
7.Spark SQL
1.请分析SparkSQL出现的原因,并简述SparkSQL的起源与发展。
随着 Spark 的不断发展, Shark 对 Hive 的重度依赖体现在架构上的瓶颈越来越突出。一方面, Hive 的语法解析和查询优化等模块本身针对的是 MapReduce ,限制了在 Spark 系统上的深度优化和维护;另一方面,过度依赖 Hive 制约了 Spark 的“One Stack Rule Them All”既定方针,也制约了技术校中各个组件的灵活集成。在此背景下, Spark SQL 项目被提出来,由 Michael Armbrust 主导开发。Spark SQL 抛弃原有 Shark 的架构方式,但汲取了 Shark 的一些优点,如内存列存储( In-Memory Columnar Storage )、 Hive 兼容性等,重新开发了 SQL 各个模块的代码。由于摆脱了对 Hive 的依赖, SparkSQL 在数据兼容、性能优化、组件扩展方面都得到了极大的提升.在 2014 年 7 月 1 日的 Spark 峰会上, Databricks 公司宣布终止对 Shark 的开发,将后续重点放到 Spark SQL 上。
2. 简述RDD 和DataFrame的联系与区别?
RDD是弹性分布式数据集,数据集的概念比较强一点。容器可以装任意类型的可序列化元素(支持泛型)RDD的缺点是无从知道每个元素的【内部字段】信息。
DataFrame也是弹性分布式数据集,但是本质上是一个分布式数据表,因此称为分布式表更准确。DataFrame每个元素不是泛型对象,而是Row对象。
DataFrame的缺点是Spark SQL DataFrame API 不支持编译时类型安全,因此,如果结构未知,则不能操作数据;同时,一旦将域对象转换为Data frame ,则域对象不能重构。
DataFrame=RDD-【泛型】+schema+方便的SQL操作+【catalyst】优化
3.DataFrame的创建
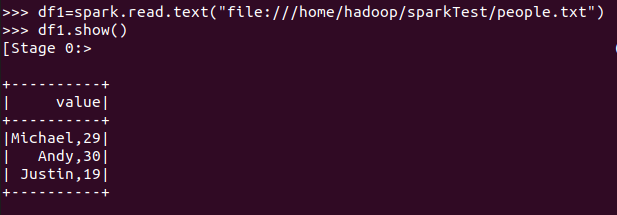
spark.read.text(url)
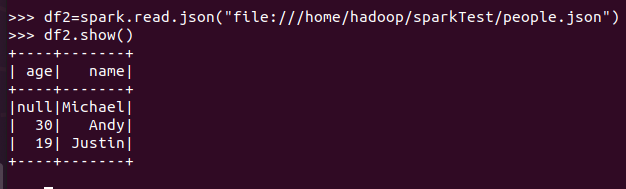
spark.read.json(url)
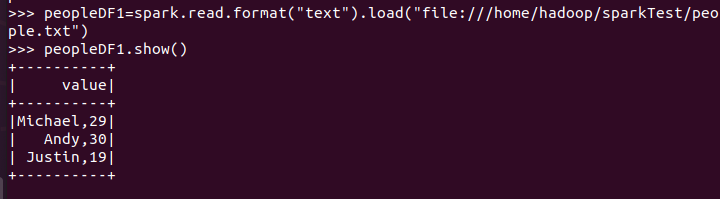
spark.read.format("text").load("people.txt")
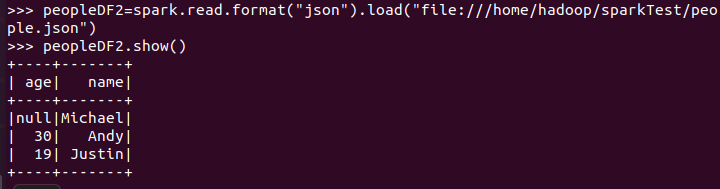
spark.read.format("json").load("people.json")
描述从不同文件类型生成DataFrame的区别。
用相同的txt或json文件,同时创建RDD,比较RDD与DataFrame的区别。


text文件生成DataFrame读出来的是一个value值,json文件生成DataFrame读的是一个实体对象
4. PySpark-DataFrame各种常用操作
基于df的操作:
打印数据 df.show()默认打印前20条数据
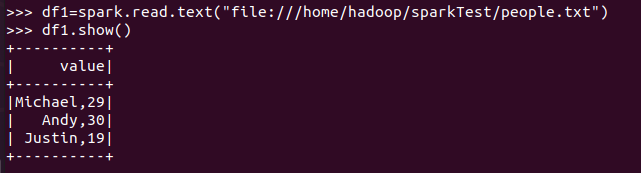
打印概要 df.printSchema()
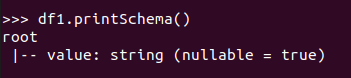
查询总行数 df.count()
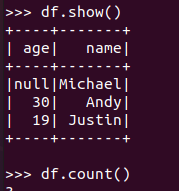
df.head(3) #list类型,list中每个元素是Row类

输出全部行 df.collect() #list类型,list中每个元素是Row类

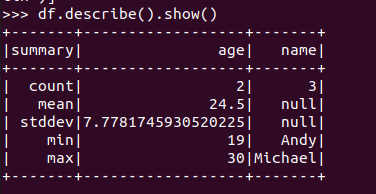
查询概况 df.describe().show()
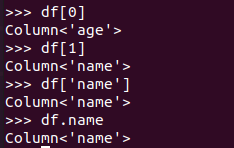
取列 df[‘name’], df.name, df[1]
基于spark.sql的操作:
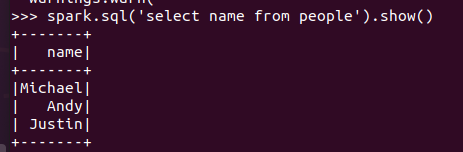
创建临时表虚拟表 df.registerTempTable('people')

spark.sql执行SQL语句 spark.sql('select name from people').show()
5. Pyspark中DataFrame与pandas中DataFrame
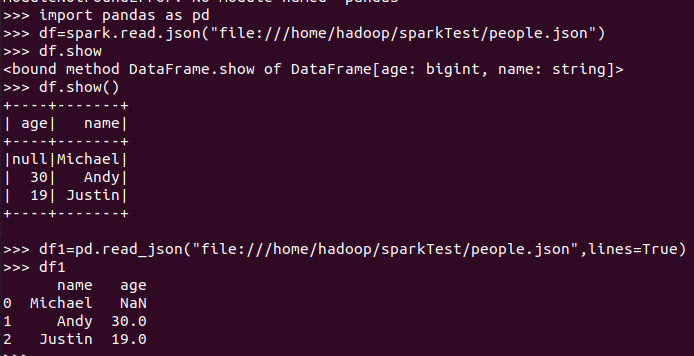
分别从文件创建DataFrame
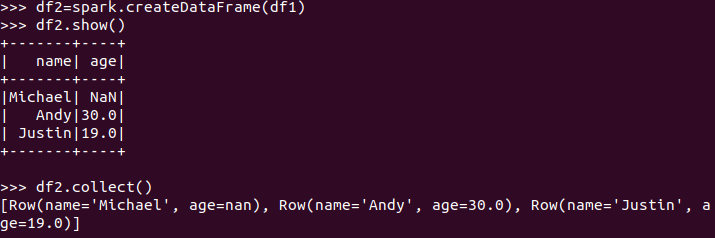
pandas中DataFrame转换为Pyspark中DataFrame
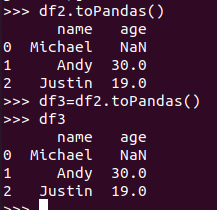
Pyspark中DataFrame转换为pandas中DataFrame
6.从RDD转换得到DataFrame
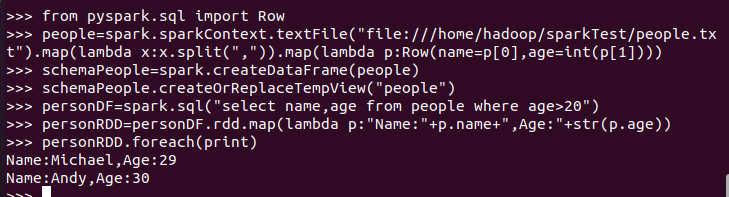
6.1 利用反射机制推断RDD模式
创建RDD sc.textFile(url).map(),读文件,分割数据项
每个RDD元素转换成 Row
由Row-RDD转换到DataFrame
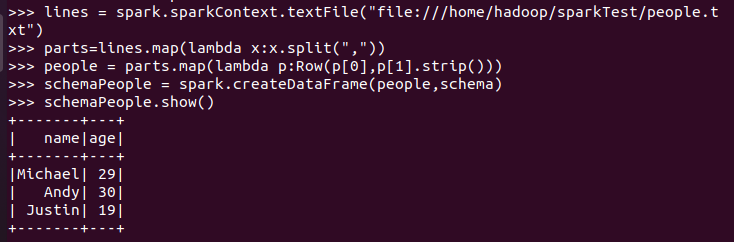
6.2 使用编程方式定义RDD模式
#下面生成“表头”
#下面生成“表中的记录”
#下面把“表头”和“表中的记录”拼装在一起

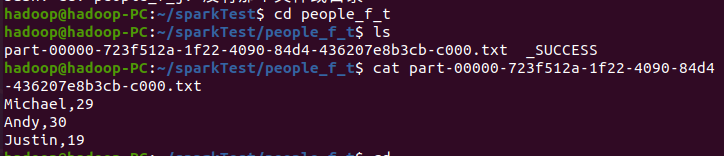
7. DataFrame的保存
df.write.text(dir)
df.write.format("text").save(dir)

df.write.json(dri)
df.write.format("json").save(dir)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号