

批量操作数据、自定义分页器、form组件、modelform组件
批量操作数据、自定义分页器、form组件、modelform组件
一、批量操作数据
项目需求:浏览器访问django后端某一条url,实时朝数据库中生成一万条数据并将生成的数据查询出来,并展示到前端页面。
urls.py:
from django.urls import path
from app01 import views
urlpatterns = [
path('index/', views.index)
]
models.py:
from django.db import models
# Create your models here.
class Books(models.Model):
title = models.CharField(max_length=32, verbose_name='书籍')
views.py:
from django.shortcuts import render
from app01 import models
# Create your views here.
def index(request):
# for循环插入100000条数据
for i in range(100000):
models.Books.objects.create(title=f'第{i}本书')
"""上述四行可简写成一行>>>:列表生成式"""
# [models.Books(title=f'第{i}本书') for i in range(1000)]
# 查询插入的数据
book_query = models.Books.objects.all()
# 查询出的数据传递给html页面
return render(request, 'bookList.html', locals())
index.html:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Title</title>
<script src="https://cdn.bootcdn.net/ajax/libs/jquery/3.6.0/jquery.js"></script>
{% load static %}
<link rel="stylesheet" href="{% static 'bootstrap-3.4.1-dist/css/bootstrap.min.css' %}">
</head>
<body>
<div class="container">
<div class="col-md-8 col-md-offset-2">
{% for book_obj in book_query %}
<p>{{ book_obj.title }}</p>
{% endfor %}
</div>
</div>
</body>
</html>
启动django项目后,浏览器访问http://127.0.0.1:8000/index/,会发现有个明显的卡顿,不是网速问题,后端在停的操作数据库,耗时长,当等待一段时间后,才会发现产生了数据。(使用django自带的sqlite3数据库会报错,因为sqlite3数据库是小型数据库。产生太多数据,数据库会罢工。)
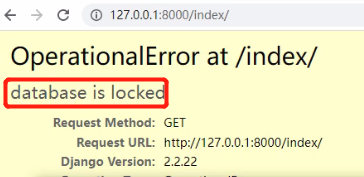
bulk_create方法
重启django项目,数据立马增加,速度非常快。
bulk_create方法是django orm特地提供给我们的方便批量操作数据库的方式,效率非常高!!!
from django.shortcuts import render
from app01 import models
# Create your views here.
def index(request):
book_list = []
for i in range(1000):
book_obj = models.Books(title=f'第{i}本书')
book_list.append(book_obj)
"""上述四行可简写成一行>>>:列表生成式"""
# [models.Books(title=f'第{i}本书') for i in range(1000)]
models.Books.objects.bulk_create(book_list) # 批量创建数据
models.Books.objects.bulk_update()
book_query = models.Books.objects.all()
return render(request, 'bookList.html', locals())
补充:
- bulk_cretae() >>> 批量创建数据
- bulk_update() >>> 批量修改数据
二、自定义分页器
针对数据量大但又需要全部展示给用户观看的情况下,统一做法是分页处理。
分页推导
-
get请求也是可以携带参数的,所以我们在朝后端发送查看数据的同时可以携带一个参数告诉后端我们想看第几页的数据。
-
queryset对象是支持索引取值和切片操作的,但是不支持负数索引情况。
1.QuerySet切片操作
from django.shortcuts import render
from app01 import models
# Create your views here.
def index(request):
# 1.获取前端想要展示的页面
current_page = request.GET.get('page', 1) # 获取用户指定的page,如果没有则默认展示第一页
try:
current_page = int(current_page)
except ValueError:
current_page = 1
# 2.自定义每页展示的条数
per_page_num = 10
# 3.定义出切片起始位置
start_num = (current_page - 1) * per_page_num
# 4.定义出切片终止位置
end_num = current_page * per_page_num
book_query = book_data[start_num:end_num] # QuerySet [数据对象 数据对象]
return render(request, 'bookList.html', locals())
"""
current_page、per_page_num、start_page、end_page四个参数之间的数据关系:
per_page_num = 10
current_page start_num end_time
1 0 10
2 10 20
3 20 30
per_page_num = 5
current_page start_num end_time
1 0 5
2 5 10
3 10 15
>>>>>>>>:
start_num = (current_page - 1) * per_page_num
end_num = current_page * per_page_num
"""
2.分页样式添加
<div class="container">
<div class="col-md-8 col-md-offset-2">
{% for book_obj in book_query %}
<p class="text-center">{{ book_obj.title }}</p>
{% endfor %}
<nav aria-label="Page navigation">
<ul class="pagination">
<li>
<a href="#" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
<li><a href="?page=1">1</a></li>
<li><a href="?page=2">2</a></li>
<li><a href="?page=3">3</a></li>
<li><a href="?page=4">4</a></li>
<li><a href="?page=5">5</a></li>
<li>
<a href="#" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
</ul>
</nav>
</div>
</div>
3.页码展示>>>内置方法之divmod
from django.shortcuts import render
from app01 import models
# Create your views here.
def index(request):
book_data = models.Books.objects.all()
# 计算总共的数据条数
all_count = book_data.count()
# 2.自定义每页展示的条数
per_page_num = 10
# 利用解压赋值获取总的页码页数
all_page_num, more = divmod(all_count, per_page_num)
if more:
all_page_num += 1
# 1.获取前端想要展示的页面
current_page = request.GET.get('page', 1) # 获取用户指定的page,如果没有则默认展示第一页
try:
current_page = int(current_page)
except ValueError:
current_page = 1
# 后端提前生成页码标签
html_page = ''
a = current_page
# 如果当前页数小于6则将当前页数固定为第六页,因为queryset对象不支持负索引
if current_page < 6:
a = 6
for i in range(current_page - 5, current_page + 6):
# 将当前点击的页数设置选中状态
if current_page == i:
# 其阿奴单模板语法不支持range但是后端支持,可以在后端创建好html标签然后传递给html页面使用
html_page += f'<li class="active"><a href="?page={i}">{i}</a></li>'
else:
html_page += f'<li class="active"><a href="?page={i}">{i}</a></li>'
# 3.定义出切片起始位置
start_num = (current_page - 1) * per_page_num
# 4.定义出切片终止位置
end_num = current_page * per_page_num
book_query = book_data[start_num:end_num] # QuerySet [数据对象 数据对象]
return render(request, 'bookList.html', locals())
小结
1.QuerySet切片操作
book_query = book_data[start_num:end_num] # QuerySet [数据对象 数据对象]
2.分页样式添加
<nav aria-label="Page navigation">
<ul class="pagination">
<li>
<a href="#" aria-label="Previous">
<span aria-hidden="true">«</span>
</a>
</li>
<li><a href="?page=1">1</a></li>
<li><a href="?page=2">2</a></li>
<li><a href="?page=3">3</a></li>
<li><a href="?page=4">4</a></li>
<li><a href="?page=5">5</a></li>
<li>
<a href="#" aria-label="Next">
<span aria-hidden="true">»</span>
</a>
</li>
</ul>
</nav>
3,页码展示
如何根据总数据和每页展示的数据得出总页码:divmod()
# 自定义每页展示的条数
per_page_num = 10
all_page_num, more = divmod(all_count, per_page_num)
if more:
all_page_num += 1
4.如何渲染出所有页面标签
前端模板语法不支持range,但是后端支持,可在后端创建好html标签传递给html页面使用
# 后端提前生成页码标签
html_page = ''
a = current_page
if current_page < 6:
a = 6
for i in range(a - 5, a + 6):
if current_page == i:
html_page += f'<li class="active"><a href="?page={i}">{i}</a></li>'
else:
html_page += f'<li><a href="?page={i}">{i}</a></li>'
# 前端使用
</li>
{{ html_page|safe }}
<li>
5.如何限制住展示页面标签个数
页码推荐使用奇数位(对称美),利用当前页前后固定位数来限制
a = current_page
for i in range(a - 5, a + 6):
pass
6.首尾页码展示范围问题
a = current_page
if current_page < 6:
a = 6
自定义分页器封装代码
class Pagination(object):
def __init__(self, current_page, all_count, per_page_num=10, pager_count=11):
"""
封装分页相关数据
:param current_page: 当前页
:param all_count: 数据库中的数据总条数
:param per_page_num: 每页显示的数据条数
:param pager_count: 最多显示的页码个数
"""
try:
current_page = int(current_page)
except Exception as e:
current_page = 1
if current_page < 1:
current_page = 1
self.current_page = current_page
self.all_count = all_count
self.per_page_num = per_page_num
# 总页码
all_pager, tmp = divmod(all_count, per_page_num)
if tmp:
all_pager += 1
self.all_pager = all_pager
self.pager_count = pager_count
self.pager_count_half = int((pager_count - 1) / 2)
@property # 将一个方法伪装成属性,不加括号也能调用
def start(self):
return (self.current_page - 1) * self.per_page_num
@property
def end(self):
return self.current_page * self.per_page_num
def page_html(self):
# 如果总页码 < 11个:
if self.all_pager <= self.pager_count:
pager_start = 1
pager_end = self.all_pager + 1
# 总页码 > 11
else:
# 当前页如果<=页面上最多显示11/2个页码
if self.current_page <= self.pager_count_half:
pager_start = 1
pager_end = self.pager_count + 1
# 当前页大于5
else:
# 页码翻到最后
if (self.current_page + self.pager_count_half) > self.all_pager:
pager_end = self.all_pager + 1
pager_start = self.all_pager - self.pager_count + 1
else:
pager_start = self.current_page - self.pager_count_half
pager_end = self.current_page + self.pager_count_half + 1
page_html_list = []
# 添加前面的nav和ul标签
page_html_list.append('''
<nav aria-label='Page navigation>'
<ul class='pagination'>
''')
first_page = '<li><a href="?page=%s">首页</a></li>' % (1)
page_html_list.append(first_page)
if self.current_page <= 1:
prev_page = '<li class="disabled"><a href="#">上一页</a></li>'
else:
prev_page = '<li><a href="?page=%s">上一页</a></li>' % (self.current_page - 1,)
page_html_list.append(prev_page)
for i in range(pager_start, pager_end):
if i == self.current_page:
temp = '<li class="active"><a href="?page=%s">%s</a></li>' % (i, i,)
else:
temp = '<li><a href="?page=%s">%s</a></li>' % (i, i,)
page_html_list.append(temp)
if self.current_page >= self.all_pager:
next_page = '<li class="disabled"><a href="#">下一页</a></li>'
else:
next_page = '<li><a href="?page=%s">下一页</a></li>' % (self.current_page + 1,)
page_html_list.append(next_page)
last_page = '<li><a href="?page=%s">尾页</a></li>' % (self.all_pager,)
page_html_list.append(last_page)
# 尾部添加标签
page_html_list.append('''
</nav>
</ul>
''')
return ''.join(page_html_list)
自定义分页器使用
后端:
def index(request):
# 自定义分页器
from app01.plugins import mypage
book_quey = models.Books.objects.all()
page_obj = mypage.Pagination(current_page=request.GET.get('page'),
all_count=book_quey.count())
page_query = book_quey[page_obj.start:page_obj.end]
return render(request, 'bookList.html', locals())
前端:
<div class="container">
<div class="col-md-8 col-md-offset-2">
{% for book_obj in page_query %}
<p class="text-center">{{ book_obj.title }}</p>
{% endfor %}
{{ page_obj.page_html|safe }}
</div>
</div>
三、form组件
1、前戏
编写用户登录功能并且校验数据返回提示信息(form表单)
'''后端通过字典给前端传入数据'''
# 后端代码
def abform(request):
# 两次的字典一定要是同一个字典
data_dict = {'username':'', 'password':''}
if request.method == 'POST':
username = request.POST.get('username')
password = request.POST.get('password')
if username == 'jason':
data_dict['username'] = 'jason不可以用哦'
if password == '123':
data_dict['password'] = '123这个密码太简单了吧'
return render(request, 'abform.html', locals())
# 前端代码
<form action="" method="post">
<p>username:
<input type="text" name="username">
<span style="color: red">{{ data_dict.username }}</span>
</p>
<p>password:
<input type="text" name="password">
<span style="color: red">{{ data_dict.password }}</span>
</p>
<input type="submit">
</form>
2、form组件
1)数据校验
支持提前设置各种校验规则之后自动校验
2)渲染页面
支持直接渲染获取用户数据的各种标签
3)展示信息
支持对不同的校验失败展示不同的提示
3、form类型创建
from django import forms
class MyForm(forms.Form):
name = forms.CharField(max_length=32,min_length=3) # 用户名最长八个字符,最短是哪个字符
age = forms.IntegerField(max_value=150,min_value=0) # 年龄最小0岁,最大150岁
email = forms.EmailField() # 邮箱必须符合@
4、数据校验功能
from app01 import views
1.传递待校验的数据
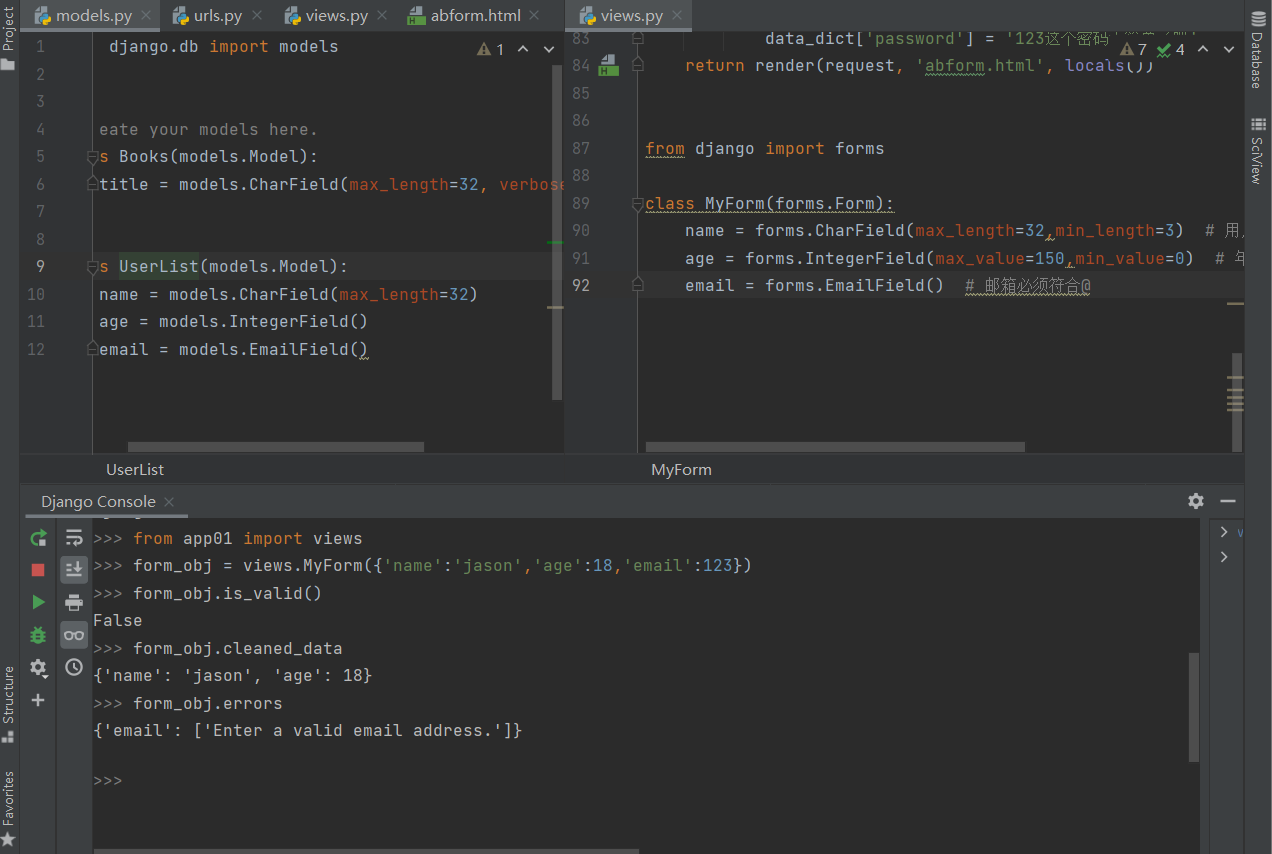
form_obj = views.MyForm({'name':'jason','age':18,'email':123})
2.判断索引的数据是否符合校验
form_obj.is_valid()
False
3.获取符合校验规则的数据
form_obj.cleaned_data
{'name': 'jason', 'age': 18}
4.查阅不符合校验规则的数据及错误原因
form_obj.errors
{'email': ['Enter a valid email address.']}
'''form类中编写的字段默认都是必填的,少穿则肯定不通过校验:is_valid()'''
form_obj = views.MyForm({'name':'jason','age':18})
form_obj.is_valid()
False
'''校验如果多传了一些字段,则不参与校验,全程忽略'''
form_obj = views.MyForm({'name':'jason','age':18,'email':'123@qq.com', 'pwd':111})
form_obj.is_valid()
True
5、渲染标签功能
{# 方式一:封装程度高,扩展性差 #}
{{ form_obj.as_p }}
{{ form_obj.as_table }}
{{ form_obj.as_ul }}
{# 方式二:封装程度低,扩展性好,编写困难 #}
{{ form_obj.name.label }}
{{ form_obj.name }}
{{ form_obj.age.label }}
{{ form_obj.age }}
{# 方式三:推荐使用 #}
{% for form in form_obj %}
<p>{{ form.label }}{{ form }}</p>
{% endfor %}
'''类中以外的所有标签都不会自动渲染,需要自己编写'''
PS:模板语法注释在前端是看不见的;而前端注释在前端是能够看见的。
6、展示提示信息
form表单取消浏览器自动添加的数据校验功能:<form action="" method="post" novalidate></form>
后端:校验输入的信息是否合法并提示中文
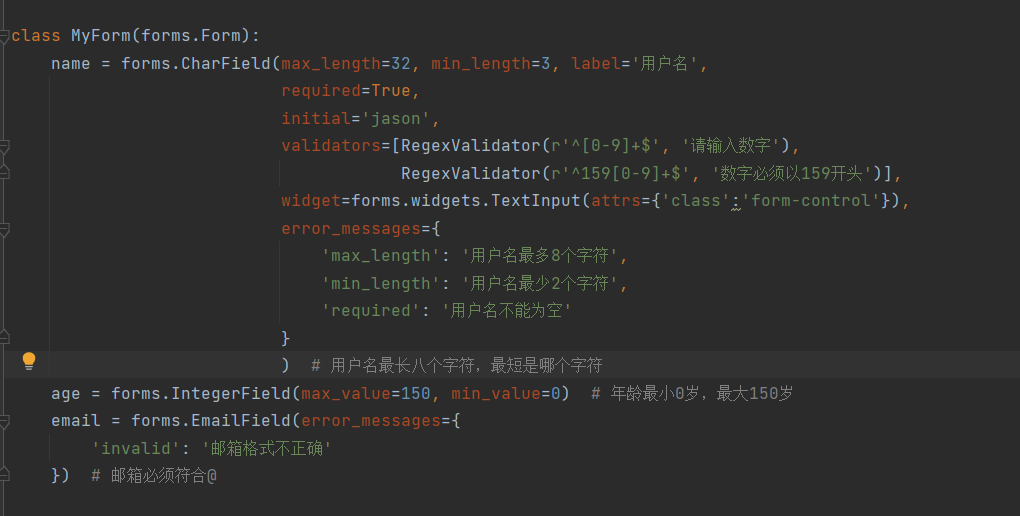
class MyForm(forms.Form):
name = forms.CharField(max_length=32, min_length=3, label='用户名',
error_messages={
'max_length': '用户名最多8个字符',
'min_length': '用户名最少2个字符',
'required': '用户名不能为空'
}) # 用户名最长八个字符,最短是哪个字符
age = forms.IntegerField(max_value=150, min_value=0) # 年龄最小0岁,最大150岁
email = forms.EmailField(error_messages={
'invalid': '邮箱格式不正确'
}) # 邮箱必须符合@
def func(request):
form_obj = MyForm()
if request.method == 'POST':
form_obj = MyForm(request.POST)
if form_obj.is_valid():
print(form_obj.cleaned_data)
else:
print(form_obj.errors)
return render(request, 'func.html', locals())
# 前端
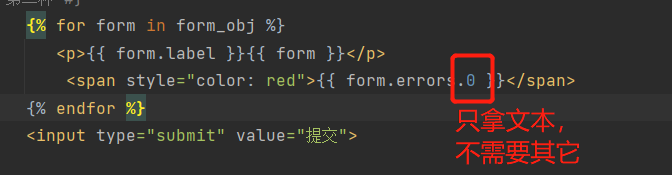
<form action="" method="post" novalidate>
{% for form in form_obj %}
<p>{{ form.label }}{{ form }}
<span style="color: red">{{ form.errors.0 }}</span>
</p>
{% endfor %}
<input type="submit" value="提交">
</form>
'''
通过添加:error_messages={},来提示校验不合法
通过settings.py文件中的:LANGUAGE_CODE = 'zh-hans' # 将底层中文作为语言环境
'''
7、重要字段参数
min_length 最小长度
max_length 最大长度
label 字段名称
error_messages 错误提示
min_value 最小值
max_value 最大值
initial 默认值
validators 正则校验器
widget 控制渲染出来的标签各项属性
choices 选择类型的标签内部对应关系
8、钩子函数之局部钩子(校验单个字段)
def clean_name(self):
name = self.cleaned_data.get('name')
res = models.UserList.objects.filter(name=name)
if res:
return self.add_error('name', '用户名已存在')
return name
# models.py
class UserList(models.Model):
name = models.CharField(max_length=32)
pwd = models.IntegerField()
age = models.IntegerField()
email = models.EmailField()
# views.py
class MyForm(forms.Form):
'''第一层校验'''
name = forms.CharField(max_length=32, min_length=3, label='用户名',) # 用户名最长八个字符,最短是哪个字符
pwd = forms.IntegerField(label='密码')
confirm_pwd = forms.IntegerField(label='确认密码')
age = forms.IntegerField() # max_value=150, min_value=0 年龄最小0岁,最大150岁
email = forms.EmailField() # error_messages={'invalid': '邮箱格式不正确'} 邮箱必须符合@
'''第二层校验'''
# 1.校验用户名是否已存在
def clean_name(self):
name = self.cleaned_data.get('name')
res = models.UserList.objects.filter(name=name)
if res:
return self.add_error('name', '用户名已存在')
return name
def func(request):
form_obj = MyForm()
if request.method == 'POST':
form_obj = MyForm(request.POST)
if form_obj.is_valid():
res = form_obj.cleaned_data
res.pop('confirm_pwd')
models.UserList.objects.create(**res)
return render(request, 'func.html', locals())
func.html
<form action="" method="post" novalidate>
{% for form in form_obj %}
<p>{{ form.label }}{{ form }}
<span style="color: red">{{ form.errors.0 }}</span>
</p>
{% endfor %}
<input type="submit" value="提交">
</form>
9、钩子函数之全局钩子(校验多个字段)
def clean(self):
pwd = self.cleaned_data.get('pwd')
confirm_pwd = self.cleaned_data.get('confirm_pwd')
if not pwd == confirm_pwd:
return self.add_error('confirm_pwd', '两次密码不一致')
return self.cleaned_data
# models.py
class UserList(models.Model):
name = models.CharField(max_length=32)
pwd = models.IntegerField()
age = models.IntegerField()
email = models.EmailField()
views.py
class MyForm(forms.Form):
'''第一层校验'''
name = forms.CharField(max_length=32, min_length=3, label='用户名', ) # 用户名最长八个字符,最短是哪个字符
pwd = forms.IntegerField(label='密码')
confirm_pwd = forms.IntegerField(label='确认密码')
age = forms.IntegerField() # max_value=150, min_value=0 年龄最小0岁,最大150岁
email = forms.EmailField() # error_messages={'invalid': '邮箱格式不正确'} 邮箱必须符合@
'''第二层校验'''
# 1.校验用户名是否已存在
def clean(self):
pwd = self.cleaned_data.get('pwd')
confirm_pwd = self.cleaned_data.get('confirm_pwd')
if not pwd == confirm_pwd:
return self.add_error('confirm_pwd', '两次密码不一致')
return self.cleaned_data
def func(request):
form_obj = MyForm()
if request.method == 'POST':
form_obj = MyForm(request.POST)
if form_obj.is_valid():
res = form_obj.cleaned_data
res.pop('confirm_pwd')
models.UserList.objects.create(**res)
return render(request, 'func.html', locals())
func.html
<form action="" method="post" novalidate>
{% for form in form_obj %}
<p>{{ form.label }}{{ form }}
<span style="color: red">{{ form.errors.0 }}</span>
</p>
{% endfor %}
<input type="submit" value="提交">
</form>
10、form组件源码分析
def register(request):
form_obj = UserForm()
if request.method == 'POST':
form_obj = UserForm(request.POST) # request.POST传给了后面__init__的第一个形参data
if form_obj.is_valid():
from app01 import models
form_obj.cleaned_data.pop('re_pwd')
models.UserInfo.objects.create(**form_obj.cleaned_data)
return render(request, 'register.html', locals())
若forms组件校验成功,那么form_obj.is_valid()返回的是True,查看is_valid().
def is_valid(self):
"""Return True if the form has no errors, or False otherwise."""
return self.is_bound and not self.errors
若要执行is_valid函数则self.is_bound必须是True而且self.errors必须是False
class BaseForm:
def __init__(self, data=None, files=None, ...): # data就是request.POST
self.is_bound = data is not None or files is not None # True
form_obj = UserForm(request.POST) # 实例化对象,request.POST传给了后面__init__的第一个形参data
class UserForm(forms.Form): #继承了Form类
pass
class Form(BaseForm, metaclass=DeclarativeFieldsMetaclass): # 又继承了BaseForm 元类是产生类的类
pass
class BaseForm(RenderableFormMixin):
def __init__(
self,
data=None, # data=request.POST Query_set类型
files=None,
pass
data肯定不为空,那么self.is_bound是True
@property
def errors(self):
"""Return an ErrorDict for the data provided for the form."""
if self._errors is None:
self.full_clean()
return self._errors
# self._errors默认为None 一定会走self.full_clean()
self._errors = None # Stores the errors after clean() has been called.
self._errors默认为None会走self.full_clean()
def full_clean(self):
# 校验所有的数据
"""
Clean all of self.data and populate self._errors and self.cleaned_data.
"""
# 存放错误信息
self._errors = ErrorDict() # 只要带有Dict长的就像是个字典
# self.is_bound肯定不为False,否则不走了
if not self.is_bound: # Stop further processing.
return
self.cleaned_data = {}
# If the form is permitted to be empty, and none of the form data has
# changed from the initial data, short circuit any validation.
# 判断form表单是否允许为空 并且没有数据 默认不为空 empty_permitted=False,
if self.empty_permitted and not self.has_changed():
return
# 最核心的三行代码,继承这个类之后别调用
self._clean_fields() # 字段校验和局部钩子函数校验
self._clean_form()
self._post_clean()
self._clean_fields()
def _clean_fields(self):
# self.fields即使views里面写的所有字段以及字段对象
for name, bf in self.fields.items(): # name指代所有的字段名,field指代所有的字段对象
# 这个方法拿去这个字段获取到的值
value = field.widget.value_from_datadict(self.data, self.files, self.add_prefix(name))
try:
if isinstance(field, FileField): # 判断是不是文件字段 我们没有传文件 所以不走这
value = field.clean(value, bf.initial)
else:
value = field.clean(value) # 真正的校验,拿到数据之后执行这个类里面的全局钩子
self.cleaned_data[name] = value # 没有报错就说明验证成功 将属性名和数据值放入cleaned_data中
# 局部钩子函数校验
# 判断forms组件中是否与clean_属性名这个属性
if hasattr(self, "clean_%s" % name):
# 有的话就调用这个局部钩子函数
# 并且接受一个返回值
# name就是一个个的字段名
value = getattr(self, "clean_%s" % name)()
# 钩子函数校验成功的话需要返回一个正确的数据值 需要存放到cleaned_data中
# 校验不成功的话 必须return一个None
self.cleaned_data[name] = value
# 如果钩子函数函数出错的话 就将错误信息添加到errors中
except ValidationError as e:
self.add_error(name, e)
def add_error(self, field, error):
...
if field in self.cleaned_data:
del self.cleaned_data[field]
# 1.for name, bf in self._bound_items():
def _bound_items(self):
"""Yield (name, bf) pairs, where bf is a BoundField object."""
for name in self.fields:
yield name, self[name] # 字典的键和值
self.fields = copy.deepcopy(self.base_fields)
# base_fileds就是form表单提交的数据,是字典类型
# {'name': <django.forms.fields.CharField object at 0x000001AE84ADD7C0> ...}
_clean_form()
def _clean_form(self):
try:
cleaned_data = self.clean() # 调用全局钩子函数
except ValidationError as e:
self.add_error(None, e)
else: # 如果没有报错 并且cleaned_data不为空就重新赋值
if cleaned_data is not None:
self.cleaned_data = cleaned_data
form类中的clean函数
def clean(self):
"""
Hook for doing any extra form-wide cleaning after Field.clean() has been
called on every field. Any ValidationError raised by this method will
not be associated with a particular field; it will have a special-case
association with the field named '__all__'.
"""
# 验证的所有错误将于__all__字段关联
# 直接返回了cleaned_data
return self.cleaned_data
使用全局钩子的时候需要返回一个完整的cleaned_data,否则将是一个不完整的数据。
四、modelform组件
modelform是form的优化版本,使用更简单,功能更强大
class MyModelForm(forms.ModelForm):
class Meta:
model = models.UserList
fields = '__all__'
# exclude = ('age',)
def clean_name(self):
name = self.cleaned_data.get('name')
res = models.UserList.objects.filter(name=name).first()
if res:
self.add_error('name', '用户名已存在')
return name
models.py
class MyModelForm(forms.ModelForm):
class Meta:
model = models.UserList
fields = '__all__'
# exclude = ('age',)
def clean_name(self):
name = self.cleaned_data.get('name')
res = models.UserList.objects.filter(name=name).first()
if res:
self.add_error('name', '用户名已存在')
return name
def md(request):
modelform_obj = MyModelForm()
if request.method == 'POST':
'''save()不仅有保存的功能,还有修改数据的功能'''
# edit_obj = models.UserList.objects.filter(name='jason').first()
# modelform_obj = MyModelForm(request.POST, instance=edit_obj)
modelform_obj = MyModelForm(request.POST)
if modelform_obj.is_valid():
modelform_obj.save()
return render(request, 'md.html', locals())
md.html
<form action="" method="post" novalidate>
{% for modelform in modelform_obj %}
<p>
{{ modelform.label }}{{ modelform }}
<span>{{ modelform.errors.0 }}</span>
</p>
{% endfor %}
<input type="submit">
</form>

 浙公网安备 33010602011771号
浙公网安备 33010602011771号