MPP



###################################
MPP on HDFS
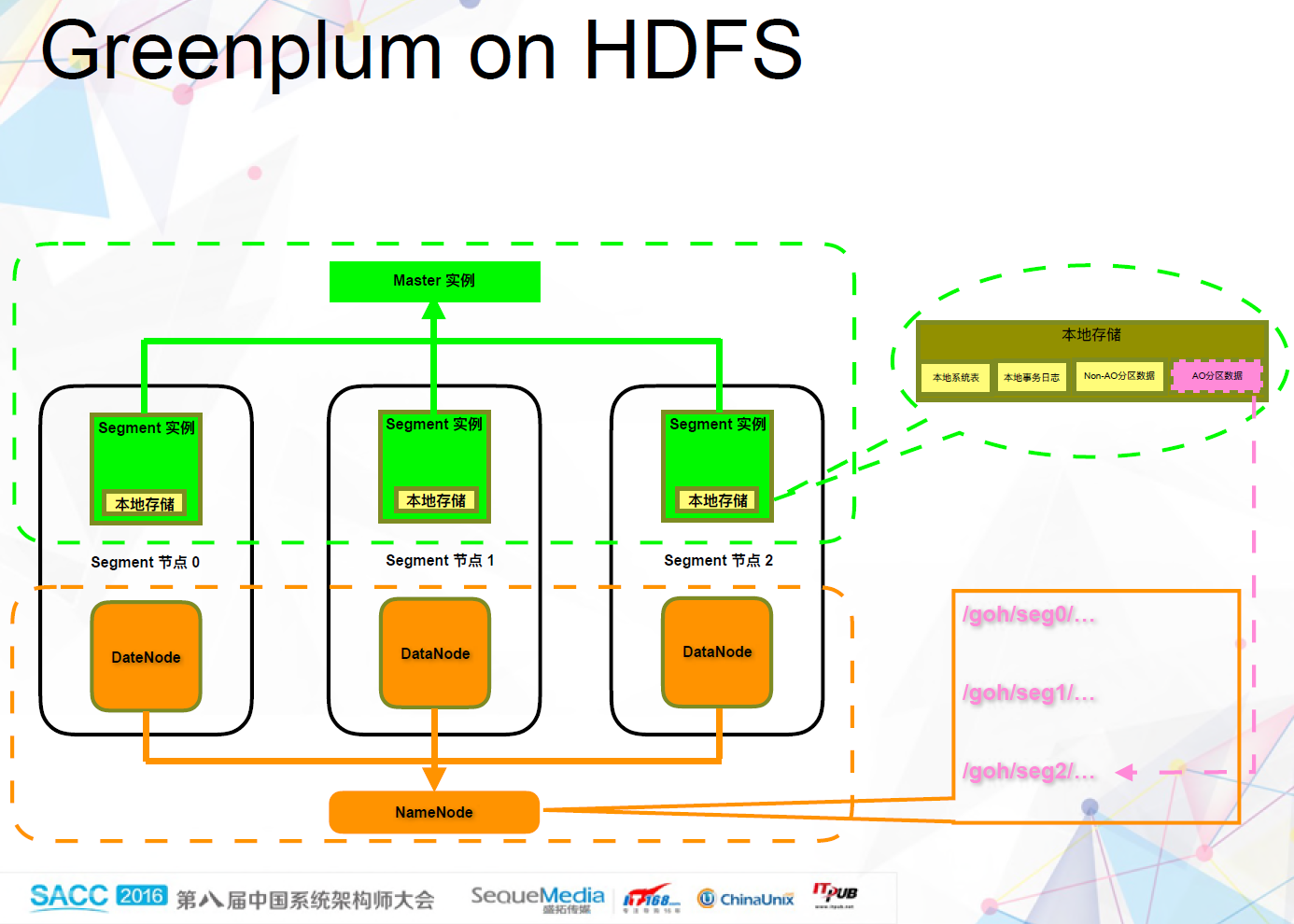
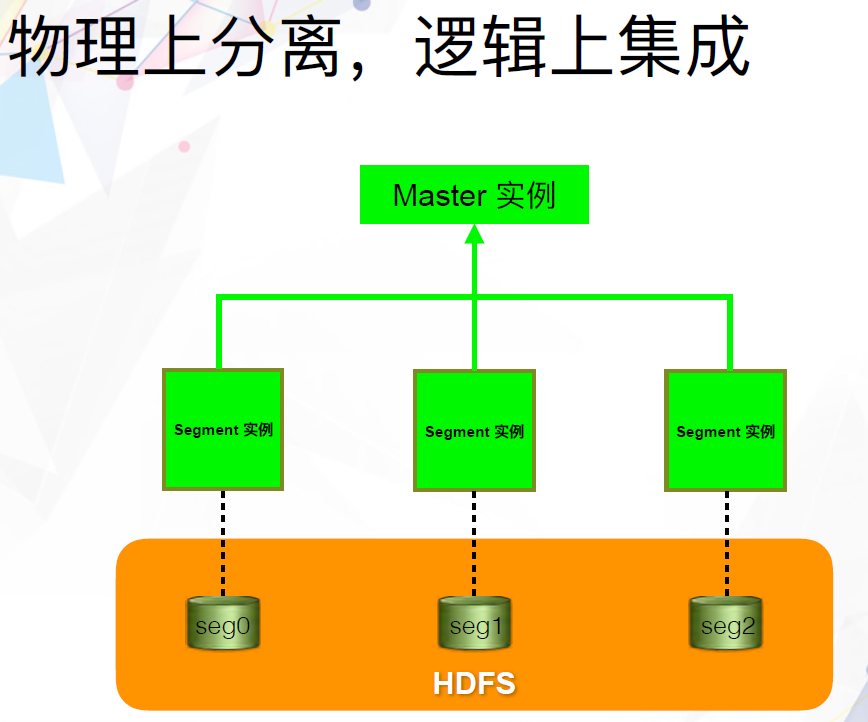
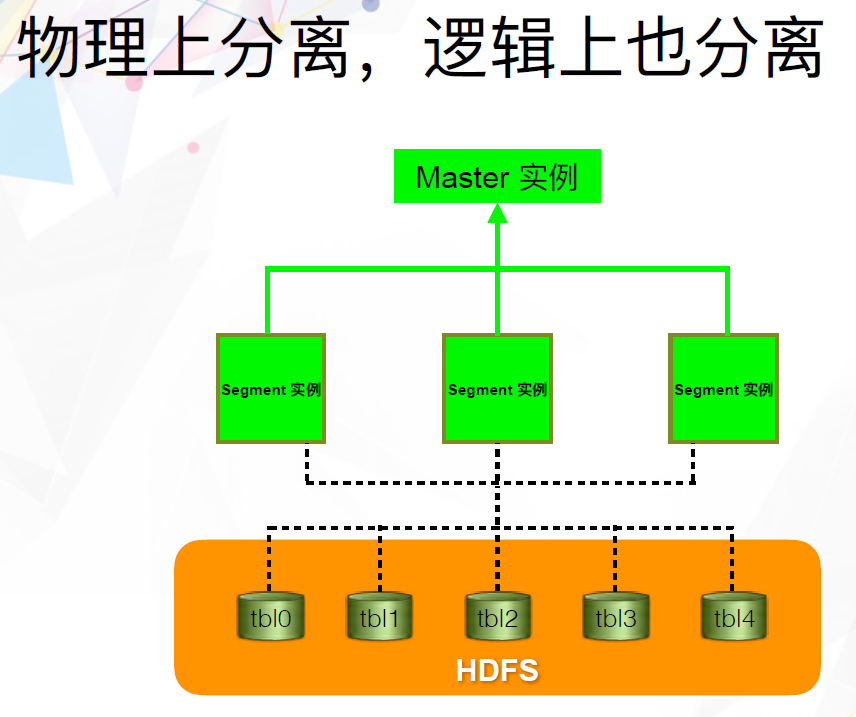
我们当时的想法是将Greenplum Database跟HDFS结合起来。与其他基于connector连接器的方式不同,我们希望让HDFS,而不是本地存储,成为MPP数据库的数据持久层。这就是后来的Apache HAWQ项目。但在当时,我们把它叫做Greenplum on Hadoop,其实更准确的说法应该是,Greenplum on HDFS。当时的想法非常简单,就是将Greenplum Database和HDFS部署在同一个物理机器集群中,同时将Greenplum Database中的Append-only表的数据放到HDFS上面。Append-only表指的是只能追加,不能更新和删除的表,这是因为HDFS本身只能Append的属性决定的。
除了Append-only表之外,Greenplum Database还支持Heap表,这是一种能够支持增删改查的表类型。结合前面提到的Segment实例的本地状态,我们可以将本地存储分成四大类:系统表、日志、Append-only表分区数据和非Append-only表分区数据。我们将其中的Append-only表分区数据放到了HDFS上面。每个Segment实例对应一个HDFS的目录,非常直观。其它三类数据还是保存在本地的磁盘中。
总体上说,相对于传统的Greenplum Database, Greenplum on HDFS架构上并没有太多的改动,只是将一部分数据从本地存储放到了HDFS上面,但是每个Segment实例还是需要通过本地存储保存本地状态数据。所以,从高可用性的角度看,我们还是需要为每个实例提供备份,只是需要备份的数据少了,因为Append-only表的数据现在我们是通过HDFS本身的高可用性提供的。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号