前端数据结构--线性结构-数组
线性结构
线性结构是一个有序数据元素的集合,数据之间的关系是1:1 的关系如:

平时常用的线性结构有数组、线性表、栈、队列 如。
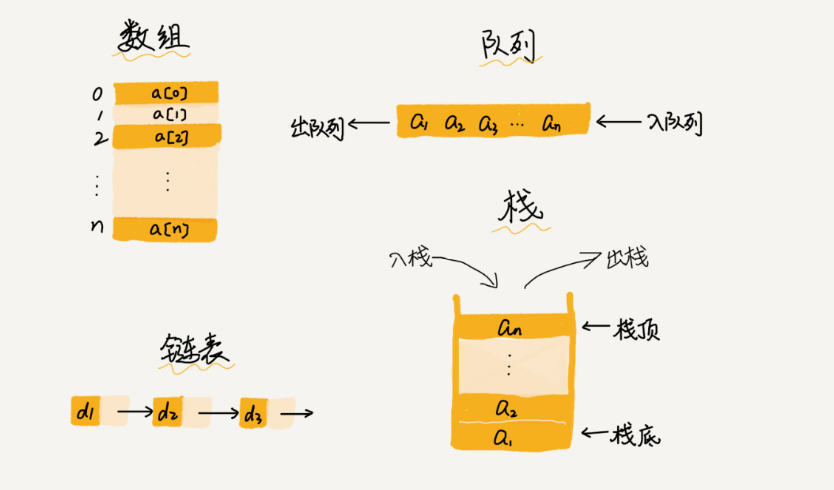
什么是数组
数组是计算机分配一块连续的内存空间,来存储具有相同元素类型的数据。数组具有随机访问的特点,这个特点有利有弊,比如可以根据数组下标快速的访问元素,但是要想在数组中删除、插入一个数据,为了保证连续性,就需要做大量的数据移动。
特点
- 数组是一种线性表结构,即就像数据排成一条线一样的结构,每个线性表上的数据最多只有前和后
- 连续的内存空间和相同类型的数据
数组如何实现随机访问
数组在内存中地址是连续、以及相同的数据类型,所以我们只要知道内存首地址以及数据类型的大小,就能知道对应索引的元素地址,如一个长度为 10 的 int 类型的数组 int[] a = new int[10]来举例。在这个图中,计算机给数组 a[10],分配了一块连续内存空间 1000~1039,其中,内存块的首地址为 base_address = 1000。

计算机会给每个内存单元分配一个地址,计算机通过地址来访问内存中的数据。当计算机需要随机访问数组中的某个元素时,它会首先通过下面的寻址公式,计算出该元素存储的内存地址:
1 // 首地址 + 需要访问的下标的偏移值 2 a[i]_address = base_address + i * data_type_size
其中 data_type_size 表示数组中每个元素的大小。举的这个例子里,数组中存储的是 int 类型数据,所以 data_type_size 就为 4 个字节。
因为数组是连续存储的,所以根据首地址和下标,通过寻址公式就能直接计算出对应的内存地址,找出数据。
1 // 访问第三个元素的地址 2 a[3] = 1000 + (3 - 1) * 4 = 1008 - 1011
数组的下标为什么要从0开始
根据上面数组寻址公式,因为地址是连续、且数据类型是相同的,所以下标其实就是一个偏移值,如果用a来表示数组的首地址,那么a[0]就是偏移为0的位置,也就是首地址,a[x]就是表示偏移x个type_size的位置所以计算 a[k]的内存地址只需要用这个公式:
1 a[x]_address = base_address + x * type_size
但是,如果数组从 1 开始计数,那我们计算数组元素 a[k]的内存地址就会变为:
1 a[x]_address = base_address + (k-1) * type_size
对比两个公式,如果从 1 开始编号,每次随机访问数组元素都多了一次减法运算,对于 CPU 来说,就是多了一次减法指令。数组作为非常基础的数据结构,通过下标随机访问数组元素又是其非常基础的编程操作,效率的优化就要尽可能做到极致。所以为了减少一次减法操作,数组选择了从 0 开始编号,而不是从 1 开始。
javaScript 中的数组
JavaScript 中的数组有很多特性:存放不同类型元素、并且数组长度可变,这与数据结构中定义的数组结构或者C++、Java、C#等语言中的数组不太一样,那么JS数组的这些特殊的特性底层是如何实现的呢?可以理解为V8中对数组做了一层封装,使其有两种实现方式:快数组和慢数组,快数组底层是连续内存,通过索引直接定位,慢数组底层是哈希表,通过计算哈希值来定位。具体的可以看看这个《探究JS V8引擎下的“数组”底层实现》
无论是慢数组、快数组被实现成了key、value对象的形式,so,检查数组类型是一个对象。
Object.prototype.toString([]) // "[object Object]"
参考:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号