keycloak~容器重启的分析
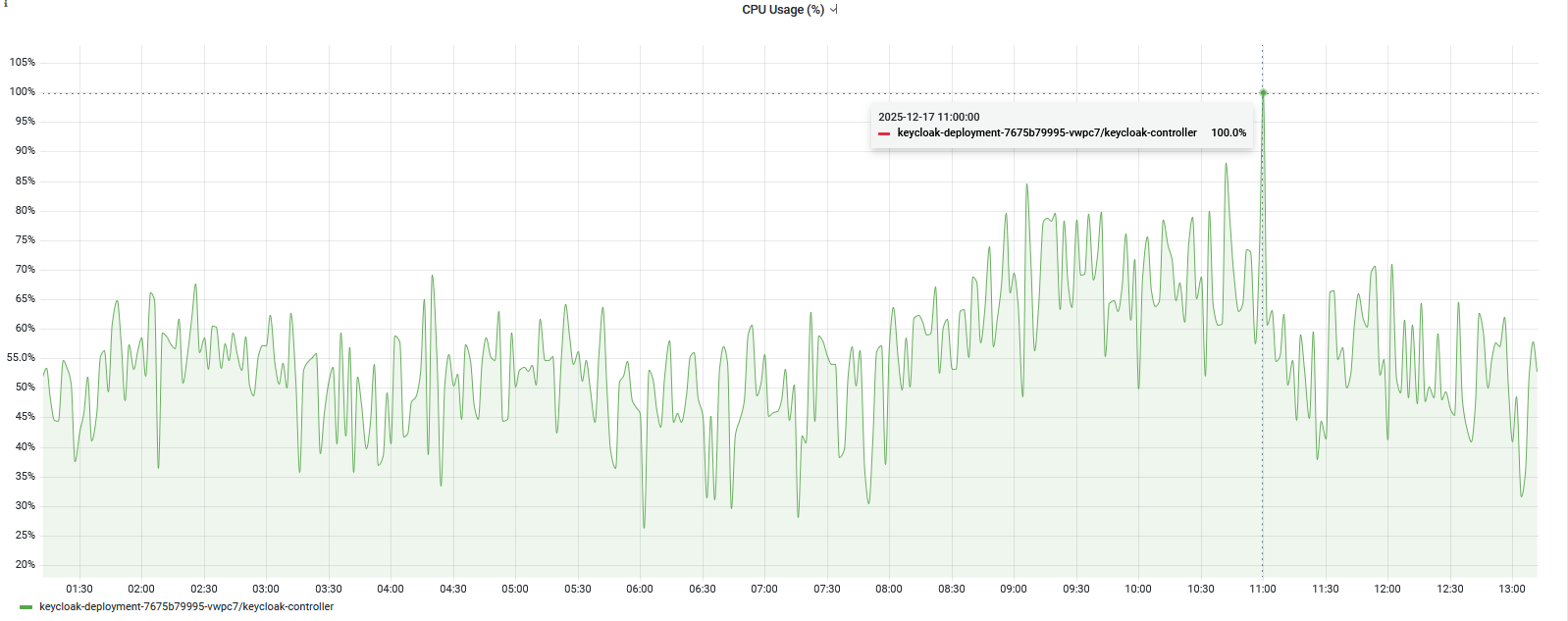
观察重启时刻的CPU情况
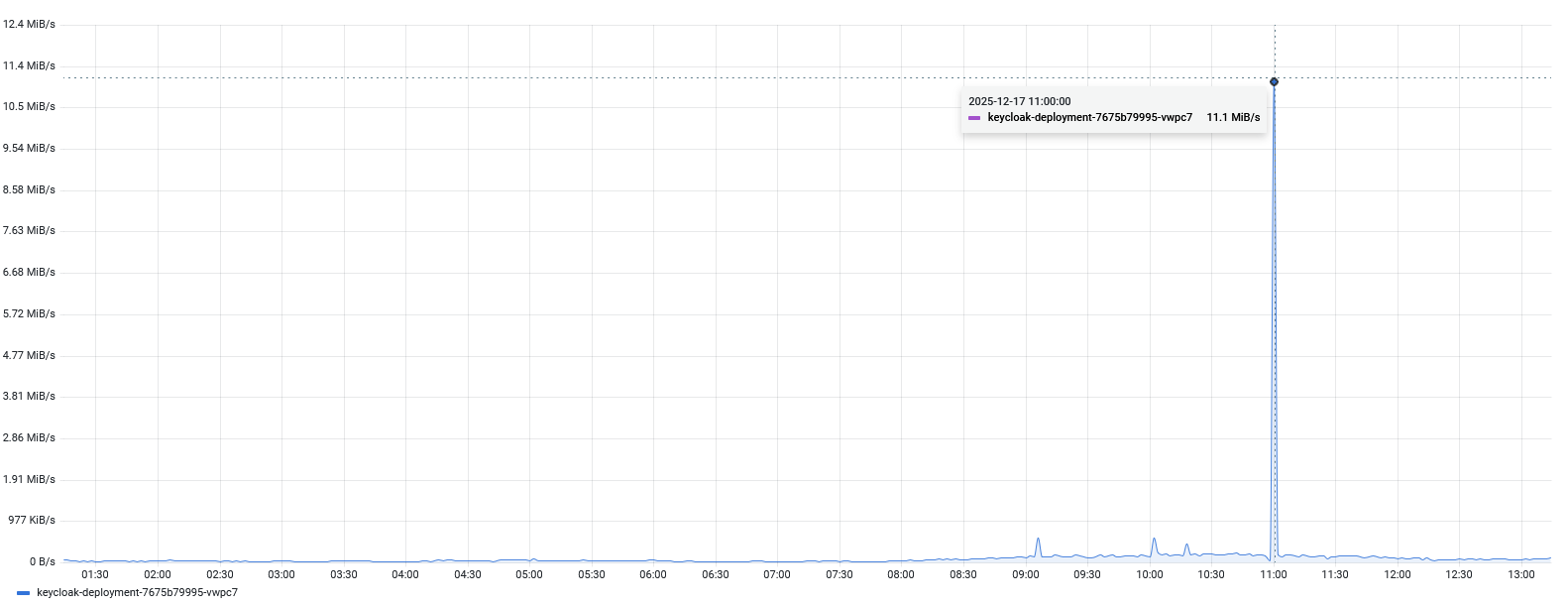
观察网络情况
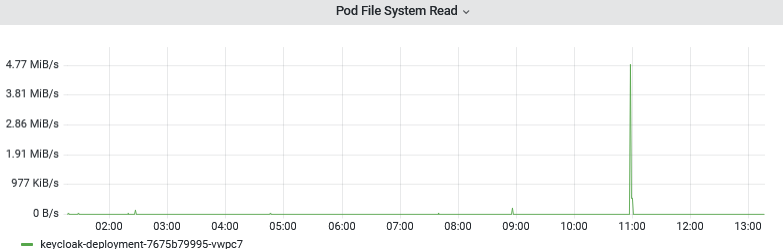
文件IO读
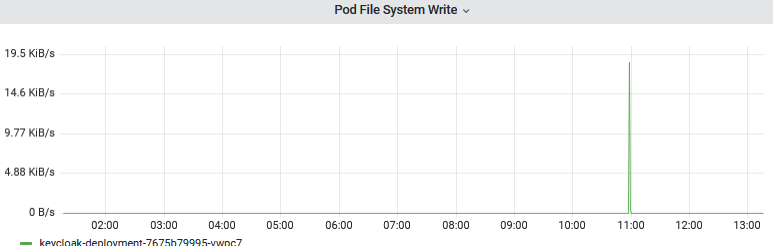
文件IO写
分析
感觉应该是有大量日志写入日志文件,导致文件IO过高,从而导致CPU过高,容器导致重启;后续将文件日志改为stdout标准输出,进行观察
1. 为什么高文件IO会导致CPU升高
- A. 系统调用开销
- 每次文件读写都需要从用户态切换到内核态
- 频繁的系统调用会消耗大量CPU时间
- B. 内核处理开销
- 文件系统元数据操作(inode更新、目录查找)
- 页缓存管理(内存页面分配、回收)
- 块设备I/O调度和队列管理
- C. JVM/应用程序开销
- 文件读写缓冲区的创建和销毁
- 字符编码/解码(特别是文本文件)
- 加锁/解锁操作(多线程访问文件时)
建议和优化
是的,文件IO非常高时,确实会导致容器CPU升高。这是一个常见的性能问题,尤其在K8s环境中更为明显。以下是详细解释:
1. 为什么高文件IO会导致CPU升高
A. 系统调用开销
- 每次文件读写都需要从用户态切换到内核态
- 频繁的系统调用会消耗大量CPU时间
B. 内核处理开销
- 文件系统元数据操作(inode更新、目录查找)
- 页缓存管理(内存页面分配、回收)
- 块设备I/O调度和队列管理
C. JVM/应用程序开销
- 文件读写缓冲区的创建和销毁
- 字符编码/解码(特别是文本文件)
- 加锁/解锁操作(多线程访问文件时)
2. 在容器环境中的额外开销
A. 存储驱动开销
# 不同存储驱动的CPU开销(从低到高)
vfs (最高CPU开销) > overlay2 > aufs > devicemapper > zfs
B. 文件系统层开销
- OverlayFS:多层文件系统的合并操作
- 写时复制(CoW):每次写操作可能涉及复制整个文件
C. 网络存储额外开销
如果使用网络存储(NFS、Ceph、EBS等):
网络协议栈处理: 协议解析、加密/解密、压缩/解压
网络I/O中断: 频繁的中断处理消耗CPU
3. Java应用程序特有的IO问题
A. 同步阻塞IO
// 传统阻塞IO - 高CPU消耗
try (BufferedReader br = new BufferedReader(new FileReader(file))) {
String line;
while ((line = br.readLine()) != null) { // 每次readLine都是系统调用
// 处理逻辑
}
}
B. 不恰当的缓冲区设置
// 小缓冲区导致频繁系统调用
FileInputStream fis = new FileInputStream(file);
byte[] buffer = new byte[1024]; // 太小了!
while (fis.read(buffer) != -1) {
// 每次只读1KB,需要多次系统调用
}
C. 日志记录不当
// 过度日志记录
logger.debug("Processing item: " + item + " with details: " + details); // 字符串拼接
// 应该使用
if (logger.isDebugEnabled()) {
logger.debug("Processing item: {} with details: {}", item, details);
}
4. K8s环境中的诊断方法
A. 监控指标
# 查看容器CPU使用
kubectl top pods
# 查看节点IO压力
kubectl describe nodes | grep -A 10 "Allocated resources"
# 进入容器查看
kubectl exec -it <pod-name> -- bash
B. 使用监控工具
# Prometheus + Grafana 监控
io_rate: rate(node_disk_read_bytes_total[5m]) + rate(node_disk_written_bytes_total[5m])
cpu_usage: rate(container_cpu_usage_seconds_total[5m]) * 100
C. 诊断命令
# 查看进程IO情况
kubectl exec <pod-name> -- iotop -o -P
# 查看系统调用
kubectl exec <pod-name> -- strace -c -p <pid>
# 查看文件描述符
kubectl exec <pod-name> -- lsof -p <pid>
ls -la /proc/<pid>/fd/
5. 优化建议
A. 应用程序优化
// 1. 使用合适的缓冲区
private static final int BUFFER_SIZE = 8192; // 8KB缓冲区
try (BufferedInputStream bis = new BufferedInputStream(
new FileInputStream(file), BUFFER_SIZE)) {
// 处理
}
// 2. 异步IO(Java NIO.2)
Path path = Paths.get("largefile.txt");
AsynchronousFileChannel channel = AsynchronousFileChannel.open(path, READ);
ByteBuffer buffer = ByteBuffer.allocate(8192);
Future<Integer> result = channel.read(buffer, 0);
// 3. 使用内存映射文件
FileChannel channel = FileChannel.open(path, StandardOpenOption.READ);
MappedByteBuffer buffer = channel.map(
FileChannel.MapMode.READ_ONLY, 0, channel.size());
B. JVM优化
# 调整JVM参数
-Xms2g -Xmx2g # 避免频繁GC导致IO停顿
-XX:+UseG1GC # G1垃圾收集器对IO密集型应用更友好
-XX:MaxGCPauseMillis=200
-XX:+UseStringDeduplication # 减少字符串内存占用
C. 容器配置优化
apiVersion: v1
kind: Pod
metadata:
name: high-io-app
spec:
containers:
- name: app
image: myapp:latest
resources:
limits:
cpu: "2"
memory: "4Gi"
requests:
cpu: "1"
memory: "2Gi"
# 设置合适的CPU调度策略
securityContext:
sysctls:
- name: net.core.somaxconn
value: "1024"
# 挂载优化后的存储
volumeMounts:
- mountPath: /data
name: data-volume
volumes:
- name: data-volume
emptyDir:
medium: Memory # 使用tmpfs内存文件系统
sizeLimit: 1Gi
D. 文件系统优化
# 选择合适的存储类
kind: StorageClass
apiVersion: storage.k8s.io/v1
metadata:
name: fast-ssd
provisioner: kubernetes.io/aws-ebs
parameters:
type: gp3 # 使用SSD存储
iops: "3000"
throughput: "125"
# 或使用本地SSD
volumes:
- name: local-ssd
hostPath:
path: /mnt/ssd
type: Directory
E. 日志优化
# 使用异步日志框架
dependencies:
- logback-classic
- disruptor # Logback异步日志
# logback.xml配置
<appender name="ASYNC" class="ch.qos.logback.classic.AsyncAppender">
<queueSize>1024</queueSize>
<discardingThreshold>0</discardingThreshold>
<appender-ref ref="FILE" />
</appender>
6. 紧急应对措施
A. 临时缓解
# 1. 调整进程优先级
kubectl exec <pod-name> -- renice -n 10 -p <pid>
# 2. 限制IO带宽
kubectl exec <pod-name> -- ionice -c 2 -n 7 -p <pid>
# 3. 临时增加CPU限制
kubectl patch pod <pod-name> -p '{"spec":{"containers":[{"name":"app","resources":{"limits":{"cpu":"4"}}}]}}'
总结
在K8s容器中,高文件IO确实会导致CPU升高,主要原因包括:
- 系统调用频繁
- 内核处理开销
- 容器存储驱动开销
- JVM应用程序自身开销
作者:仓储大叔,张占岭,
荣誉:微软MVP
QQ:853066980
支付宝扫一扫,为大叔打赏!


 浙公网安备 33010602011771号
浙公网安备 33010602011771号