
Openpyxl模块知识
Openpyxl模块知识
多页爬取梨视频代码


import requests from bs4 import BeautifulSoup import os import time if not os.path.exists(r'梨视频数据'): os.mkdir(r'梨视频数据') def get_video(n): # 1.先朝一个固定的url发送请求 获取到只有html标签的页面 重点描述分析过程 res = requests.get('https://www.pearvideo.com/category_loading.jsp?reqType=5&categoryId=31&start=%s' % n) # 2.解析页面数据获取到详情页的链接地址 soup = BeautifulSoup(res.text, 'lxml') # 3.研究视频详情链接 li_list = soup.select('li.categoryem') # 4.循环获取每个li里面的a标签 for li in li_list: a_tag = li.find(name='a') a_href_link = a_tag.get('href') # video_1742158 '''研究发现详情页视频数据并不是直接加载的 也就意味着朝上述地址发送get请求没有丝毫作用''' """ video_1742158 内部动态请求的地址 https://www.pearvideo.com/videoStatus.jsp?contId=1742158&mrd=0.9094028515390931 contId: 1742158 mrd: 0.9094028515390931 0到1之间的随机小数 动态请求之后返回的核心数据 https://video.pearvideo.com/mp4/adshort/20210920/1632283823415-15771122_adpkg-ad_hd.mp4 真实视频地址 https://video.pearvideo.com/mp4/adshort/20210920/cont-1742158-15771122_adpkg-ad_hd.mp4 """ # 通过研究发现详情页数据是动态加载的 所以通过network获取到地址 video_id = a_href_link.split('_')[-1] # 防盗链 headers = { "Referer": "https://www.pearvideo.com/video_%s" % video_id } res1 = requests.get('https://www.pearvideo.com/videoStatus.jsp', params={'contId': video_id}, headers=headers ) data_dict = res1.json() src_url = data_dict['videoInfo']['videos']['srcUrl'] systemTime = data_dict['systemTime'] # https://video.pearvideo.com/mp4/adshort/20210920/1632285084621-15771122_adpkg-ad_hd.mp4 '''如何替换核心数据 通过研究发现systemTime是关键''' real_url = src_url.replace(systemTime, 'cont-%s' % video_id) res2 = requests.get(real_url) file_path = os.path.join(r'梨视频数据', '%s.mp4' % video_id) with open(file_path, 'wb') as f: f.write(res2.content) time.sleep(0.5) for n in range(12, 48, 12): get_video(n)
1.execl文件的后缀名针对版本的不同是不同的 03版本之前:.xls 03版本之后:.xlsx 2.在python能够操作excel表格的模块有很多 openpyxl模块 最近几年比较流行的模块 该模块可以操作03版本的之后的文件 针对03版本之前的兼容性可能不太好 xlrd、wlwt模块 xlrd控制读文件 wlwt控制写文件 该模块可以操作任何版本的excel文件 3.excel本质并不是一个文件 修改excel文件后缀名至.zip即可查看 下载openpyxl pip3 install openpyxl
from openpyxl import Workbook
1.创建一个对象
wb = Workbook()
2.创建多个工作簿
wb1 = wb.create_sheet('学生表') wb2 = wb.create_sheet('课程表')

3.还可以指定工作簿的顺序
w3 = wb.create_sheet('老师表',0)
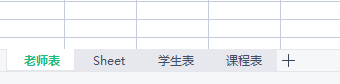
4.create_sheet方法会返回当前被创建的工作簿对象
w3.title = '教师表' # 工作簿名称支持二次修改 w3.sheet_properties.tabColor = '1072BA' # 修改工作簿名称样式 print(wb.sheetnames) # 查看当前excel文件所有的工作簿名称
5.保存文件
wb.save(r'1.xlsx')
from openpyxl import Workbook wb = Workbook() wb1 = wb.create_sheet('数据统计',0)
写入数据方式1
wb1['A1'] = 111 wb1['A2'] = 222
写入数据方式2
wb1.cell(colum=1,row=3,value=333) cell表示的是单元格的意思
写入数据方式3
wb1.append(['序号','姓名','年龄','性别']) wb1.append([1,'looper',18,'male']) wb1.append([2,'perkz',28,'male']) wb1.append([3,'faker',38,'male']) wb1.append([4,'caps',28,'male'])
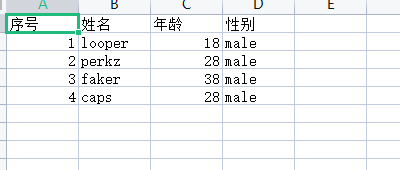
append是按照行数一行行录入数据
写入计算公式
wb1["A9"] = 'sum(A2:A8)'
wb.save(r'2.xlsx')
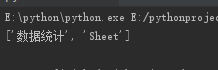
print(wb1['B2'].value) # 获取普通数据 print(wb1['A9'].value) # 获取公式 =SUM(A2:A8) # 如果在读取数据的时候不想获取公式本身而是公式的结果需要指定 data_only参数 wb = load_workbook(r'2.xlsx',data_only=True)
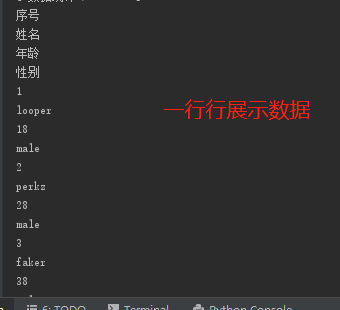
print(wb1.cell(row=3,column=2).value) for row in wb1.rows: for r in row: print(r.value) for col in wb1.columns: for c in col: print(c.value) # 获取最大的行数和列数 print(wb1.max_row) print(wb1.max_column)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号