

用python爬取一个美女桌面网站上的所有桌面
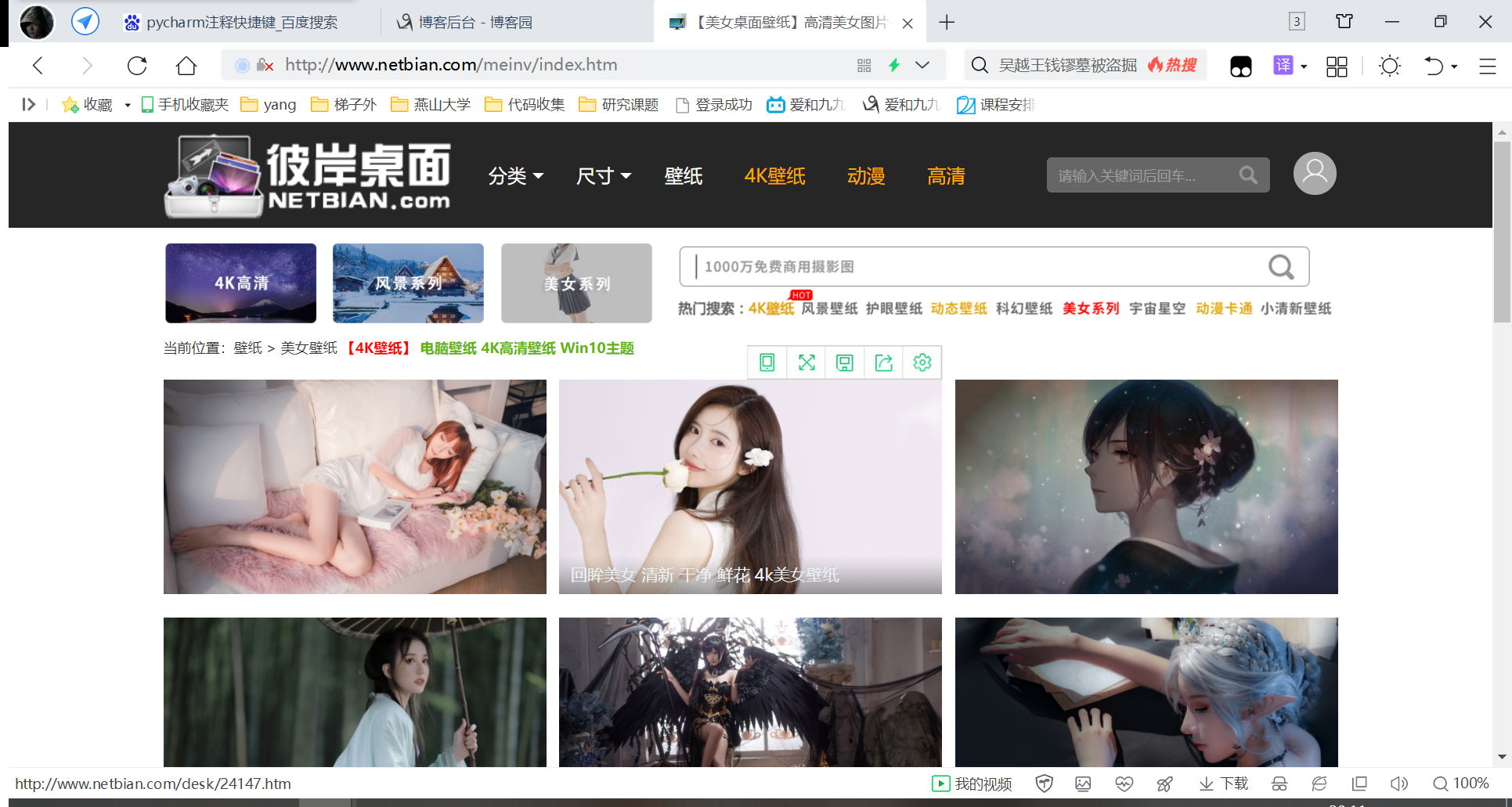
爬取的就是这个美女桌面了,只是写的有很大缺点:
第一,没有防反爬机制,因为就是练手玩玩看;
第二,没有设置for循环或者递归点击下一页的机制,也就是这个网站一旦更新,就要手动改它的末尾值,因为我懒,而且就随便玩玩。
代码如下:
1 import threading 2 import urllib 3 import requests 4 import time 5 from concurrent import futures 6 7 header = { 8 'Referer': 'http://www.netbian.com/skin/style.css', 9 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safari/537.36', 10 11 } 12 def download_img(src,filename): 13 img = requests.get(src, headers=header) # Referer img是图片,不能用字符串保存 14 with open('imgs/' + filename, 'wb') as file: 15 file.write(img.content) # img是图片响应,img.content是图片的字节,不要使用text 16 print("已爬取第", pageID, "页的", src) 17 18 for pageID in range(1,164): 19 time.sleep(0.7) 20 if(pageID==1): 21 url = 'http://www.netbian.com/meinv/index.htm' 22 else: 23 url = 'http://www.netbian.com/meinv/index'+'_'+str(pageID)+".htm" 24 25 #获取相应 26 resp=requests.get(url,headers=header) 27 #print(resp.encoding) 28 resp.encoding='gbk' 29 #print(resp.encoding) 30 #print(resp.text) 31 32 #解析响应 33 from lxml import etree 34 html=etree.HTML(resp.text) 35 srcs=html.xpath('//*[@id="main"]/div[3]/ul/li/a/img/@src') 36 #print("开始输出") 37 ex = futures.ThreadPoolExecutor(max_workers=40) 38 for src in srcs: 39 filename=src.split('/')[-1] 40 ex.submit(download_img,src,filename) 41 #print(src) 42 #print(filename) 43 #download_img(src,filename)
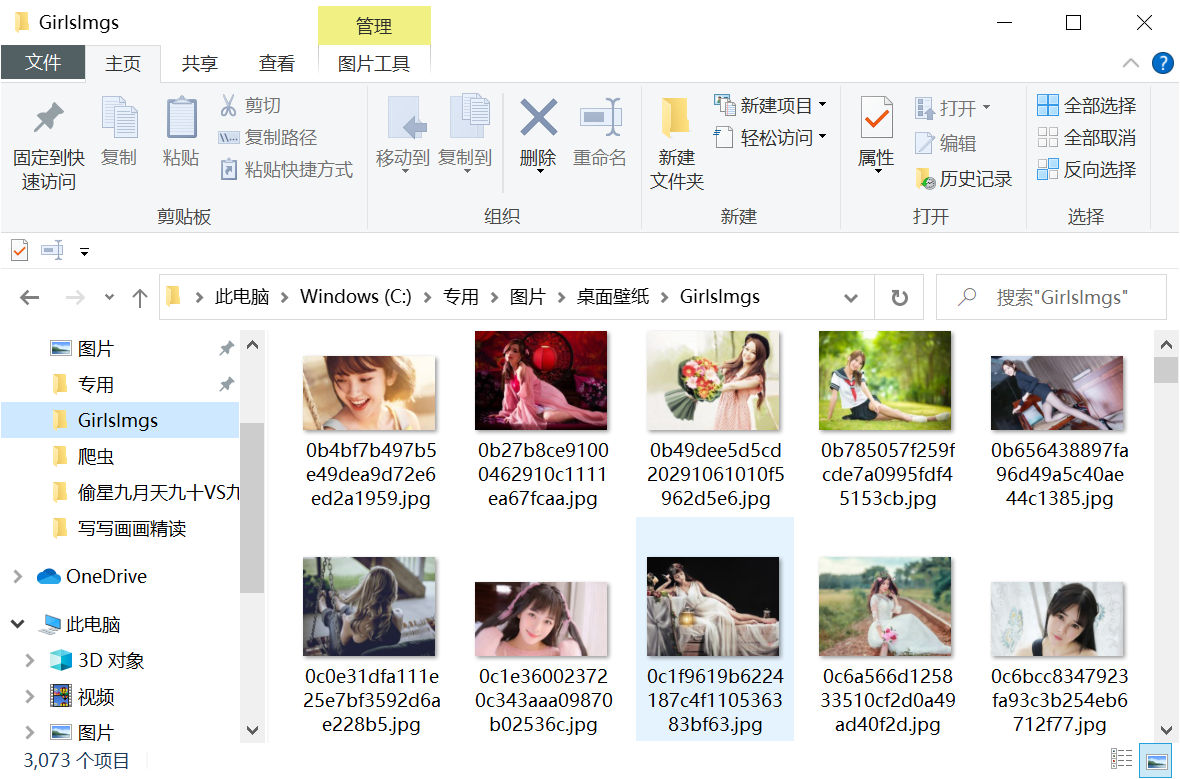
最后下载下来,你懂的,一共三千多张图:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号