
numpy科学计算库
科普
很多编程语言对数字精确度不是很敏感 python亦是如此
但是python与可以做人工智能 机器学习 量化交易 数据分析等高精确度的工作
内部其实就是通过相应的模块来实现
主体:数据分析三剑客之numpy科学计算库
numpy简介
1.Numpy是高性能科学计算和数据分析的基础包
2.也是pandas等其他数据分析的工具的基础
3.Numpy具有多维数组功能,运算更加高效快速
下载模块
在notebook中如果需要执行pip命令下载模块
只需要在命令额开头加上一个感叹号即可
!pip3 install numpy
在安装anaconda之后该软件也会给我们提供一个下载模块的工具 conda使用方式与pip一致 conda install numpy 导入模块 import numpy import numpy as np # 更加倾向于起别名 np
numpy前戏
notebook单元格左侧如果是星号表示当前单元格正在执行 是数字表示执行完毕
# 身高 height = [170,173,178,180,183] # 体重 weight = [76,65,70,77,75] '''求BMI指数:身体质量指数=体重(KG)/身高(m)的平方''' BMI = weight/(height/100)**2 # 理想完美 现实报错
eg:
import random # 伪造数据 h = [] w = [] for i in range(100000000): h.append(random.randint(153,180)) w.append(random.uniform(51,88))
纯python代码实现
import time start_time = time.time() for i in range(100000000): w[i]/(h[i]/100)**2 end_time = time.time() - start_time end_time
numpy解决方案
import numpy as np H = np.array(h) W = np.array(w) start_time = time.time() BMI = W/(H/100)**2 end_time = time.time() - start_time end_time
多维数组
numpy中同一个数组内所有数据类型肯定是一致的
np.array([1,2,False])>>> array([1,2,0])
np.array([1,2,3.1])>>>array([1.,2.,3.1])
numpy中进行数据操作的时候同一个数组所有的数据都会对应参与
a1 = np.array([1,2,3,4])
a2 = np.array([7,8,9,1])
a1 + a2 >>> array([ 8, 10, 12, 5])
a1 * 10 >>> array([10, 20, 30, 40])
数组类型
一维数组 eg:([1,2,3,4])
二维数组 eg:np.array([[1,2,3,4],[9,8,7,6]])
三维数组 不常用
numpy之数据类型
布尔型 bool_ 整型 int_ int8 int16 int32 int64 无符号整型 uint8 uint16 uint32 uint64 浮点型 float_ float16 float32 float64 复数型 complex_ complex64 complex128 # 1.为什么numpy数据类型以数字居多 因为numpy主要用于科学计算 只有数字可以参与计算 # 2.为什么有些数据类型后面加下划线 因为为了跟python数据类型关键字区分开
numpy之常用属性
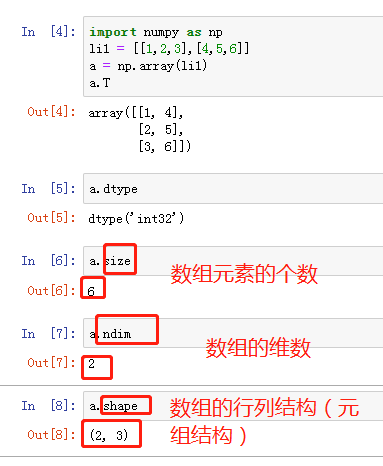
T 数组的转置(只有高维数组才会考虑)
eg: li1 = [ [1,2,3], [4,5,6] ] a = np.array(li1) a.T 执行结果: array([[1, 4], [2, 5], [3, 6]]) # 就相当于是将行变成列,列变成行,它也是一个比较常用的方法

dtype 数组元素的数据类型
size 数组元素的个数
ndim 数组的维数
shape 数组的维度大小(以元组形式)
numpy之常用方法
如何查看某个方法的使用方法
方式一:在方法后面跟上?执行即可
方式二:写完方法名后先按shift不松开然后按tab即可
1.
array() # 将列表转换为数组,可选择显示指定的dtype
2.
arange() # range的numpy版 支持浮点数 np.arange(1,10,2) np.arange(1.2,10,0.4)
3.
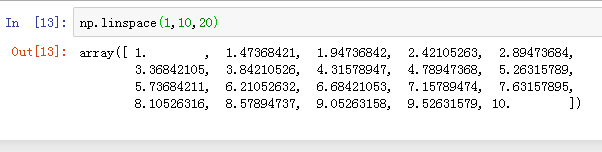
linspace() 类似arange() 第三个参数为数组长度 np.linspace(1,10,20) # 这个方法与arange有一些区别,arange是顾头不顾尾,而这个方法是顾头又顾尾,在1到10之间生成20个数字之间的距离相等的,前后两个数做减法肯定相等
4.
zeros() 根据指定形状和dtype创建全0数组
np.zeros((3,4))
5.
ones() 根据指定形状和dtype创建全1数组
np.ones((3,4))
6.
empty() 根据指定形状和dtype创建空数组(随机值)
np.empty(10)
7.
eye() 根据指定边长和dtype创建单位矩阵
np.eye(5)
numpy之索引与切片
1.针对一维数组 索引与切片操作跟python中的列表完全一致 2.花式索引(间断索引) age[[0,2,5]] 3.布尔值索引(逻辑索引) age[age>15] 4.针对二维数组索引与切片有些许复杂 res[行索引(切片),列索引(切片)] 如果需要获取二维数组的所有行或列元素,那么,对应的行索引或列索引需要用英文 状态的冒号表示 array([[ 1, 3, 5, 7], [ 2, 4, 6, 8], [ 11, 13, 15, 17], [ 12, 14, 16, 18], [100, 101, 102, 103]]) arr1[3,3] # 18 arr1[3,:] # array([12, 14, 16, 18]) arr1[:,1] # array([ 3, 4, 13, 14, 101]) arr1[0:2,1:3] # array([[3,5],[4,6]])
numpy之数学运算符
+ 数组对应元素的加和
- 数组对应元素的差
* 数组对应元素的积
/ 数组对应元素的商
% 数组对应元素商的余数
// 数组对应元素商的整除数
** 数组对应元素的幂指数
numpy之比较运算符
>
等价np.greater(arr1,arr2)
判断arr1的元素是否大于arr2的元素
>=
等价np.greater_equal(arr1,arr2)
判断arr1的元素是否大于等于arr2的元素
<
等价np.less(arr1,arr2)
判断arr1的元素是否小于arr2的元素
<=
等价np.less_equal(arr1,arr2)
判断arr1的元素是否小于等于arr2的元素
==
等价np.equal(arr1,arr2)
判断arr1的元素是否等于arr2的元素
!=
等价np.not_equal(arr1,arr2)
判断arr1的元素是否不等于arr2的元素
函数
# 常用的数学函数(了解) np.round(arr) 对各元素四舍五入 np.sqrt(arr) 计算各元素的算术平方根 np.square(arr) 计算各元素的平方值 np.exp(arr) 计算以e为底的指数 np.power(arr, α) 计算各元素的指数 np.log2(arr) 计算以2为底各元素的对数 np.log10(arr) 计算以10为底各元素的对数 np.log(arr) 计算以e为底各元素的对数
需要掌握
# 常用的统计函数(必会) np.min(arr,axis) 按照轴的方向计算最小值 np.max(arr,axis) 按照轴的方向计算最大值 np.mean(arr,axis) 按照轴的方向计算平均值 np.median(arr,axis ) 按照轴的方向计算中位数 np.sum(arr,axis) 按照轴的方向计算和 np.std(arr,axis) 按照轴的方向计算标准差 np.var(arr,axis) 按照轴的方向计算方差
注意!!! axis=0时,计算数组各列的统计值
axis=1时,计算数组各行的统计值
eg:
array([[ 80.5, 60., 40.1, 20., 90.7], [ 10.5, 30., 50.4, 70.3, 90.], [ 35.2, 35., 39.8, 39., 31.], [91.2, 83.4, 85.6, 67.8, 99.]])
不使用axis参数的前提下
计算每一行的和:
Sum = [] for row in range(4): Sum.append(np.sum(arr2[row,:]))
计算每一列的平均
Avg = [] for col in range(5): Avg.append(np.mean(arr2[:,col]))
使用axis参数时会简单很多:
arr2.sum(axis = 1) # 等价np.sum(arr2, axis = 1) np.mean(arr2, axis = 0) # 等价arr2.mean(axis = 0)
随机数
numpy中的random子模块
np.random
rand 给定形状产生随机数组(0到1之间的数)
randint 给定形状产生随机整数
choice 给定形状产生随机选择
shuffle 与random.shuffle相同
uniform 给定形状产生随机数组(随机均匀分布)
normal 随机正态分布

 浙公网安备 33010602011771号
浙公网安备 33010602011771号