Apache Doris学习笔记
简介
Apache Doris 是一款基于 MPP(Massively Parallel Processing,大规模并行处理架构) 架构的高性能、实时分析型数据库。它以高效、简单和统一的特性著称,能够在亚秒级的时间内返回海量数据的查询结果。Doris 既能支持高并发的点查询场景,也能支持高吞吐的复杂分析场景。
基于这些优势,Apache Doris 非常适合用于报表分析、即席查询、统一数仓构建、数据湖联邦查询加速等场景。用户可以基于 Doris 构建大屏看板、用户行为分析、AB 实验平台、日志检索分析、用户画像分析、订单分析等应用。
应用场景
- 实时数据分析:
- 实时报表与实时决策: 为企业内外部提供实时更新的报表和仪表盘,支持自动化流程中的实时决策需求。
- 交互式探索分析: 提供多维数据分析能力,支持对数据进行快速的商业智能分析和即席查询(Ad Hoc 根据即时需求临时编写的、非预定义的数据库查询操作),帮助用户在复杂数据中快速发现洞察。
- 用户行为与画像分析: 分析用户参与、留存、转化等行为,支持人群洞察和人群圈选等画像分析场景。
- 湖仓融合分析:
- 湖仓查询加速: 通过高效的查询引擎加速湖仓数据的查询。
- 多源联邦分析: 支持跨多个数据源的联邦查询,简化架构并消除数据孤岛。
- 实时数据处理: 结合实时数据流和批量数据的处理能力,满足高并发和低延迟的复杂业务需求。
- 半结构化数据分析:
- 日志与事件分析: 对分布式系统中的日志和事件数据进行实时或批量分析,帮助定位问题和优化性能。
整体架构
Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL。用户可以通过各类客户端工具访问 Apache Doris,并支持与 BI 工具无缝集成。
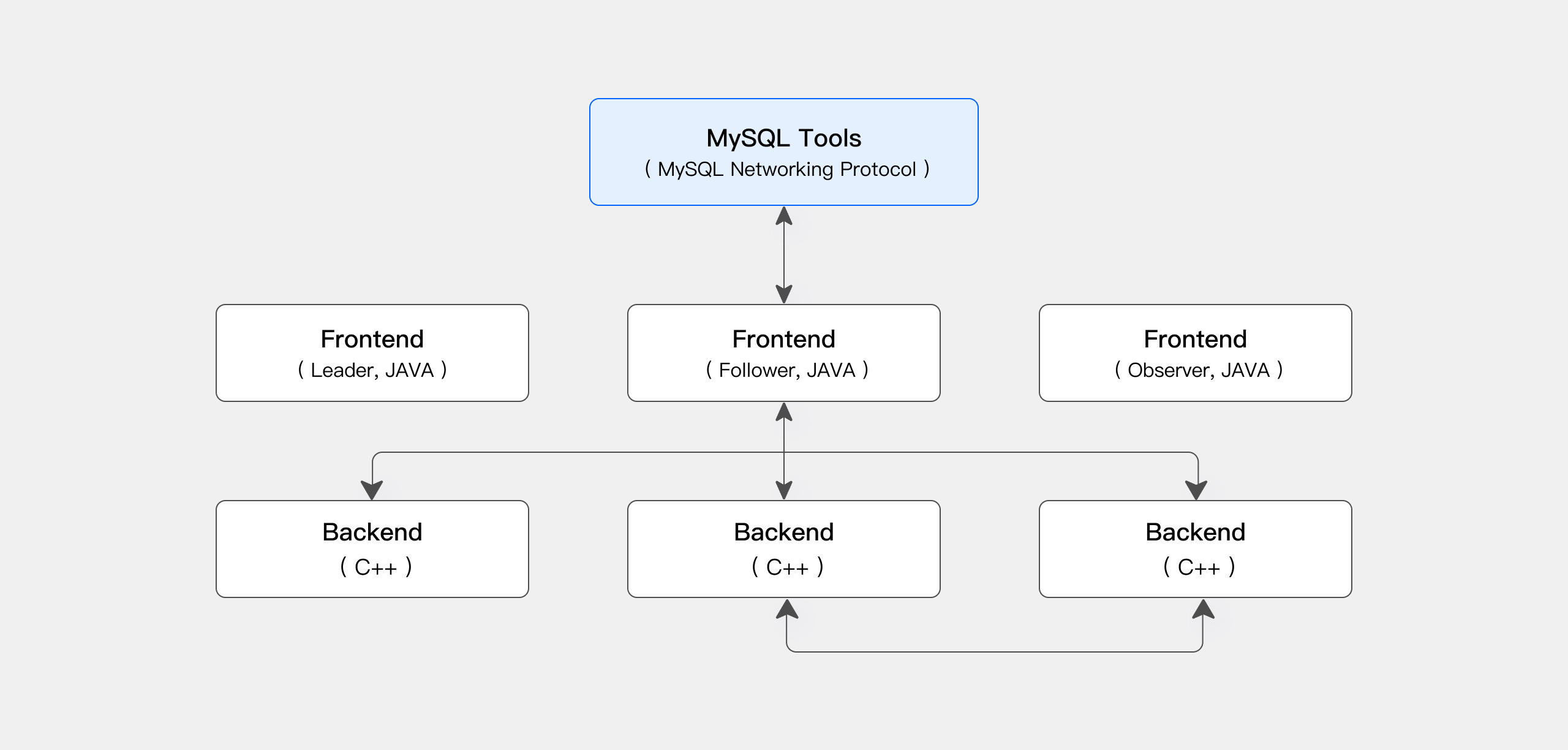
存算一体架构
Apache Doris 存算一体架构精简且易于维护。它包含以下两种类型的进程:
- Frontend (FE): 主要负责接收用户请求、查询解析和规划、元数据管理以及节点管理。
- Backend (BE): 主要负责数据存储和查询计划的执行。数据会被切分成数据分片(Shard),在 BE 中以多副本方式存储。
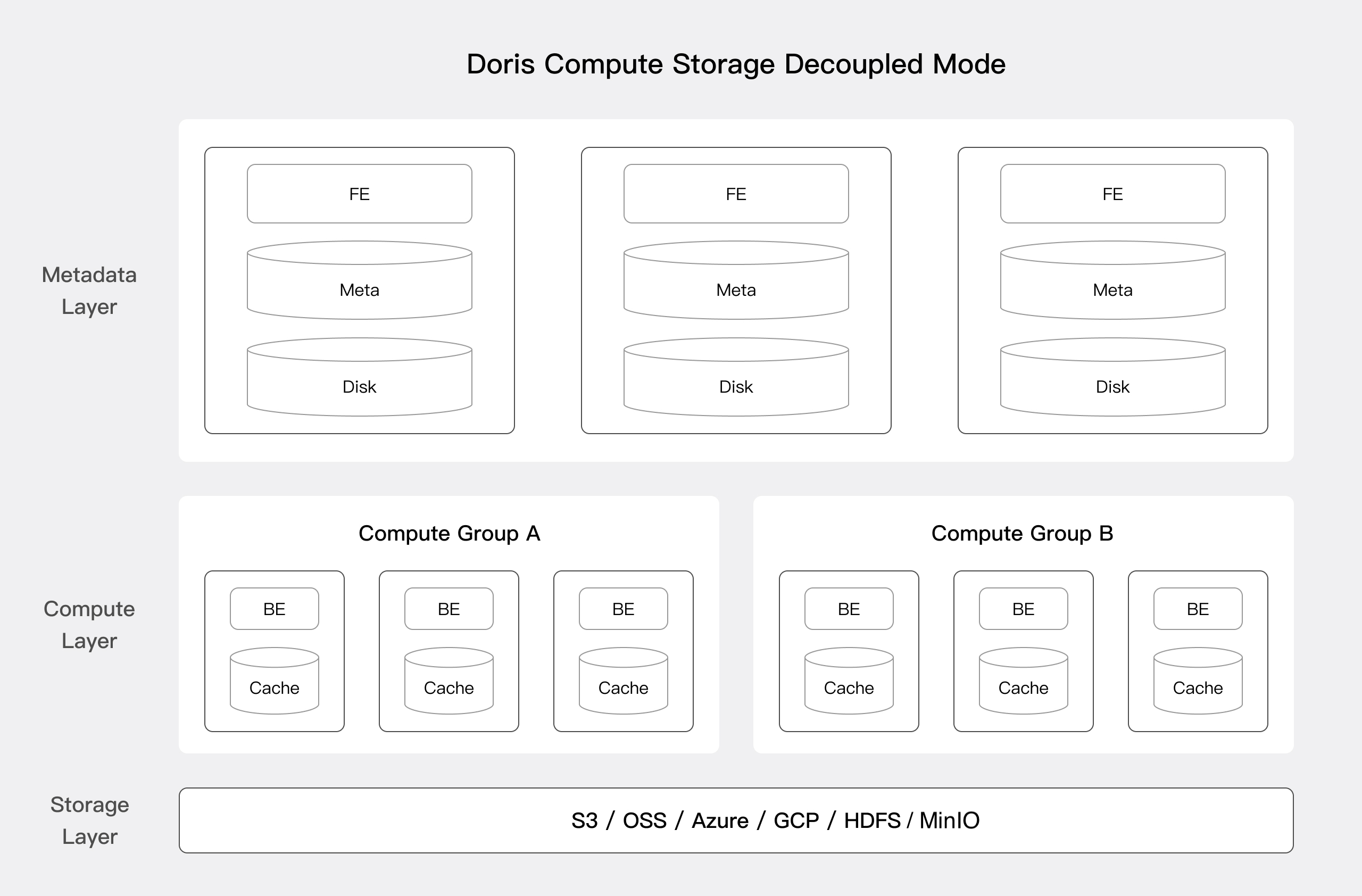
存算分离架构
Apache Doris 存算分离版使用统一的共享存储层作为数据存储空间。存储和计算分离后,用户可以独立扩展存储容量和计算资源,从而实现最佳性能和成本效益。存算分离架构分为以下三层:
- 元数据层: 负责请求规划、查询解析以及元数据的存储和管理。
- 计算层: 由多个计算组组成。每个计算组可以作为一个独立的租户承担业务计算。每个计算组包含多个无状态的 BE 节点,可以随时弹性伸缩 BE 节点。
- 存储层: 可以使用 S3、HDFS、OSS、COS、OBS、Minio、Ceph 等共享存储来存放 Doris 的数据文件,包括 Segment 文件和反向索引文件等。
Apache Doris 的核心特性
- 高可用: Apache Doris 的元数据和数据均采用多副本存储,并通过 Quorum 协议同步数据日志。当大多数副本完成写入后,即认为数据写入成功,从而确保即使少数节点发生故障,集群仍能保持可用性。Apache Doris 支持同城和异地容灾,能够实现双集群主备模式。当部分节点发生异常时,集群可以自动隔离故障节点,避免影响整体集群的可用性。
- 高兼容: Apache Doris 高度兼容 MySQL 协议,支持标准 SQL 语法,涵盖绝大部分 MySQL 和 Hive 函数。通过这种高兼容性,用户可以无缝迁移和集成现有的应用和工具。Apache Doris 支持 MySQL 生态,用户可以通过 MySQL 客户端工具连接 Doris,使得操作和维护更加便捷。同时,可以使用 MySQL 协议对 BI 报表工具与数据传输工具进行兼容适配,确保数据分析和数据传输过程中的高效性和稳定性。
- 实时数仓: 基于 Apache Doris 可以构建实时数据仓库服务。Apache Doris 提供了秒级数据入库能力,上游在线联机事务库中的增量变更可以秒级捕获到 Doris 中。依靠向量化引擎、MPP 架构及 Pipeline 执行引擎等加速手段,可以提供亚秒级数据查询能力,从而构建高性能、低延迟的实时数仓平台。
- 湖仓一体: Apache Doris 可以基于外部数据源(如数据湖或关系型数据库)构建湖仓一体架构,从而解决数据在数据湖和数据仓库之间无缝集成和自由流动的问题,帮助用户直接利用数据仓库的能力来解决数据湖中的数据分析问题,同时充分利用数据湖的数据管理能力来提升数据的价值。
- 灵活建模: Apache Doris 提供多种建模方式,如宽表模型、预聚合模型、星型/雪花模型等。数据导入时,可以通过 Flink、Spark 等计算引擎将数据打平成宽表写入到 Doris 中,也可以将数据直接导入到 Doris 中,通过视图、物化视图或实时多表关联等方式进行数据的建模操作。
技术特点
使用接口
Doris 采用 MySQL 协议,高度兼容 MySQL 语法,支持标准 SQL。
存储引擎
在存储引擎方面,Apache Doris 采用列式存储,按列进行数据的编码、压缩和读取,能够实现极高的压缩比,同时减少大量非相关数据的扫描,从而更有效地利用 IO 和 CPU 资源。
Apache Doris 也支持多种索引结构,以减少数据的扫描:
- Sorted Compound Key Index: 最多可以指定三个列组成复合排序键。通过该索引,能够有效进行数据裁剪,从而更好地支持高并发的报表场景。
- Min/Max Index: 有效过滤数值类型的等值和范围查询。
- BloomFilter Index: 对高基数列的等值过滤裁剪非常有效。
- Inverted Index: 能够对任意字段实现快速检索。
在存储模型方面,Apache Doris 支持多种存储模型,针对不同的场景做了针对性的优化:
- 明细模型(Duplicate Key Model): 适用于事实表的明细数据存储。
- 主键模型(Unique Key Model): 保证 Key 的唯一性,相同 Key 的数据会被覆盖,从而实现行级别数据更新。
- 聚合模型(Aggregate Key Model): 相同 Key 的 Value 列会被合并,通过提前聚合大幅提升性能。
Apache Doris 也支持强一致的单表物化视图和异步刷新的多表物化视图。单表物化视图在系统中自动刷新和维护,无需用户手动选择。多表物化视图可以借助集群内的调度或集群外的调度工具定时刷新,从而降低数据建模的复杂性。
安装部署
见官网https://doris.incubator.apache.org/zh-CN/docs/3.0/install/preparation/env-checking
数据表
Doris的数据表数据以列的方式存储,分为key列和value列。对于value列的增减或者修改类型是轻量的,秒级别完成。对于key列(重量级的)不建议修改。
数据表模型
Doris数据表模型分为三种:明细模型、主键模型、聚合模型。
明细模型(Duplicate Key Model)
明细模型运行指定的key列重复,doris会存储所有的写入数据,适合存储日志,数据变化记录等数据。
建表语句
CREATE TABLE IF NOT EXISTS example_tbl_duplicate
(
log_time DATETIME NOT NULL,
log_type INT NOT NULL,
error_msg VARCHAR(1024),
op_id BIGINT,
op_time DATETIME
)
DUPLICATE KEY(log_time, log_type)
DISTRIBUTED BY HASH(log_type) BUCKETS 10;
DUPLICATE KEY指定明细模型和key列DISTRIBUTED BY HASH(log_type)表明根据log_type字段 并按照Hash分桶BUCKETS 10指定分桶数为10
主键模型(Unique Key Model)
对于数据需要保持唯一性,需要更新的数据,使用主键模型。它保证了key列的数据唯一,插入或更新时,会新数据会覆盖旧的相同key的数据。
建表语句
CREATE TABLE IF NOT EXISTS example_tbl_unique
(
user_id LARGEINT NOT NULL,
user_name VARCHAR(50) NOT NULL,
city VARCHAR(20),
age SMALLINT,
sex TINYINT
)
UNIQUE KEY(user_id, user_name)
DISTRIBUTED BY HASH(user_id) BUCKETS 10
PROPERTIES (
"enable_unique_key_merge_on_write" = "true"
);
UNIQUE KEY指定主键模型和key列DISTRIBUTED BY HASH(user_id)表明根据user_id字段 并按照Hash分桶BUCKETS 10指定分桶数为10enable_unique_key_merge_on_write表明合并方式为写时合并
聚合模型(Aggregate Key Model)
聚合模型专为高效处理大规模数据查询中的聚合操作设计。它通过预聚合数据,减少重复计算,提升查询性能。 适用于需要汇总计算的场景。
建表语句
CREATE TABLE IF NOT EXISTS example_tbl_agg
(
user_id LARGEINT NOT NULL,
load_dt DATE NOT NULL,
city VARCHAR(20),
last_visit_dt DATETIME REPLACE DEFAULT "1970-01-01 00:00:00",
cost BIGINT SUM DEFAULT "0",
max_dwell INT MAX DEFAULT "0",
)
AGGREGATE KEY(user_id, load_dt, city)
DISTRIBUTED BY HASH(user_id) BUCKETS 10;
AGGREGATE KEY(user_id, load_dt, city)指定主键模型和key列,数据导入时,会按照key列相同的数据进行聚合成一行DISTRIBUTED BY HASH(user_id)表明根据user_id字段 并按照Hash分桶BUCKETS 10指定分桶数为10
维度聚合类型
| 聚合方式 | 描述 |
|---|---|
| SUM | 求和,多行的 Value 进行累加。 |
| REPLACE | 替代,下一批数据中的 Value 会替换之前导入过的行中的 Value。 |
| MAX | 保留最大值。 |
| MIN | 保留最小值。 |
| REPLACE_IF_NOT_NULL | 非空值替换。与 REPLACE 的区别在于对 null 值,不做替换。 |
| HLL_UNION | HLL 类型的列的聚合方式,通过 HyperLogLog 算法聚合。 |
| BITMAP_UNION | BITMAP 类型的列的聚合方式,进行位图的并集聚 |
语法
表操作
CREATE TABLE [IF NOT EXISTS] table_name
(
column_name column_type [COMMENT "comment"],
...
-- 模型相关关键字(根据模型选择)
[DUPLICATE KEY (col1, col2, ...)] -- 明细模型
[AGGREGATE KEY (col1, col2, ...)] -- 聚合模型
[UNIQUE KEY (col1, col2, ...)] -- 主键模型 更新模型
)
[COMMENT "table comment"]
PARTITION BY (partition_column) -- 分区方式(可选,如RANGE、LIST)
DISTRIBUTED BY HASH (distribute_column) [BUCKETS num] -- 分桶方式(必选)
[PROPERTIES ("key" = "value", ...)]; -- 表属性(如存储介质、副本数等)
视图语法
CREATE VIEW [IF NOT EXISTS] view_name AS SELECT query;
查询语法
Doris查询语法与MySql很相似,并且支持ROW_NUMBER()、RANK()、SUM() OVER()等窗口函数,并新增两种聚合函数
PERCENTILE_CONT():计算连续百分位数APPROX_COUNT_DISTINCT():近似去重计数(高性能)
SELECT [DISTINCT] col1, col2, ...
FROM table_name
[WHERE condition]
[GROUP BY col1, col2, ... [HAVING condition]]
[ORDER BY col1 [ASC|DESC], ...]
[LIMIT num];
索引
Doris有两种类型的索引:点差索引和跳数索引
- 点差索引:原理是通过where条件进行查询对应的数据行,然后读取对应行。Doris 的点查索引包括前缀索引和倒排索引。
- 前缀索引:Doris按照排序键有序存储数据,没1024行创建一个稀疏前缀索引,索引key是当前1024行第一列的值。查询时会从相关1024行第一行开始扫描数据。
- 倒排索引:Doris 会建立每个值到对应行号的倒排表。对应等值查询,先从倒排表中查询对应行号集合,直接读取对应行的数据。
- 跳数索引:原理是通过索引确定不满足对应查询条件的数据块,跳过这些数据库,只查询有可能满足条件的数据块,然后在进行过滤查询。Doris 的跳数索引包括 ZoneMap 索引、BloomFilter 索引、NGram BloomFilter 索引。
- ZoneMap 索引:会自动维护每一列的统计信息,为每一个数据文件和数据块记录最大值、最小值、是否有 NULL。范围条件查询时可以直接判断是否包含满足的数据。
- BloomFilter 索引:将索引对应列的可能取值存入 BloomFilter 数据结构中,可以快速判断是否存在BloomFilter中,BloomFilter 存储空间占用很低。当等值查询时,判断值是否在BloomFilter中,就可以判断是否查询对应数据文件和数据块。(适合类型,状态等字段)
- NGram BloomFilter: 用于加速文本字段
like的查询,它会将文本进行NGram分词,然后将分词数据存入BloomFilter中。当like查询时,它会将 LIKE 的 pattern 也进行 NGram 分词,判断每个词是否在 BloomFilter 中,判断是否查询对应数据文件和数据块。(需要模糊查询的文本字段)
Doris的前缀索引和ZoneMap 索引是系统自动维护的,无需创建。
- 各种类型索引特点对比
| 类 型 | 索引 | 优点 | 局限 |
|---|---|---|---|
| 点查索引 | 前缀索引 | 内置索引,性能最好 | 一个表只有一组前缀索引 |
| 点查索引 | 倒排索引 | 支持分词和关键词匹配,任意列可建索引, 多条件组合,持续增加函数加速 |
索引存储空间较大,与原始数据相当 |
| 跳数索引 | ZoneMap 索引 | 内置索引,索引存储空间小 | 支持的查询类型少,只支持等于、范围 |
| 跳数索引 | BloomFilter 索引 | 比 ZoneMap 更精细,索引空间中等 | 支持的查询类型少,只支持等于 |
| 跳数索引 | NGram BloomFilter 索引 | 支持 LIKE 加速,索引空间中等 | 支持的查询类型少,只支持 LIKE 加速 |
- 索引加速的运算符和函数列表
| 运算符 / 函数 | 前缀索引 | 倒排索引 | ZoneMap 索引 | BloomFilter 索引 | NGram BloomFilter 索引 |
|---|---|---|---|---|---|
| = | YES | YES | YES | YES | NO |
| != | YES | YES | NO | NO | NO |
| IN | YES | YES | YES | YES | NO |
| NOT IN | YES | YES | NO | NO | NO |
| >, >=, <, <=, BETWEEN | YES | YES | YES | NO | NO |
| IS NULL | YES | YES | YES | NO | NO |
| IS NOT NULL | YES | YES | NO | NO | NO |
| LIKE | NO | NO | NO | NO | YES |
| MATCH, MATCH_* | NO | YES | NO | NO | NO |
| array_contains | NO | YES | NO | NO | NO |
| array_overlaps | NO | YES | NO | NO | NO |
| is_ip_address_in_range | NO | YES | NO | NO | NO |
倒排索引
创建倒排索引
-- 语法 1
CREATE INDEX idx_name ON table_name(column_name) USING INVERTED [PROPERTIES(...)] [COMMENT 'your comment'];
-- 语法 2
ALTER TABLE table_name ADD INDEX idx_name(column_name) USING INVERTED [PROPERTIES(...)] [COMMENT 'your comment'];
历史存量数据生成倒排索引
-- 语法 1,默认给全表的所有分区 BUILD INDEX
BUILD INDEX index_name ON table_name;
-- 语法 2,可指定 Partition,可指定一个或多个
BUILD INDEX index_name ON table_name PARTITIONS(partition_name1, partition_name2);
查看索引生成进度
SHOW BUILD INDEX [FROM db_name];
-- 示例 1,查看所有的 BUILD INDEX 任务进展
SHOW BUILD INDEX;
-- 示例 2,查看指定 table 的 BUILD INDEX 任务进展
SHOW BUILD INDEX where TableName = "table1";
索引语法
idx_name(column_name)是必须的,column_name代表你建立的的那一列的索引,idx_name是索引的名字,表内唯一。- **
USING INVERTED**是必须的,用于指定索引类型是倒排索引 COMMENT是可选的,指定索引注释PROPERTIES是可选的,指定倒排索引的额外属性- lower_case:是否将分词进行小写转换,在匹配时忽略大小写
- 其他请看官网
BloomFilter 索引
BloomFilter 索引能够对等值查询(包括 = 和 IN)加速,对高基数字段效果较好,比如 userid 等唯一 ID 字段
建表时创建 BloomFilter 索引,可以指定多个列
PROPERTIES (
"bloom_filter_columns" = "column_name1,column_name2"
);
已有表增加 BloomFilter 索引
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name1,column_name2,column_name3"
已有表删除 BloomFilter 索引
ALTER TABLE table_name SET ("bloom_filter_columns" = "column_name2,column_name3");
Schema 变更(表结构修改)
Doris的表结构操作时,根据操作类型的不同,分为轻量级和重量级,主要区别在执行速度、资源消耗、执行过程复杂性上。
| 特性 | 轻量级 Schema Change | 重量级 Schema Change |
|---|---|---|
| 执行速度 | 秒级(几乎实时) | 分钟级、小时级、天级(依赖表的数据量,数据量越大,执行越慢) |
| 是否需要数据重写 | 不需要 | 需要,涉及数据文件的重写 |
| 系统性能影响 | 影响较小 | 可能影响系统性能,尤其是在数据转换过程中 |
| 资源消耗 | 较低 | 较高,会占用计算资源重新组织数据,过程中涉及到的表的数据占用的存储空间翻倍。 |
| 操作类型 | 增加、删除 Value 列,修改列名,修改 VARCHAR 长度 | 修改列的数据类型、更改主键、修改列的顺序等 |
数据查询
数据类型
| 类型 | 取值范围 |
|---|---|
| Boolean | 0 代表 false,1 代表 true |
| Tinyint | -128 ~ 127 |
| Smallint | -32768 ~ 32767 |
| int | -2147483648~ 2147483647 |
| Bigint | -2^63 ~ 2^63-1 |
| LARGEINT | -2^127 ~ 2^127-1 |
| Decimal | 默认值:Decimal(9, 0) |
| Float/Double | |
| Date | ['0000-01-01', '9999-12-31'] |
| DateTime | 范围:['0000-01-01 00:00:00[.000000]', '9999-12-31 23:59:59[.999999]'] - 格式:YYYY-MM-DD hh:mm.fraction |
| Char | 1-255 |
| Varchar | 1-65535 |
| String | 1048576 字节(1MB),可调大到 2147483643 字节(2G) |
| JSON | |
| HyperLogLog | 不能做key列 |
| BITMAP | 不能做key列 |
| QUANTILE_STATE | 不能做key列 |
| Array | 不能做key列 |
| MAP<K, V> | 不能做key列 |
| STRUCT<field_name:field_type, ... > | 不能做key列 |
| Agg_State | 不能做key列 |
'AGG_STATE', 'ALL', 'ARRAY', 'BIGINT', 'BITMAP', 'BOOLEAN', 'CHAR', 'DATE', 'DATETIME', 'DATETIMEV2', 'DATEV2', 'DATETIMEV1', 'DATEV1', 'DECIMAL', 'DECIMALV2', 'DECIMALV3', 'DOUBLE', 'FLOAT', 'HLL', 'INT', 'INTEGER', 'IPV4', 'IPV6', 'JSON', 'JSONB', 'LARGEINT', 'MAP', 'QUANTILE_STATE', 'SMALLINT', 'STRING', 'STRUCT', 'TEXT', 'TIME', 'TINYINT', 'VARCHAR', 'VARIANT'
分组查询
在数据库中,ROLLUP、CUBE 和 GROUPING SETS 是用于多维数据聚合的高级 SQL 语句。
- ROLLUP:ROLLUP 是一种用于生成层次化汇总的操作。它按照指定的列顺序进行汇总,从最细粒度的数据逐步汇总到最高层次。
- CUBE:CUBE 是一种更为强大的聚合操作,它生成所有可能的汇总组合。与 ROLLUP 不同,CUBE 会计算所有维度的子集。
- GROUPING SETS:GROUPING SETS 提供了对特定分组集进行聚合的灵活性。它允许用户指定一组列的组合进行独立聚合,而不是像 ROLLUP 和 CUBE 那样生成所有可能的组合。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号