
论文阅读:《Efficient Neural Architecture Search via Parameter Sharing》
《Efficient Neural Architecture Search via Parameter Sharing》
Hieu Pham · Melody Y. Guan · Barret Zoph · Quoc V. Le · Jeff Dean
2018-02-12
在paperdigest网站上显示,这篇文章的影响因子高达9!
必看论文!
注意到这篇论文正是Zoph大神写的。
简介
本文要着重解决的问题是标准NAS时间过长的问题。
标准NAS就是一板一眼地生成新架构、从头训练评估这个架构,然后将评估结果返回给架构生成器,以便生成出新架构。最初的研究中,一次完整的NAS需要450个GPU跑3~4天,约合3~4万GPU hours(来自2018年Zoph等人的工作)。
本文作者敏锐地注意到,这种原始的NAS每训练好一个网络,在评估完架构的准确度后就直接把训练好的权重扔掉了。而这其实是可以利用的地方。如果能对这些权重善加利用,就能够节省许多训练时间。
本文的主要贡献是,让所有child model强制共享权重,从而规避了从头训练每个child的问题。
并且实践下来我们发现,参数共享的方法不仅是可行的,而且还能够带来更强的性能。
本文的工作ENAS只需在Nvidia GTX 1080Ti GPU上跑不超过16小时即可完成。这一效果比NAS好了1000倍!(大概两千倍)。由于它实在是非常“有效”,这一技术被命名为ENAS(Efficient Neural Architecture Search)。
我读这篇文章的主要目的就是学习它的权重共享思路。
正文
NA架构-搜索空间
先说ENAS的网络架构模型。网络架构:Neural Architecture,后文简称NA。NA\(\in\)搜索空间。
ENAS用DAG表示神经网络的结构,其中节点表示本地运算(local computation),而节点之间的连线表示数据的流通。(其他工作中有时用另一种表示方式,即节点表示特征图,这两者不要搞混。)
ENAS的Controller
controller是NAS的重要组成部件,负责生成NA。
ENAS的Controller是一个RNN,决定了1)哪些edge要激活;2)在每个节点上要进行什么种类的运算。
本文的controller使用的是一个100个隐含单元的LSTM。
controller的policy可以用\(\pi(m;\theta)\)表示。其中m表示model,即一个NA。
为什么要在这里填入一个NA?不能是\(m=\pi(\theta)\)吗?
我推测这里是表示一种分布,而非一个函数。假如试图写成函数的形式\(m=\pi(\theta)\),那这个函数每次返回的结果不一样,这并不符合数学中对函数的定义。这种每次返回结果不一样的“函数”倒是蛮符合计算机领域的直觉,我可能是代码写太多变得不熟悉数学语言了吧。
Recurrent cell
特别地,我们关心如何设计一个recurrent cell。本文对recurrent cell的设计和Zoph&Le在2017年所做的工作不同,他们当时将网络的拓扑结构固定成一个binary tree,只学习树中每个节点执行的操作。而本文的设计则两者都可以改,因此更加灵活。
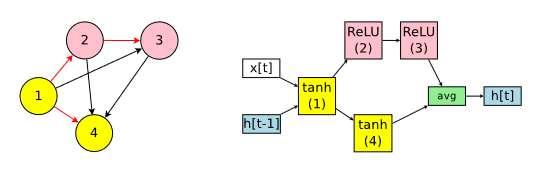
这是原文中用来阐述创建recurrent cell的图。
一个recurrent cell有两个输入和一个输出,两个输入分别是正儿八经的外界输入x[t],和上一time step的遗留信息h[t-1]
一个recurrent cell搜索出来可能就像上图这样。其中左图红色的edge表示,这些数据通路是激活的。
不难发现,左图如果算上红黑线,其表示的有向图的基本图是一个无向完全图。也就是说这个搜索空间是这样构建的:先规定需要N个节点,然后给节点标上序号1~N,序号1接收x[t]和h[t-1],后面的序号有机会接收所有序号比它小的节点的输出,因此对这些节点进行两两连线,并按照序号大小决定箭头方向,序号小的为箭尾,序号大的为箭头。
有时搜索出的图是不收束的,即出度为0的节点不止一个,例如上图例子中的节点3和节点4,这时它们的输出会取平均后成为输出(正如上图右半边那样)。
上图对应的计算式可以写成:
(公式与原文表示有差异,本质是一样的)
按我的想法,有时搜索出的图是支离破碎的,即中间存在不连通的子图,这种情况可以筛去,又或者原文可能有独特的处理方式。
我们来计算一下搜索空间的空间复杂度。仅限上述讨论的一个recurrent cell,假定允许N个节点和L种节点类型,共有多少种可能的图?
我是这样算的:共有N个节点,每个节点有Rt种可能;共有\(\cfrac{N\cdot(N-1)}{2}\)条边,每个边有激活和不激活两种可能。这样算下来,不考虑病态图(非连通图以及其他可能的病态图)的剔除,共有\(Rt^N\times 2^{\frac{N\cdot (N-1)}{2}}\)种可能的图。实际上剔除掉病态图后应该更少。
原文计算得到的是\(Rt^N\times N!\),我觉得不太对,没有这么多。
Convolutional Cell
本文的Convolutional Cell(后简称Ccell)和我想象中vanilla的版本不太一样,比较奇怪。
本文的Ccell必定接受另外两个cell的输入。与其叫它Ccell,我个人其实更愿意叫它Merge Cell。
并且,Ccell有两处都出现了merge,一开始把我搞蒙了。
一个Ccell本身内部有若干节点,其中node1 node2是输入,也就是有两个输入。因此在Convolutional Network的搜索中,需要为这个Ccell指定两个输入。这是一个merge。
Ccell本身内部的节点,排除掉两个输入节点,剩下的节点也分别接受2个来自其他节点的输入,分别处理后相加得出节点结果。
如图所示。
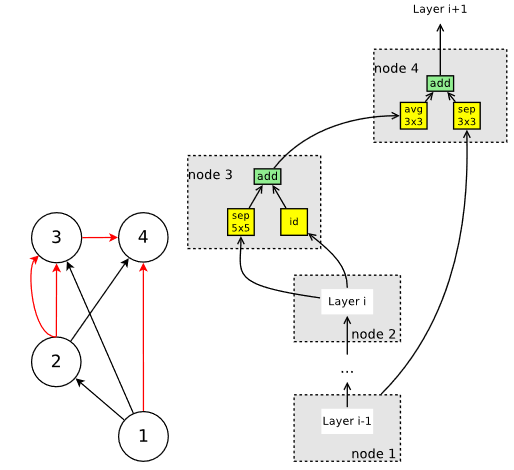
确定好了结构,我们就容易分析出,要生成这样一个Ccell,需要给定node3 node4的各个参量。
放在一般情况下,假设有B个内部Node,那么剔除掉两个输入节点,就有B-2个可变node。每个可变node都需要指定2个前驱节点和2个操作类型参量。本文为node支持的操作类型有5种,分别是identity(不变),sep_conv 3x3, sep_conv 5x5, avg_pool 3x3, max_pool 3x3。前驱节点必须是序号更小的节点,否则会成环。
(sep_conv: seperable convolution)
Convolutional Network
疑惑。我认为本文的论述前后矛盾。
本文原文将Design Convolutional Networks放在了Design Convolutional Cell之前。
在Design Convolutional Networks一节中,使用了这张图:
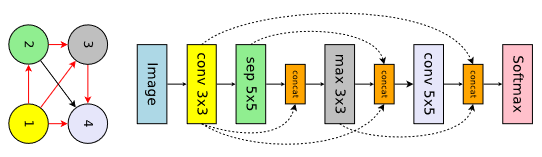
concat不算正式的节点。即便concat算作正式的节点,那它也不该接受3个输入,应该是2个。
训练过程
在ENAS中有两部分可学习的参量:LSTM controller的参数\(\theta\),和child模型相互共享的参数\(\omega\)。
训练模型参数\(\omega\)
对\(\omega\)的训练目标可用数学语言表示成:
解释起来是这样的:首先m表示模型,是一个符合\(\pi(m;\theta)\)分布(也就是controller policy)的值。然后,\(\mathcal{L}(m;\omega)\)表示这个模型m和模型对应的权重\(\omega\)伙同起来得出的Loss,注意到此处\(\omega\)是所有模型共享的参数,所以不需要让每个模型都拥有一个独占的\(\omega_m\)。又因为m是一个随机变量,因此这个计算出的Loss实际上也是一个受控的随机变量,\(\mathbb{E}(...)\)正是要做Loss的无偏估计。综上所述,可简记
这样看起来比原式更简洁,并且更容易看出m只是一个“中间变量”,真正主导这个值的还是\(\theta\)和\(\omega\)。
进一步,我们需要求的值是上面这个无偏估计关于\(\omega\)的偏导数,即
基于蒙特卡洛(Monte Carlo)估计,有
也就是说明了取M个点,分别计算\(\nabla_\omega Loss\)再取平均即可得到大概的值。这个公式没什么高深的。
作者表示,令人惊讶的是,这个M取1就可以工作得很顺利了。
我推测是因为SGD这种梯度下降算法本身由于会迭代很多次,相当于把重复取很多次i的工作完成了,所以这里并不需要取一个较大的M。
训练控制器参数\(\theta\)
对\(\theta\)的训练目标可表示成:
\(\mathcal{R}(m;\omega)\)表示模型m和参数\(\omega\)对应的reward,这个反馈在validation set上取得。
但是根据\(m\sim\pi(m;\theta)\),m应该是一个随机变量。因此\(\mathcal{R}\)也是一个随机变量,它仍然需要经过无偏估计算符\(\mathbb{E}\)才能变成一个确定变量。(姑且就把\(\mathbb{E}\)当成算符吧)
作者提到,在这一步骤中,ENAS取样若干个m,并直接在validation set上验证,取其中reward最高的一个m,对它进行从头开始的训练。“对所有取样的m都进行从头训练,然后再取效果最好的一个的话,可能对最终的搜索结果有好处。但是只取一个的做法已经可以达到类似的性能,同时非常地经济(非常节省)。”
实验
本文做了两部分实验,一部分是在Penn Treebank上进行的NLP NAS,另一部分是在Cifar10上进行的Classification NAS。
效果当然是很好。
参数共享去哪了?
通篇似乎都没有详细讲参数共享,只提了一嘴,说参数共享是受到Real等人在2017年~2018年的工作的启发。
Real等人的工作:
《Large-scale evolution of image classifiers》in ICML, 2017
《Peephole: Predicting network performance before training》2018
一点吐槽
原文的篇章有些部分的顺序读起来不太舒服,比如没有单独介绍controller(虽然只需要一句话),比如硬要把train和Design Convolutional Network塞在Rcell(Recurrent cell)和Ccell(Convolutional cell)中间。总之,我按照自己的理解对原文进行了一定的重排,疑虑较大的地方我已经注明了。
被引分析
来自readpaper的被引文献列表
共 514 条,按被引数排序,仅看前二十
[1] SNAS: Stochastic Neural Architecture Search
[2] Transformers in Vision: A Survey
[3] Single-Path NAS: Device-Aware Efficient ConvNet Design
[4] AutoLoss: Learning Discrete Schedules for Alternate Optimization
[5] FasterSeg: Searching for Faster Real-time Semantic Segmentation
[6] Computation Reallocation for Object Detection
[7] BATS: Binary ArchitecTure Search
[8] Blending Diverse Physical Priors with Neural Networks
[9] Do Normalization Layers in a Deep ConvNet Really Need to Be Distinct
[10] Teacher Guided Architecture Search
[11] Do Normalization Layers in a Deep ConvNet Really Need to Be Distinct (重复)
[12] Exploring Shared Structures and Hierarchies for Multiple NLP Tasks.
[13] Teacher Guided Architecture Search(重复)
[14] FasterSeg: Searching for Faster Real-time Semantic Segmentation(重复)
[15] Progressive Differentiable Architecture Search: Bridging the Depth Gap between Search and Evaluation
[16] Evaluating The Search Phase of Neural Architecture Search
[17] DCNAS: Densely Connected Neural Architecture Search for Semantic Image Segmentation
[18] Angle-based Search Space Shrinking for Neural Architecture Search
[19] Detection and visualization of abnormality in chest radiographs using modality-specific convolutional neural network ensembles
[20] Exploring the Loss Landscape in Neural Architecture Search
来自谷歌学术的被引文献列表
共 1644 条,按相关性排序,仅看前二十
[1] (9619) Squeeze-and-excitation networks (2018)
[2] (2069) Darts: Differentiable architecture search (2018)
[3] (1529) Transformer-xl: Attentive language models beyond a fixed-length context (2019)
[4] (1470) Mnasnet: Platform-aware neural architecture search for mobile (2019)
[5] (1295) Progressive neural architecture search (2018)
[6] (1382) Searching for mobilenetv3 (2019)
[7] (1203) Neural architecture search: A survey (2019)
[8] (987) Proxylessnas: Direct neural architecture search on target task and hardware (2018)
[9] (1108) Advances and open problems in federated learning (2019)
[10] (788) Autoaugment: Learning augmentation policies from data (2018)
[11] (821) Autoaugment: Learning augmentation strategies from data (2019)
[12] (701) Rethinking the value of network pruning (2018)
[13] (657) Fbnet: Hardware-aware efficient convnet design via differentiable neural architecture search (2019)
[14] (606) Auto-deeplab: Hierarchical neural architecture search for semantic image segmentation (2019)
[15] (565) SNAS: stochastic neural architecture search (2018)
[16] (450) A genetic programming approach to designing convolutional neural network architectures (2017)
[17] (413) Demystifying parallel and distributed deep learning: An in-depth concurrency analysis (2019)
[18] (410) Neural architecture optimization (2018)
[19] (402) Haq: Hardware-aware automated quantization with mixed precision (2019)
[20] (532) Randaugment: Practical automated data augmentation with a reduced search space (2020)
相关其他链接:
专栏写起来要随意一些,不像论文那样正式、惜字如金,国内的很多分析性的专栏写得真的很不错。
知乎ENAS: 更有效地设计神经网络模型(AutoML)(仔细看下来后发现里面的论述有点问题)
David 9你想要的神经网络自动设计,谷歌大脑帮你实现了:用参数共享高效地搜索神经网络架构(ENAS)(仔细看下来后发现并没有详述ENAS的权重共享方法)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号