
1.大数据概述
1.列举Hadoop生态的各个组件及其功能、以及各个组件之间的相互关系,以图呈现并加以文字描述。
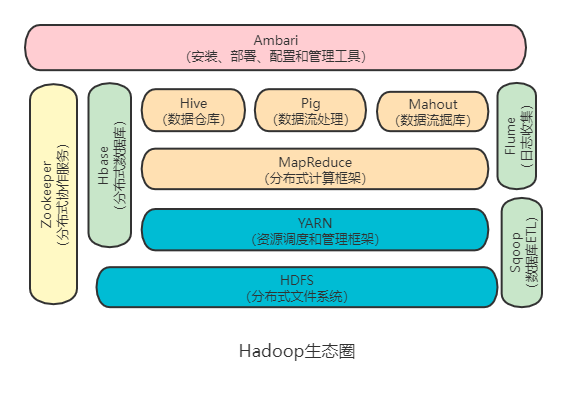
Hadoop 是一个能够对大量数据进行分布式处理的软件框架。具有可靠、高效、可伸缩的特点。
Hadoop 的核心是 HDFS 和 Mapreduce,HDFS 还包括 YARN。
1,HDFS(hadoop分布式文件系统)
HDFS是hadoop体系中数据存储管理的基础。他是一个高度容错的系统,能检测和应对硬件故障。
client:切分文件,访问HDFS,与namenode交互,获取文件位置信息,与DataNode交互,读取和写入数据。
namenode:master节点,在hadoop1.x中只有一个,管理HDFS的名称空间和数据块映射信息,配置副本策略,处理客户 端请求。
DataNode:slave节点,存储实际的数据,汇报存储信息给namenode。
secondary namenode:辅助namenode,分担其工作量:定期合并fsimage和fsedits,推送给namenode;紧急情况下和辅助恢复namenode,但其并非namenode的热备。
2,mapreduce(分布式计算框架)
mapreduce是一种计算模型,用于处理大数据量的计算。其中map对应数据集上的独立元素进行指定的操作,生成键-值对形式中间,reduce则对中间结果中相同的键的所有值进行规约,以得到最终结果。
jobtracker:master节点,只有一个,管理所有作业,任务/作业的监控,错误处理等,将任务分解成一系列任务,并分派给tasktracker。
tacktracker:slave节点,运行 map task和reducetask;并与jobtracker交互,汇报任务状态。
map task:解析每条数据记录,传递给用户编写的map()并执行,将输出结果写入到本地磁盘(如果为map—only作业,则直接写入HDFS)。
reduce task:从map 它深刻地执行结果中,远程读取输入数据,对数据进行排序,将数据分组传递给用户编写的reduce函数执行。
3, hive(基于hadoop的数据仓库)
由Facebook开源,最初用于解决海量结构化的日志数据统计问题。
hive定于了一种类似sql的查询语言(hql)将sql转化为mapreduce任务在hadoop上执行。
4,hbase(分布式列存数据库)
hbase是一个针对结构化数据的可伸缩,高可靠,高性能,分布式和面向列的动态模式数据库。和传统关系型数据库不同,hbase采用了bigtable的数据模型:增强了稀疏排序映射表(key/value)。其中,键由行关键字,列关键字和时间戳构成,hbase提供了对大规模数据的随机,实时读写访问,同时,hbase中保存的数据可以使用mapreduce来处理,它将数据存储和并行计算完美结合在一起。
5,zookeeper(分布式协作服务)
解决分布式环境下的数据管理问题:统一命名,状态同步,集群管理,配置同步等。
6,sqoop(数据同步工具)
sqoop是sql-to-hadoop的缩写,主要用于传统数据库和hadoop之间传输数据。
数据的导入和导出本质上是mapreduce程序,充分利用了MR的并行化和容错性。
7,pig(基于hadoop的数据流系统)
定义了一种数据流语言-pig latin,将脚本转换为mapreduce任务在hadoop上执行。
通常用于离线分析。
8,mahout(数据挖掘算法库)
mahout的主要目标是创建一些可扩展的机器学习领域经典算法的实现,旨在帮助开发人员更加方便快捷地创建智能应用程序。mahout现在已经包含了聚类,分类,推荐引擎(协同过滤)和频繁集挖掘等广泛使用的数据挖掘方法。除了算法是,mahout还包含了数据的输入/输出工具,与其他存储系统(如数据库,mongoDB或Cassandra)集成等数据挖掘支持架构。
9,flume(日志收集工具)
cloudera开源的日志收集系统,具有分布式,高可靠,高容错,易于定制和扩展的特点。他将数据从产生,传输,处理并写入目标的路径的过程抽象为数据流,在具体的数据流中,数据源支持在flume中定制数据发送方,从而支持收集各种不同协议数据。
10,资源管理器(YARN和mesos)
随着互联网的高速发展,基于数据 密集型应用 的计算框架不断出现,从支持离线处理的mapreduce,到支持在线处理的storm,从迭代式计算框架到 流式处理框架s4,...,在大部分互联网公司中,这几种框架可能都会采用,比如对于搜索引擎公司,可能的技术方法如下:网页建索引采用mapreduce框架,自然语言处理/数据挖掘采用spark,对性能要求到的数据挖掘算法用mpi等。公司一般将所有的这些框架部署到一个公共的集群中,让它们共享集群的资源,并对资源进行统一使用,这样便诞生了资源统一管理与调度平台,典型的代表是mesos和yarn。
2.对比Hadoop与Spark的优缺点。
Hadoop的优点:
1、Hadoop具有按位存储和处理数据能力的高可靠性。
2、Hadoop通过可用的计算机集群分配数据,完成存储和计算任务,这些集群可以方便地扩展到数以千计的节点中,具有高扩展性。
3、Hadoop能够在节点之间进行动态地移动数据,并保证各个节点的动态平衡,处理速度非常快,具有高效性。
4、Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配,具有高容错性。
Hadoop的缺点:
1、Hadoop不适用于低延迟数据访问。
2、Hadoop不能高效存储大量小文件。
3、Hadoop不支持多用户写入并任意修改文件。
Spark的优点:
1、快,与 Hadoop 的 MapReduce 相比,Spark 基于内存的运算要快 100 倍以上,基于硬盘的运算也要快 10 倍以上。Spark 实现了高效的 DAG 执行引擎,可以通过基于内存来高效处理数据流。
2、易用,Spark 支持 Java、Python 和 Scala 和 R 的 API,还支持超过 80 种高级算法,使用户可以快速构建不同的应用。而且 Spark 支持交互式的 Python 和 Scala 的 shell,可以非常方便地在这些 shell 中使用 Spark 集群来验证解决问题的方法。
3、丰富的操作算子。
4、支持的场景多,支持批处理、实时处理 Spark Streaming、机器学习 Mllib、图计算 Graphx,各种处理可以在同一个应用中无缝隙使用。
5、生态完善、社区活跃。
Spark的缺点:
1、流式计算不如flink
2.3版本以前spark的流式计算是将流数据当成小批量的数据(Micro-batch)进行处理,延迟较高,通常大于百毫秒级别;
2.3版本以后开始支持连续处理模型(类flink), 但功能不如flink全。
2、资源消耗较高,spark是基于内存计算,因此对资源的要求较高,尤其是内存;
当从hdfs上读取很多小文件生成rdd时,rdd元数据会占用较多内存。
3.如何实现Hadoop与Spark的统一部署?
因为Hadoop MapReduce、HBase、Storm和Spark等都可以运行在资源管理框架YARN之上,因此,可以在YARN之上进行统一部署。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号