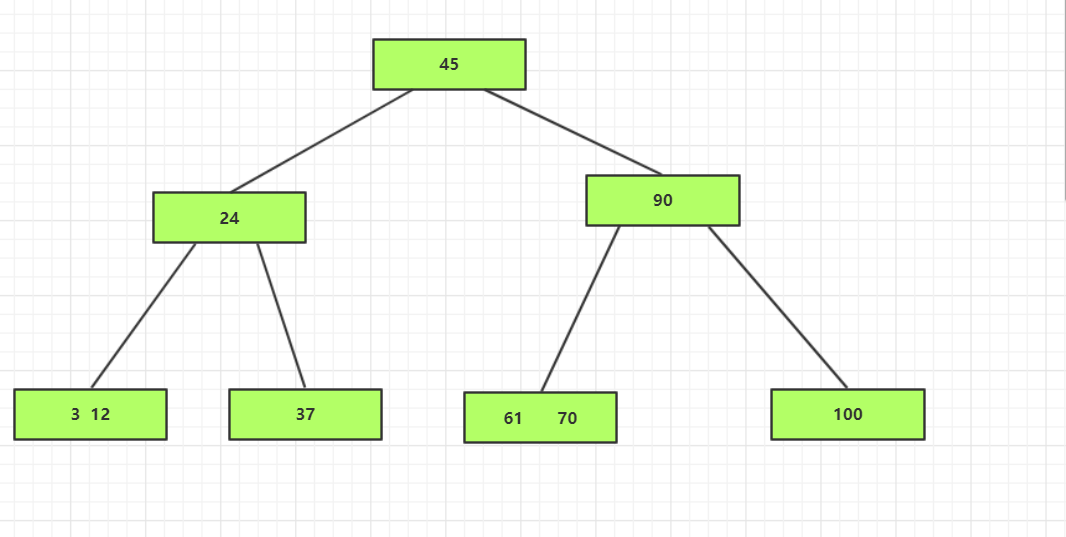
删除12和37
在上图中删除12后,其兄弟中就只含有一个节点,这时再做删除37的操作时,就会将其父亲节点中
24一其合并到其兄弟节点中,由于在其父结点中为空,所以将其其兄弟节点45一起合并到其父亲节
点中

散列查找
哈希表
基本定义
哈希表又称散列表,是除顺序表存储结构、链接表存储结构和索引表存储结构之外的又一种存储线性
表的存储结构
它的基本思路就是设要存储的元素个数为n,长为m(m>=n)的连续内存单元,以关键字为自变量,通
过哈希函数映射到内存单元的地址,把该元素存储在这个内存单元中
哈希冲突
当两个关键字不同时,但哈希地址相同,这时称为哈希冲突,把这两个元素称为同义词。
哈希函数的构造
1. 直接地址法,以关键字本身或者关键字加上某个数C作为哈希地址,则哈希函数为h(k)=k+c
2.除留余数法,用关键字k除以某个整数p,且p小于等于哈希表长度,所得的余数作为哈希地址,
哈希函数为h(k)=k mod p (p<=m),这个方法容易出现哈希冲突。
建哈希表
哈希表的结构体
#define NULLKEY -1
#define DELKEY -2
typedef int KeyType;
typedef struct
{
KeyType key; //关键字域
int count; //探测次数域
}HashTable; //哈希表单位类型
哈希表的建表
void CreatHT(HashTable ha,int &n,int m,int p,KeyType keys[],int nl)
{
for(int i=0;i<m;i++
{
ha[i].key=NULLKEY;
ha[i].count=0;
}
n=0;
for(i=0;i<nl;i++)
InsertHT(ha,p,keys[i],int &n);
}
哈希表的插入
int InsertHT(HashTable ha,int p,int k,int &n)
{
int adr,i;
adr=k % p;
if(adr==NULLKEY || adr==DELKEY) //地址为空,可插入数据
{
ha[adr].key=k;ha[adr].count=1;
}
else
{
i=1;
while(ha[adr].key!=NULLKEY && ha[adr].key!=DELKEY)
{
adr=(adr+1) % m;
i++;
}//查找插入位置
ha[adr].key=k;ha[adr].count=i; //找到插入位置
}
n++;
}
哈希查找性能与三个因素有关
1.装填因子,即哈希表中的元素个数n与长度m的比值,装填因子越小,冲突的可能性越小
2.所采用的哈希函数
3.解决哈希冲突的方法
哈希冲突的解决方法
哈希冲突的解决方法主要有开发地址法和拉链法:
开发地址法就是当出现哈希冲突时,在哈希表中再找一个新的空位置存放元素,这个方法又分为线性
探测法和平方探测法,线性探测法是在发生冲突的地址开始,依次探测下一个地址,直到出现一个
空位置为止
拉链法是把同义词用单链表下形式链接起来
用拉链法来建哈希表
拉链法结构体
typedef struct node
{
KeyType key; //关键字域
struct node*next; //下一个结点指针
}NodeType; //单链表结点类型
typedef struct
{
NodeType *firstp; //首结点指针
}HashTable; //哈希表单元类型
创建结构体
void CreatHT(HashTable ha[],int &n,int m,int p,KeyType keys[],int nl)
{
for(int i=0;i<m;i++)
{ //哈希表置初值
ha[i].firstp=NULL;
}
n=0;
for(i=0;i<nl;i++)
{
InsertHT(ha,n,p,keys[i]); //插入n个关键字
}
}
哈希表的插入
void InsertHT(HashTable ha[],int &n,int p,KeyType k) //将关键字k插入到哈希表中
{
int adr;
adr=k%p; //计算哈希函数值
NodeType *q;
q=new NodeType;
q->key=k; //创建一个结点q,存放关键字k
q->next=NULL;
if(ha[adr].firstp==NULL)
{
ha[adr].firstp=q;
}
else //若单链表adr不为空
{
q->next=ha[adr].firstp; //采用头插法插入到ha[adr]的单链表中
ha[adr].firstp=q;
}
n++; //哈希表中结点的总个数增1
}
对于下面关键字集合{25,10,8,27,32,68},散性标的长度为8,散性函数H(k)=k mod 7
线性探测法:
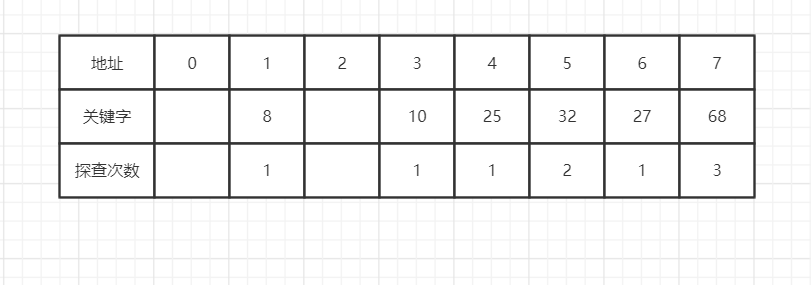
成功ASL=(1*4+2+3)/6=1.5
不成功ASL=(1+2+1+6+5+4+3)/7=3.1
链地址法

成功ASL=(15+21)/6=1.17
不成功ASL=(1+1+2+1+1)/7=0.61
2.PTA题目介绍
题目1
是否完全二叉搜索树
该题的设计思路
基本思路就是给你一组数据,让你建一棵二叉搜索树,然后判断是否是完全二叉搜索树
然后就是建好树之后就层次遍历,当遍历到空结点的时候,赋值为-1给一个数组,其他结点的数据
原样赋给一个数组,最后遍历数组,看是否有在出现小于0后又出现大于0的情况,若有,则输出
NO,否则输出YES
该题的设计思路
int main()
{
数组存储输入的n个元素
创建二叉搜索树
if 该树为完全二叉树
{
cout<<"YES"<<endl;
}
else
输出层序遍历的结果
cout<<"NO"<<endl;
}
void Print(BSTree &T,int n)//层序遍历输出结点
{
将根结点放入队列中
while 队列不为空
{
依次取出队头结点并加入该结点的左右子树结点
}
end
}
void Insert(BSTree &T,int e)
{
if 初始树为空时
建立新结点并进行赋值和左右子树初始化
else if 键值大的插入左子树
{
InsertBST(T->Left,e);
}
else if 键值小的插入右子树
{
InsertBST(T->Right,e);
}
}
bool Judge(BSTree &T,int n)//判断是否为完全二叉树
{
if 树为空
返回true
else
用队列层序遍历记录访问的结点个数
if 遍历记录的结点数等于树的总结点数n
返回true
else
返回false;
}
代码
int main()
{
int N;
cin >> N;
int b[100];
for (int i = 0; i < N; i++)
{
cin >> b[i];
}
BSTree Tree;
Tree = NULL;
Create(b, N);
if (Judge(Tree, N) == true)
{
Print(Tree, N);
cout << "YES" << endl;
}
else
{
Print(Tree, N);
cout << "NO" << endl;
}
}
BSTNode* Create(int a[], int n)
{
BSTNode* bt = NULL;
int i = 0;
while (i < n)
{
Insert(bt, a[i]);
i++;
}
return bt;
}
void Insert(BSTree& bt, int e)
{
if (bt == NULL)
{
bt = new BSTNode;
bt->data = e;
bt->lchild = NULL;
bt->rchild = NULL;
}
else if (e < bt->data)
{
return Insert(bt->rchild, e);
}
else
{
return Insert(bt->lchild, e);
}
}
bool Judge(BSTree& T, int n)
{
queue<BSTree> q;
if (T == NULL)
return true;
int j = 0;
BSTree t;
q.push(T);
while ((t = q.front()) != NULL)
{
q.push(t->lchild); q.push(t->rchild);
q.pop();
j++;
}
if (j == n)
return true;
return false;
}
void Print(BSTree& T, int n)
{
int i = 0, a[100];
queue<BSTree> q;
BSTree bt;
q.push(T);
while (!q.empty())
{
bt = q.front();
a[i++] = bt->data;
if (bt->lchild != NULL)
{
q.push(bt->lchild);
}
if (bt->rchild != NULL)
{
q.push(bt->rchild);
}
q.pop();
}
cout << a[0];
for (int j = 1; j < n; j++)
{
cout << " " << a[j];
}
cout << endl;
}
提交列表
·在判断是否完全二叉树的过程中当遇到空结点就停止
·层次遍历时,设计while遍历循环,在层序遍历中遇到NULL即退出遍历循环
·对新结点左右子树的初始化操作,防止插入元素的部分函数将左子树的调用大小改掉
知识点
·主要是二叉搜索树的应用
·完全二叉树的性质:
·满二叉树是一棵特殊的完全二叉树,但完全二叉树不一定是满二叉树
·在满二叉树中最下一层,连续删除若干个节点得到完全二叉树
·在完全二叉树中,若某个节点没有左子树,则一定没有有子树
·判断一棵树是否为完全二叉树
·若当前访问节点左孩子为空,右孩子不为空,则该树不是完全二叉树
·若当前访问节点左孩子不为空,右孩子为空;或者其左右孩子都为空,且该节点之后的队列中的节
点都是叶子节点,则该树为完全二叉树
题目2
(哈希链) 航空公司VIP客户查询
该题的设计思路
定义容器map
main()
{
cher IdNumber,long long distance;
for循环输入航班信息
if(里程<最小里程)distance赋值为最小里程k
if(未找到该身份证)//第一次坐飞机
将distance作为idNumber的value
else//第二次乘坐
对应idNumber的value加上distance
else
for循环读入身份证信息
if(为找到该身份证)
输出“No Info”
else
输出对应idNumber下的value
代码
#include<iostream>
#include<string>
#include<stdio.h>
#include<map>
using namespace std;
map<string, long long>s;
int main()
{
int n, i, k;
//string idNumber;
char idNumber[20];
long long distance;
scanf("%d %d", &n, & k);
for (i = 0; i < n; i++)
{
scanf("%s %11d", &idNumber, &distance);
if (distance < k)
{
distance = k;
}
if (s.find(idNumber) == s.end())
{
s[idNumber] = distance;
}
else;
{
s[idNumber] += distance;
}
}
int m;
scanf("%d", &m);
for (i = 0; i < m; i++)
{
scanf("%s", &idNumber);
if (s.find(idNumber) == s.end())
{
printf("No Info\n");
}
else
{
printf("%l1d\n", s[idNumber]);
}
}
return 0;
}
提交列表

·在定义IdNumber时要用char的类型才可以运行
·在改为long long的类型还有错误
·输出是要用printf()函数,不能用cout函数
·运行超时,再次调用find函数
用的知识点
·map 的应用
·注意输入最好用 scanf、printf,要比 cin,cout 更快
·哈希链的创建,采用头插法。
·scanf,printf运行效率比cout,cin低。
题目3
QQ帐户的申请与登陆
该题的设计思路
int main()
{
定义字符串 a, b, c;
int n;
输入 n;
while (n--)
{
输入a,b,c;
if a == "N" //注册
{
if (mp.find(b) == mp.end())//申请成功
{
mp[b] = c;
输出New: OK
}
else 输出ERROR: Exist
}
else
{
if mp.find(b) == mp.end() //账号找不到
{
输出ERROR: Not Exist
}
else if mp[b] != c //密码错误
{
输出ERROR: Wrong PW
}
else
{
输出Login: OK
}
}
}
}
该题的代码
#include<stdio.h>
#include<iostream>
#include<cstdlib>
#include<map>
using namespace std;
map<string, string>mp;
int main()
{
string a, b, c;
int n;
cin >> n;
while (n--)
{
cin >> a >> b >> c;
if (a == "N")
{
if (mp.find(b) == mp.end())
{
mp[b] = c;
cout << "New: OK" << endl;
}
else
{
cout << "ERROR: Exist" << endl;
}
}
else
{
if (mp.find(b) == mp.end())
{
cout << "ERROR: Not Exist" << endl;
}
else if (mp[b] != c)
{
cout << "ERROR: Wrong PW" << endl;
}
else
{
cout << "Login: OK" << endl;
}
}
}
}
提交列表

·运用map容器,处理字符和密码对应的问题,通过下标操作符获取元素,然后给获取的元素赋值,
看其是否对应
将mp[b] = c写成了了c=mp[b]导致mp中没有数据,测试点ERROR: Not Exist这个测试点无法通过
知识点
·借用map来判断
·用find()函数来查找一个元素
·用end()函数返回指向map末端的迭代器
·find()用于定位数据出现位置,当数据出现时返回数据所在位置的迭代器,若map中没有要查找的
数据,则它返回的迭代器等于end()返回的迭代器

 浙公网安备 33010602011771号
浙公网安备 33010602011771号