
mysql覆盖索引与回表
一、什么是回表查询?
要从InnoDB的索引实现说起,InnoDB有两大类索引:聚集索引(clustered index) 普通索引(secondary index)
InnoDB聚集索引和普通索引有什么差异?
InnoDB聚集索引的叶子节点存储行记录,因此, InnoDB必须要有,且只有一个聚集索引:
(1)如果表定义PK,则PK就是聚集索引;
(2)如果表没有定义PK,则第一个not NULL unique列是聚集索引;
(3)否则,InnoDB会创建一个隐藏的row-id作为聚集索引;
画外音:所以PK查询非常快,直接定位行记录。
t(id PK, name KEY, sex, flag);
画外音:id是聚集索引,name是普通索引。
表中有四条记录:
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
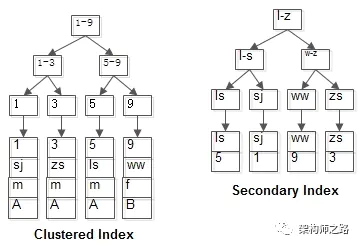
两个B+树索引分别如上图:
(1)id为PK,聚集索引,叶子节点存储行记录;
(2)name为KEY,普通索引,叶子节点存储PK值,即id;
既然从普通索引无法直接定位行记录,那普通索引的查询过程是怎么样的呢?
通常情况下,需要扫码两遍索引树。例如:
select * from t where name='lisi';
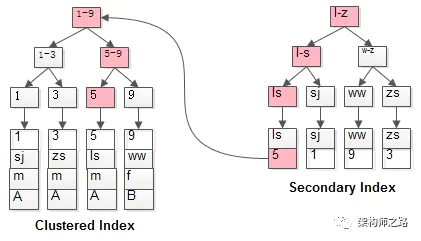
粉红色路径,需要扫码两遍索引树:
(1)先通过普通索引定位到主键值id=5;
(2)在通过聚集索引定位到行记录;
这就是所谓的回表查询,先定位主键值,再定位行记录,它的性能较扫一遍索引树更低。
索引覆盖
explain的输出结果Extra字段为Using index时,能够触发索引覆盖。
例子create table user ( id int primary key, name varchar(20), sex varchar(5), index(name) )engine=innodb;
sql语句
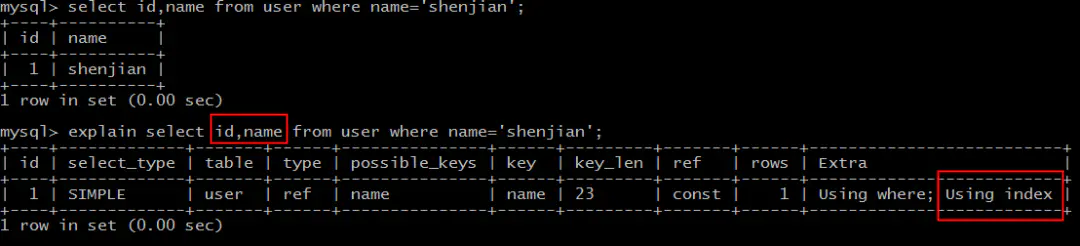
select id,name from user where name='shenjian';
能够命中name索引,索引叶子节点存储了主键id,通过name的索引树即可获取id和name,无需回表,符合索引覆盖,效率较高。
画外音,Extra:Using index。
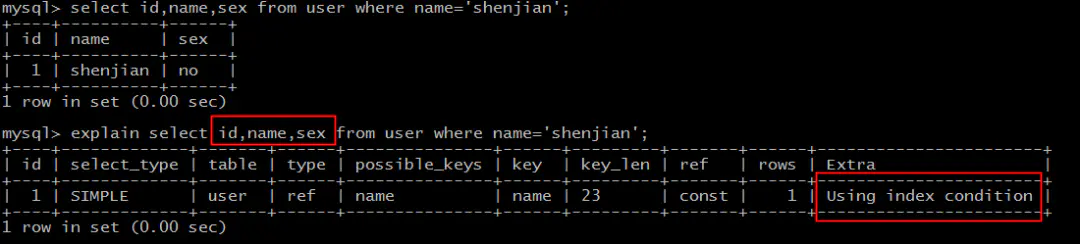
select id,name,sex* from user where name='shenjian';*
能够命中name索引,索引叶子节点存储了主键id,但sex字段必须回表查询才能获取到,不符合索引覆盖,需要再次通过id值扫码聚集索引获取sex字段,效率会降低。
画外音,Extra:Using index condition。
1.无WHERE条件的查询优化:
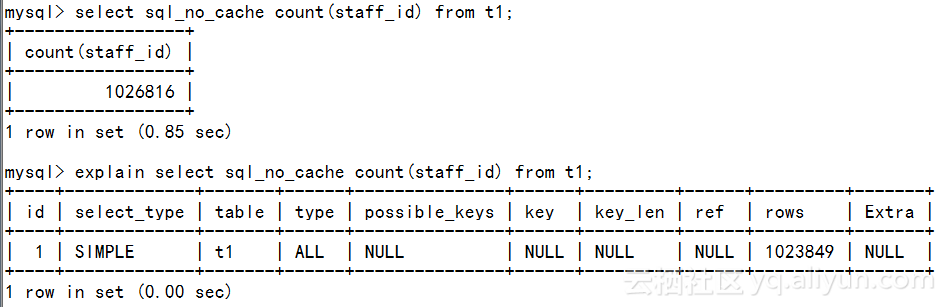
type 为ALL,表示进行了全表扫描
如何改进?优化措施很简单,就是对这个查询列建立索引。如下,
ALERT TABLE t1 ADD KEY(staff_id);
执行计划
explain select sql_no_cache count(staff_id) from t1 *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: index possible_keys: NULL key: staff_id key_len: 1 ref: NULL rows: 1023849 Extra: Using index 1 row in set (0.00 sec)
possible_key: NULL,说明没有WHERE条件时查询优化器无法通过索引检索数据,这里使用了索引的另外一个优点,即从索引中获取数据,减少了读取的数据块的数量。 无where条件的查询,可以通过索引来实现索引覆盖查询,但前提条件是,查询返回的字段数足够少,更不用说select *之类的
二次检索优化
select sql_no_cache rental_date from t1 where inventory_id<80000;
执行计划:
explain select sql_no_cache rental_date from t1 where inventory_id<80000*************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: range possible_keys: inventory_id key: inventory_id key_len: 3 ref: NULL rows: 153734 Extra: Using index condition 1 row in set (0.00 sec)
Extra:Using index condition 表示使用的索引方式为二级检索,即79999个书签值被用来进行回表查询。可想而知,还是会有一定的性能消耗的
尝试针对这个SQL建立联合索引,如下:
alter table t1 add key(inventory_id,rental_date);
执行计划
explain select sql_no_cache rental_date from t1 where inventory_id<80000*************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: range possible_keys: inventory_id,inventory_id_2 key: inventory_id_2 key_len: 3 ref: NULL rows: 162884 Extra: Using index 1 row in set (0.00 sec)
Extra:Using index 表示没有会标查询的过程,实现了索引覆盖
分页查询优化
select tid,return_date from t1 order by inventory_id limit 50000,10;
执行计划
explain select tid,return_date from t1 order by inventory_id limit 50000,10*************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: ALL possible_keys: NULL key: NULL key_len: NULL ref: NULL rows: 1023675 1 row in set (0.00 sec)
看出是全表扫描。加上而外的排序,性能消耗是不低的
如何通过覆盖索引优化呢?
创建一个索引,包含排序列以及返回列,由于tid是主键字段,因此,下面的复合索引就包含了tid的字段值
alter table t1 add index liu(inventory_id,return_date);
执行计划
explain select tid,return_date from t1 order by inventory_id limit 50000,10\G *************************** 1. row *************************** id: 1 select_type: SIMPLE table: t1 type: index possible_keys: NULL key: liu key_len: 9 ref: NULL rows: 50010 Extra: Using index 1 row in set (0.00 sec)
执行计划也可以看到,使用到了复合索引,并且不需要回表
覆盖索引是一种非常强大的工具,能大大提高查询性能,只需要读取索引而不需要读取数据,有以下优点:
1、索引项通常比记录要小,所以MySQL访问更少的数据。
2、索引都按值得大小存储,相对于随机访问记录,需要更少的I/O。
3、数据引擎能更好的缓存索引,比如MyISAM只缓存索引。
4、覆盖索引对InnoDB尤其有用,因为InnoDB使用聚集索引组织数据,如果二级索引包含查询所需的数据,就不再需要在聚集索引中查找。
限制:
1、覆盖索引也并不适用于任意的索引类型,索引必须存储列的值。
2、Hash和full-text索引不存储值,因此MySQL只能使用BTree。
3、不同的存储引擎实现覆盖索引都是不同的,并不是所有的存储引擎都支持覆盖索引。
4、如果要使用覆盖索引,一定要注意SELECT列表值取出需要的列,不可以SELECT * ,因为如果将所有字段一起做索引会导致索引文件过大,查询性能下降。
参考:
https://www.jianshu.com/p/8991cbca3854

 浙公网安备 33010602011771号
浙公网安备 33010602011771号