CentOS7下Hadoop单节点集群的安装
一、安装JDK,并配置环境变量。因为Hadoop是以Java开发的,所以必须先安装Java环境
二、安装SSH,设置SSH无密码登录。Hadoop是由很多台服务器所组成的。当我们启动Hadoop系统时,NameNode必须与DataNode连接,并管理这些节点(DataNode)。此时系统会要求用户输入密码。为了让系统顺利运行而不需手动输入密码,就需要SSH设置成无密码登录。
注意:无密码登录登录并非不需要密码,而是以事先交换SSH Key(密钥)的方式来进行身份验证
1、安装SSH:CentOS 7 已经安装
2、安装rsync:CentOS 7 已经安装
3、产生SSH Key(密钥)进行后续身份验证:
ssh-keygen -t dsa -P '' -f ~/.ssh/id_dsa
4、查看产生的SSH Key(密钥):
ll ~/.ssh
5、将产生的Key放置到许可证文件中
cat ~/.ssh/id_dsa.pub >> ~/.ssh/authorized_keys
三、下载安装Hadoop
1、下载Hadoop-2.8.5.tar.gz并解压
2、设置Hadoop环境变量:
sudo gedit ~/.bashrc
输入以下内容:
#配置JDK安装路径
export JAVA_HOME=/usr/local/software/jdk1.8.0_211
#配置hadoop_home的安装路径
export HADOOP_HOME=/usr/local/software/hadoop
#配置PATH
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#设置hadoop其他环境变量
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
#链接库的相关设置
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export HADOOP_OPTS="-DJava.library.path=$HADOOP_HOME/lib"
export JAVA_LIBRARY_PATH=$HADOOP_HOME/lib/native:$JAVA_LIBRARY_PATH
3、让~/.bashrc设置生效:
source ~/.bashrc
4、修改Hadoop配置设置文件:
(1)在hadoop-2.8.5/etc/hadoop文件夹下的配置文件hadoop-env.sh中修改JAVA_HOME设置
export JAVA_HOME=/usr/local/software/jdk1.8.0_211
(2)在hadoop-2.8.5/etc/hadoop文件夹下设置core-site.xml:加入HDFS的默认名称
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
(3) 在hadoop-2.8.5/etc/hadoop文件夹下设置yarn-site.xml:
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name>
<value>org.apache.hadoop.mapred.ShuffleHandler</value>
</property>
</configuration>
(4)在hadoop-2.8.5/etc/hadoop文件夹下设置mapred-site.xml:
A、复制模板文件:由mapred-site.xml.template 到 mapred-site.xml
B、在mapred-site.xml设置mapreduce框架为yarn
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>
(5)在hadoop-2.8.5文件夹下创建hadoop_data文件夹,然后在 hadoop_data下创建hdfs文件夹,最后在hdfs文件夹下分别创建namenode和datanode文件夹
(6)在hadoop-2.8.5/etc/hadoop文件夹下设置hdfs-site.xml:设置HDFS分布式文件系统
<configuration>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>
file:/usr/local/software/hadoop/hadoop_data/hdfs/namenode
</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>
file:/usr/local/software/hadoop/hadoop_data/hdfs/datanode
</value>
</property>
</configuration>
5、将HDFS进行格式化:
hadoop namenode -format
6、将Hadoop目录的所有者更改为hduser(名字可变),因为Linux是多人多任务的操作系统,所有的目录或文件都具有所有者。使用chown可以将目录或文件的所有者更改为hduser
chown hduser:hduser -R /usr/local/software/hadoop
四、启动Hadoop(两种方式):
(1)分别启动HDFS、YARN
start-dfs.sh ------→启动HDFS
start-yarn.sh ------->启动YARN
(2)同时启动HDFS、YARN
start-all.sh
五、查看NameNode、DataNode进程是否启动
jps
结果为:
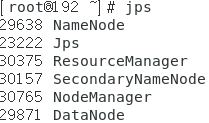
因为只有一台服务器,所以所有的功能都集中在一台服务器中
六、打开Hadoop Resource-Manager Web界面(浏览器地址栏输入:http://localhost:8088/)
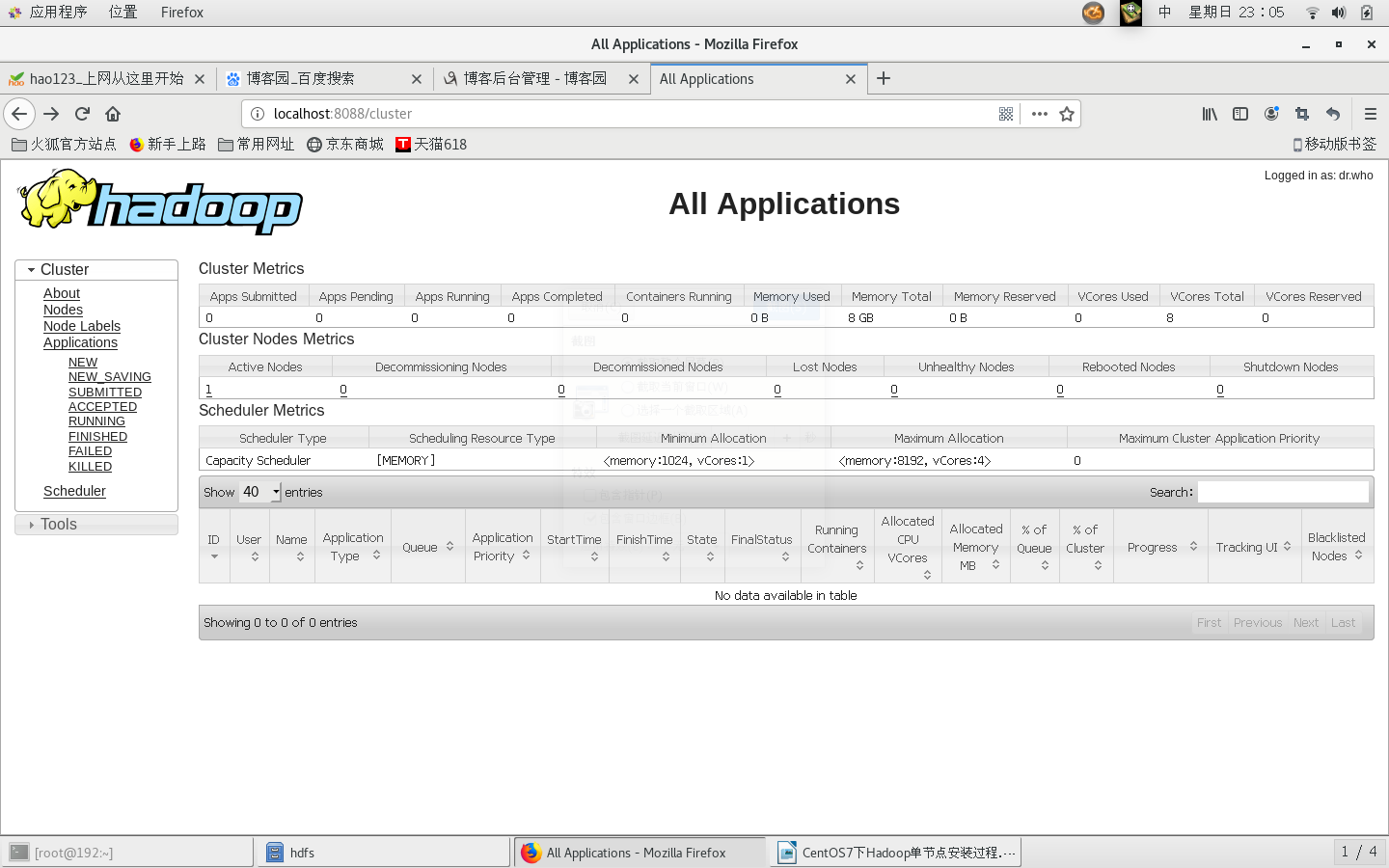
Hadoop安装配置成功!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号