Flink源码解析(四)——从Flink集群部署和任务提交模式看Flink任务的核心组件
0. 说明
- 本文基于Flink 1.12;
- 本文是在阅读源码过程结合自己理解所写,不一定正确,欢迎大伙留言指出;
1. 集群部署
1.1. 部署方式
Flink集群部署可以简要的分为以下两种方式:
- 直接部署在服务器上(物理机、Kubernetes、docker等);
- 结合其他资源调度框架,如on Yarn、Mesos;
1.2. 部署在服务器上
常见于standalone模式。standalone模式是一种独立的集群模式,可以不依赖外部资源调度系统直接运行,所需资源是直接基于服务器的,由管理员手工启动。基于Kubernetes、docker的部署方式,其本质是将JobManager和TaskManager docker化,集群本身还是standalone的。
standalone模式可细分为:HA模式和非HA模式。HA模式需要注意:HA必须依赖于共享存储文件系统,要保证JobManager的元数据信息对所有节点共享。
1.3. 结合其他资源调度框架
Flink集群所需资源是向调度框架申请,调度框架的资源则是基于物理资源。和直接基于物理机得standalone模式相比,基于资源调度框架更具有灵活性,资源也可以复用。此时,任务的可靠性也是通过资源调度框架来实现的。
2.任务提交模式
2.1 session模式
在该模式,多个任务共享一个提前创建好的Flink集群,整个集群的资源在session集群启动时已固定了。常见的yarn-session模式,就是在先基于yarn启动一个Flink集群,然后向该集群提交任务。在集群的standalone模式下,通常提交任务也是session模式,只不过整个集群是由管理员手工启动。
2.2 Per-job模式
在该模式,每个任务在提交时都会创建各自集群,TM、JM的内存分配在启动任务的时候可以根据需求制定。任务单独启动启动、恢复都是单独执行的,任务恢复速度快。
2.2 Application模式
在该模式,每个任务在提交时都会创建一个集群。该模式和其他模式的区别在于:其他模式下,任务的main()方法都是在client侧运行,会在client侧生成JobGraphs,并将JobGraph提交到集群中,可能对client机器的资源消耗过多;Application模式,则在JobManager上运行application的main()函数,可节省资源。
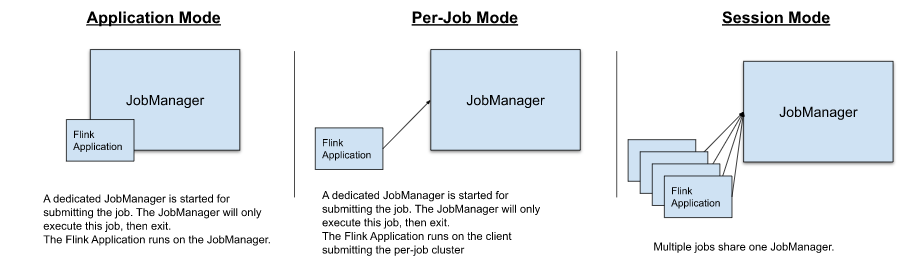
3. Flink任务涉及核心组件
简单来说,集群部署模式的不同,在于Flink的启动是由管理员手动启动还是有资源调度框架启动;任务提交模式的不同,在于任务与集群的关系或是任务main函数执行的位置不一样。这些变化中,任务涉及到的核心组件时相同:JobMaster、ResourceManager、TaskExecutor,所以弄清这些核心组件有利于我们在变化中找到不变的。
3.1. JobMaster
JobMaster是负责单个任务的执行。与之容易混淆的是JobManager,JobManager是一个抽象的概念,其作为Flink集群的manager是一个单独的进程(JVM),由一些service组成的(主要是Dispatcher、JobMaster、ResourceManager)。JobMaster仅是JobManager中的一个组件,JobManager为JobMaster提供任务资源、jar存储的等服务。值得注意的是,JobMaster在是由JobManagerRunnerImpl启动的。
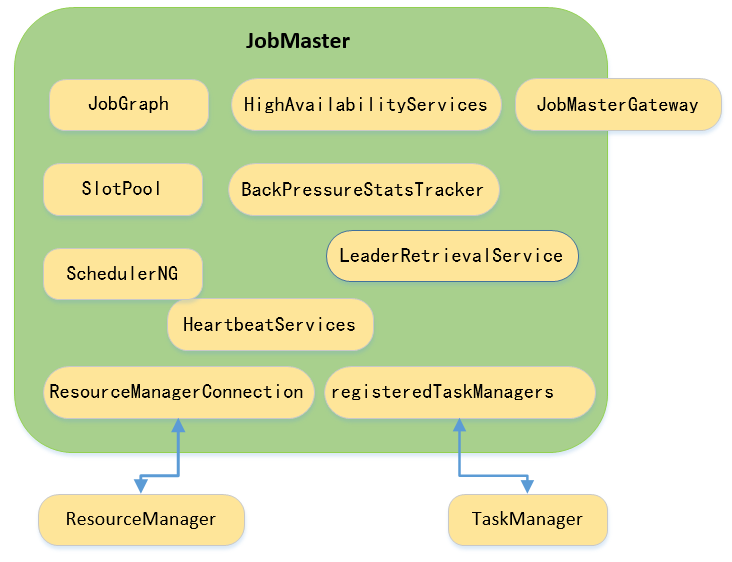
- JobGraph
JobGraph的生成是和任务提交的模式相关的,如session模式JobGraph是在client侧生成后提交到JobManager。JobMaster启动之后,JobGraph会被转换成ExecutionGraph,ExecutionGraph是JobGraph的并行版,两者的区别在此不详细展开。 - SlotPool
slotPool是JobMaster中管理资源的组件,在分配资源时会先在slotPool中分配,分配slot的策略有两种:按照位置优先分配;按照之前已分配的slot分配。若从slotPool申请不到slot,则将请求缓存起来,等连接上ResourceManager获取slot之后再分配slot。 - SchedulerNG
SchedulerNG会在JobMaster启动时启动,主要负责ExecutionGraph的执行。涉及SchedulerNG主要流程如下:
JobMaster#start()->startScheduling()
|
SchedulerBase#startScheduling()
|
| //启动所有的coordinator
| --startAllOperatorCoordinators()
| //根据部署策略(lazy、Eager)分配资源启动ExecutionGraph
| --startSchedulingInternal()
其中,OperatorCoordinator代表的是runtime operators,其运行在JobMaster中,一个OperatorCoordinator对应的是一个operator的Job vertex,其和operators的交互是通过operator event。主要负责subTask的重启、失败等,以及operator的checkpoint行为。
- HeartbeatServices
主要是为JobMaster和TaskManager、ResourceManager之前的心跳提供服务。 - HighAvailabilityServices
HighAvailabilityServices在JobMaster中主要是获取ResourceManager信息、checkpoint信息。 - BackPressureStatsTracker
backPressure是指当一个operator的处理速度小于上游下发的速度,数据就会在input buffer里出现积压,当buffer满了,数据就会无处可放,Flink将这种情况称为backPressure。Dispatcher通过JobMaster的BackPressureStatsTracker对每个TM的subTask做跟踪。涉及的流程如下:
Dispatcher#构造函数 //在集群启动时已生成Dispatcher实例
|
| //从配置文件获取tracker的参数配置
JobManagerSharedServices#fromConfiguration()
判断一个operator是否处于backpressure状态可以看Task#isBackPressured()方法。
- LeaderRetrievalService
LeaderRetrievalService获取当前服务的leader,在JobMaster中,LeaderRetrievalService是负责与ResourceManager链接,然后JobMaster会向ResourceManager注册。
3.2 ResourceManager
ResourceManager是Flink集群内部管理资源(slot)的组件。TaskManager向其提供slot,JobMaster向其请求slot执行任务。与此同时,RM会JobMaster、TaskManager保持心跳,其是心跳请求的发起方,当JobMaster、TaskManager失败的时候会采取相应的对策。
- ResourceManager的启动
RM的的启动时在JobManager的过程启动的,JobManager的启动入口是ClusuterEntryPoint,过程如下:
ClusuterEntryPoint#startCluster
|
| //在该过程中会启动Dispatcher、ResourceManager、 WebMonitorEndpoint
DefaultDispatcherResourceManagerComponentFactory#create
|
RpcEndpoint#start
整个过程如下:
- 在启动JobManager时,会启动haServices相关的服务;
- 在DefaultDispatcherResourceManagerComponentFactory#create()方法中,会先通过HA服务获取leader节点信息;
- 通过RpcEndpoint#start启动RM,以便和其他组件交互;
- RM中核心组件
RM中如LeaderElectionService 和JobMaster中的作用是相近的,这里不详细展开。-
slotManager
slotManager维护Flink 集群中一张slot视图,包括:所有注册、分配的slot以及待满足的slot请求(JobMaster中slotPool不能满足任务需求时发起的slot请求)。为了释放资源、防止内存泄漏,空闲的TaskManager将会被释放、超时的slot请求会请求失败。
slotManager在slot请求过程的角色如下,整个过程大致分为以下几个步骤:
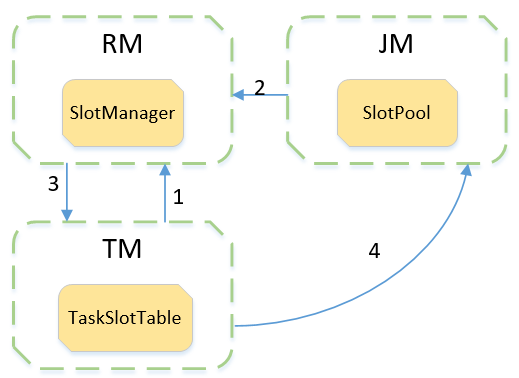
- 过程1:TM向RM注册后,向RM上报slot信息,slot信息被保存在RM的slotManager中;
- 过程2:JM会首先向slotPool请求slot,若能,则直接提交任务;若不能满足,则通过slotPool向RM请求slot资源;
- 过程3:若是RM中的slotManager的slot能满足JM的请求,则会向TM发起RPC请求申请对应的slot,TM中TaskSlotTable会把slot信息以slotoffer提供JM的slotPool(过程4);若是不能满足,则RM会向更底层的系统获取资源。
-
3.3 TaskManager
TaskManager与TaskExecutor的关系类似于JobManager与JobMaster。TaskExecutor负责task的执行。
TaskExecutor中的组件有与RM、JM交互服务,如TaskExecutorToResourceManagerConnection、resourceManagerHeartbeatManager等;有与JM交互的服务,jobManagerHeartbeatManager,这些组件功能与RM和JM中的类似,在这里会尝试分析TaskSlotTable、JobTable、KvStateService等。
- TaskManager的启动过程:
TaskManager的启动入口在TaskManagerRunner。
TaskManagerRunner#main
|
|-- runTaskManager
| //该过程会启动TaskManager
|-- createTaskExecutorService
| //该过程会从配置中初始化一些服务如:TaskManagerServices、KvStateService,
| //返回一个初始化的TaskExecutor,在初始化的过程中会启动相应的RPC endpoint
|-- startTaskManager
|---- TaskManagerServices.fromConfiguration //可以重点看看
|-- TaskExecutorService#start
这里我们会着重分析一下runTaskManager:
- 在
createTaskExecutorService->startTaskManager的过程中会从获取配置参数,最后会new TaskExecutor时通过调用父类的构造方法启动相应的RPC endpoint。在这个过程,我们可以看到taskManagerRunner是通过TaskExecutorToServiceAdapter.createFor(),仅仅是一个适配器,其本质还是TaskExecutor。 TaskExecutorService#start会逐步调用RpcEndpoint的start()方法,其RpcServer就是在上一步中初始化的。这里会逐步调用到TaskExecutor#onStart()。
-
TaskSlotTable
TaskSlotTable从不同的维度维护slot信息,如JobID和slot的关系,AllocationID与slot的关系,其具体存储的方式是map,这样根据不同的key就可以很快的获取到slot信息。其中,对于那些已分配但是无法分配到具体JobManage的slot会启动一个定时任务,若是超时会释放slot以免内存泄漏。- TaskSlotTable的初始化过程是在
TaskManagerServices#fromConfiguration方法中被初始化的; - TaskSlotTable的启动时在
TaskExecutor#startTaskExecutorServices中,这里对slot明确了free和负责timeout的线程。
TaskSlotTable在slot整个流转中的作用见上文。
- TaskSlotTable的初始化过程是在
-
KvStateService
KvState的注册服务,其启动过程TaskManagerServices#fromConfiguration方法中,具体过程如下:
public static TaskManagerServices fromConfiguration(){
//......
//从配置文件构造KvStateService
final KvStateService kvStateService =
KvStateService.fromConfiguration(taskManagerServicesConfiguration);
kvStateService.start();
//......
}
// 上面start()方法,最终会调用AbstractServerBase#start,该方法中要是bind到指定地址上。关键步骤如下:
private boolean attemptToBind(final int port) throws Throwable {
log.debug("Attempting to start {} on port {}.", serverName, port);
this.queryExecutor = createQueryExecutor();
this.handler = initializeHandler();
final NettyBufferPool bufferPool = new NettyBufferPool(numEventLoopThreads);
final ThreadFactory threadFactory =
new ThreadFactoryBuilder()
.setDaemon(true)
.setNameFormat("Flink " + serverName + " EventLoop Thread %d")
.build();
final NioEventLoopGroup nioGroup =
new NioEventLoopGroup(numEventLoopThreads, threadFactory);
this.bootstrap =
new ServerBootstrap()
.localAddress(bindAddress, port)
.group(nioGroup)
.channel(NioServerSocketChannel.class)
.option(ChannelOption.ALLOCATOR, bufferPool)
.childOption(ChannelOption.ALLOCATOR, bufferPool)
.childHandler(new ServerChannelInitializer<>(handler));
final int defaultHighWaterMark = 64 * 1024; // from DefaultChannelConfig (not exposed)
//noinspection ConstantConditions
// (ignore warning here to make this flexible in case the configuration values change)
if (LOW_WATER_MARK > defaultHighWaterMark) {
bootstrap.childOption(ChannelOption.WRITE_BUFFER_HIGH_WATER_MARK, HIGH_WATER_MARK);
bootstrap.childOption(ChannelOption.WRITE_BUFFER_LOW_WATER_MARK, LOW_WATER_MARK);
} else { // including (newHighWaterMark < defaultLowWaterMark)
bootstrap.childOption(ChannelOption.WRITE_BUFFER_LOW_WATER_MARK, LOW_WATER_MARK);
bootstrap.childOption(ChannelOption.WRITE_BUFFER_HIGH_WATER_MARK, HIGH_WATER_MARK);
}
try {
final ChannelFuture future = bootstrap.bind().sync();
if (future.isSuccess()) {
final InetSocketAddress localAddress =
(InetSocketAddress) future.channel().localAddress();
serverAddress =
new InetSocketAddress(localAddress.getAddress(), localAddress.getPort());
return true;
}
// the following throw is to bypass Netty's "optimization magic"
// and catch the bind exception.
// the exception is thrown by the sync() call above.
throw future.cause();
} catch (BindException e) {
//.....
}
// any other type of exception we let it bubble up.
return false;
}
- JobTable
JobTable的任务是用来管理一个Job在TaskExecutor上的生命周期。其主要是维护了两个Map:JobID与Job/Connection、ResourceId与JobID。其中Job接口反映了job和JobMaster的connect。
JobTable的初始化过程也是在TaskManagerServices#fromConfiguration中,在此仅仅是初始了默认的DefaultJobTable。
JobTable的初始过程在RM向TM请求slot的过程中初始化的,具体过程如下:
@Override
public CompletableFuture<Acknowledge> requestSlot(
final SlotID slotId,
final JobID jobId,
final AllocationID allocationId,
final ResourceProfile resourceProfile,
final String targetAddress,
final ResourceManagerId resourceManagerId,
final Time timeout) {
// TODO: Filter invalid requests from the resource manager by using the
// instance/registration Id
log.info(
"Receive slot request {} for job {} from resource manager with leader id {}.",
allocationId,
jobId,
resourceManagerId);
if (!isConnectedToResourceManager(resourceManagerId)) {
final String message =
String.format(
"TaskManager is not connected to the resource manager %s.",
resourceManagerId);
log.debug(message);
return FutureUtils.completedExceptionally(new TaskManagerException(message));
}
try {
allocateSlot(slotId, jobId, allocationId, resourceProfile);
} catch (SlotAllocationException sae) {
return FutureUtils.completedExceptionally(sae);
}
final JobTable.Job job;
try {
//初始化job
job =
jobTable.getOrCreateJob(
jobId, () -> registerNewJobAndCreateServices(jobId, targetAddress));
} catch (Exception e) {
// free the allocated slot
try {
taskSlotTable.freeSlot(allocationId);
} catch (SlotNotFoundException slotNotFoundException) {
// slot no longer existent, this should actually never happen, because we've
// just allocated the slot. So let's fail hard in this case!
onFatalError(slotNotFoundException);
}
// release local state under the allocation id.
localStateStoresManager.releaseLocalStateForAllocationId(allocationId);
// sanity check
if (!taskSlotTable.isSlotFree(slotId.getSlotNumber())) {
onFatalError(new Exception("Could not free slot " + slotId));
}
return FutureUtils.completedExceptionally(
new SlotAllocationException("Could not create new job.", e));
}
if (job.isConnected()) {
offerSlotsToJobManager(jobId);
}
return CompletableFuture.completedFuture(Acknowledge.get());
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号