
结对项目
作业要求
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 软件工程 |
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 四则运算生成器项目+合作完成结对项目 |
作业所在Github地址
结对项目成员(学号)
- 黄炜恒:3118005365
- 陈伟升:3118005358
项目需求分析
通过研究题目需求,用思维导图形式分析项目需求如下
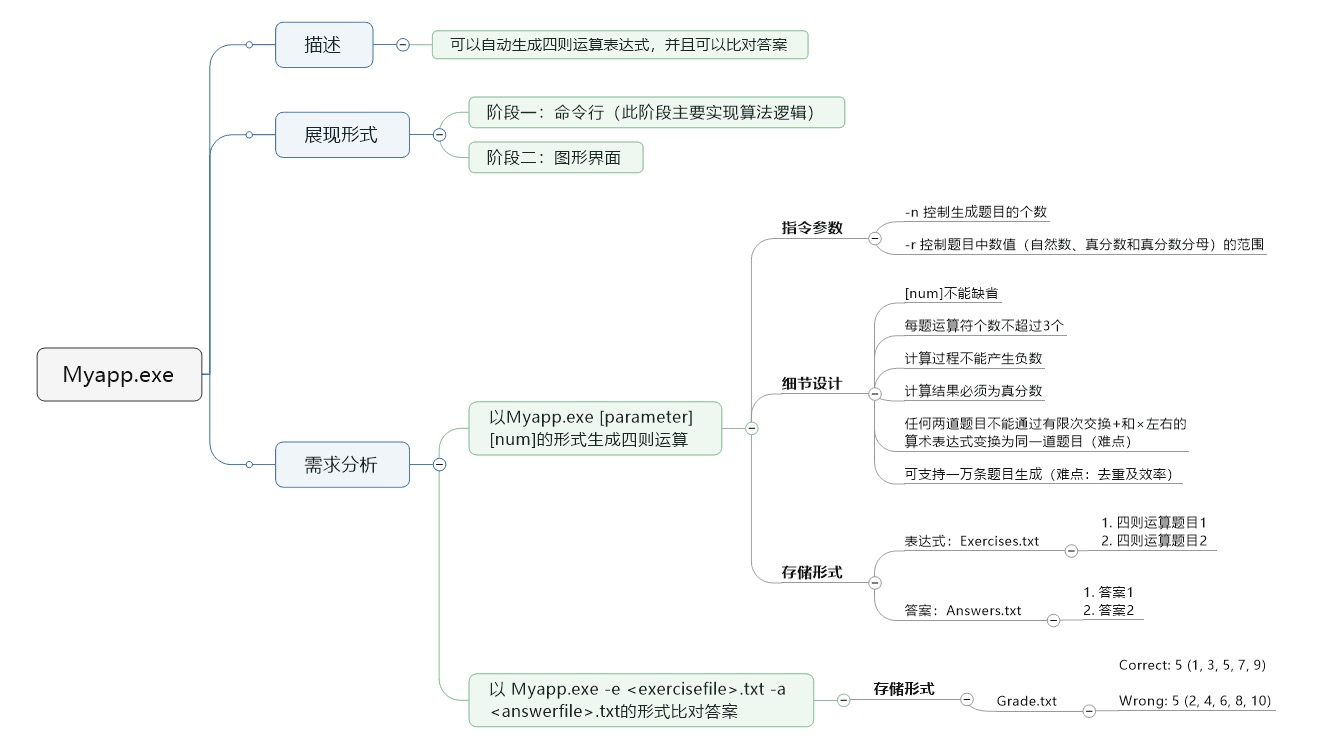
项目思路分析及相应代码
生成表达式的原理及思路
# 表达式列表形式
['10', '÷', '(', '8/9', '÷', '51', ')']
通过分析及思考,采用了多线程的形式,具体形式如下:
- 创建生产者线程, 传参进队列 'queue'
producer = multiprocessing.Process(target=self.expression_generator, args=(queue,))
- 创建消费者进程, 传参进队列 'queue'
consumer = multiprocessing.Process(target=self.io_operation, args=(queue,))
-
生产者——循环生成表达式 及其答案
- 构建随机表达式 以及生成其答案 ' Arithmetic(self.domain).create_arithmetic() '
- 生成其表达式对应答案 ' Calculate(expression).cal_expression() '
- 将生成后缀表达式过程中每次的结果 以及操作符集合 保存到 字典 (' self.no_repeat_dict ' ) 中, 从而确保生成等式不相同 (即 3+2+1 与 1+2+3 不相等, 6×8 与 8×6 相等)
- 生成完成后, 把表达式 以及 答案添加到队列 queue 中
-
消费者——循环生成表达式 及其答案
- 通过死循环不断获取队列内容, 若队列传出 'None' 信号, 消费者进程停止
- 解析从队列获取的内容, 并将多次获取的表达式以及答案保存到 缓冲区(Buffer) 中, 有限次数后开始写入文件 并 销毁缓冲区内容
综上所述,可得生成表达式的思路如下:
- 随机生成操作数列表,运算符列表
- 根据以上两个列表构建无括号表达式
- 根据运算符个数,随机生成括号个数,最大个数为( 1->0, 2->1, 3->2 )
- 再随机括号位置,维护操作数位置列表,插入括号
代码实现
# 生成表达式
def create_arithmetic(self):
# 生成随机操作数、运算符列表
self.create_operand_list()
self.create_operator_list()
i = 0
# 构建表达式列表
self.expression_split.append(self.operand_list[i])
self.expression_split.append(self.operator_list[i])
i += 1
while i < len(self.operator_list):
self.expression_split.append(self.operand_list[i])
self.expression_split.append(self.operator_list[i])
i += 1
self.expression_split.append(self.operand_list[i])
# 插入括号
if self.operator_num != 1:
bracket_num = random.randint(1, self.operator_num - 1)
self.insert_bracket(bracket_num)
# 删除无用括号
self.del_useless_bracket()
return [self.expression_split, self.operand_list, self.operator_list]
生成并计算后缀表达式原理及思路
生成后缀表达式
1.设置两个栈,一个用以存储运算符,一个用以存储后缀表达式
2.循环遍历表达式列表,如果是操作数,则加入后缀栈
3.否则如果是运算符则进入以下判断
- 如果运算符栈为空,或者栈顶为 ( ,则压入运算符栈
- 否则如果当前运算符大于栈顶运算符的优先级,则压入运算符栈
- 否则弹栈并压入后缀栈直到优先级大于栈顶或空栈
4.否则如果遇到括号则进入以下判断
- 若为 ( 直接压入运算符栈
- 否则弹栈并压入后缀栈直到遇到 (
5.将运算符栈剩余的元素压入后缀栈
计算后缀表达式
1.用一个栈(calculate_stack)作为计算中介
2.循环遍历后缀表达式,若为数字压入calculate_stack
3.否则从 calculate_stack弹出两个数字,分别化为分数类,进行计算,结果压入 calculate_stack
4.重复 2-3,若期间运算结果出现负数,或除数为0,则返回false
5.直至后缀表达式遍历完成,返回 calculate_stack 的栈顶
代码实现
class Calculate(object):
def __init__(self, expression):
self.expression = expression
# 分数加法 a1/b1 + a2/b2 = (a1b2 + a2b1)/b1b2
@staticmethod
def fraction_add(fra1, fra2):
molecular = fra1.molecular * fra2.denominator + fra2.molecular * fra1.denominator
denominator = fra1.denominator * fra2.denominator
return Fraction(molecular, denominator)
# 分数减法 a1/b1 - a2/b2 = (a1b2 - a2b1)/b1b2
@staticmethod
def fraction_minus(fra1, fra2):
molecular = fra1.molecular * fra2.denominator - fra2.molecular * fra1.denominator
denominator = fra1.denominator * fra2.denominator
return Fraction(molecular, denominator)
# 分数乘法 a1/b1 * a2/b2 = a1a2/b1b2
@staticmethod
def fraction_multiply(fra1, fra2):
molecular = fra1.molecular * fra2.molecular
denominator = fra1.denominator * fra2.denominator
return Fraction(molecular, denominator)
# 分数除法 a1/b1 ÷ a2/b2 = a1b2/a2b1
@staticmethod
def fraction_divide(fra1, fra2):
molecular = fra1.molecular * fra2.denominator
denominator = fra1.denominator * fra2.molecular
return Fraction(molecular, denominator)
# 基本运算选择器
def operate(self, num1, num2, operater):
if not isinstance(num1, Fraction):
num1 = Fraction(num1)
if not isinstance(num2, Fraction):
num2 = Fraction(num2)
# 计算结果
if operater == '+':
return self.fraction_add(num1, num2)
if operater == '-':
return self.fraction_minus(num1, num2)
if operater == '×':
return self.fraction_multiply(num1, num2)
if operater == '÷':
return self.fraction_divide(num1, num2)
# 转成逆波兰
def generate_postfix_expression(self):
# 运算符栈
operator_stack = []
# 后缀栈
postfix_stack = []
for element in self.expression:
# 如果是操作数则添加
if element not in operators:
postfix_stack.append(element)
# 如果是运算符则按优先级
elif element in operator.values():
# 运算符栈为空,或者栈顶为(,则压栈
if not operator_stack or operator_stack[-1] == '(':
operator_stack.append(element)
# 若当前运算符优先级大于运算符栈顶,则压栈
elif priority[element] >= priority[operator_stack[-1]]:
operator_stack.append(element)
# 否则弹栈并压入后缀队列直到优先级大于栈顶或空栈
else:
while operator_stack and priority[element] < priority[operator_stack[-1]]:
postfix_stack.append(operator_stack.pop())
operator_stack.append(element)
# 如果遇到括号
else:
# 若为左括号直接压入运算符栈
if element == '(':
operator_stack.append(element)
# 否则弹栈并压入后缀队列直到遇到左括号
else:
while operator_stack[-1] != '(':
postfix_stack.append(operator_stack.pop())
operator_stack.pop()
while operator_stack:
postfix_stack.append(operator_stack.pop())
return postfix_stack
# 计算表达式(运算过程出现负数,或者除数为0,返回False,否则返回Fraction类)
def cal_expression(self):
# 生成后缀表达式
expressions_result = self.generate_postfix_expression()
# 存储阶段性结果
stage_results = []
# 使用list作为栈来计算
calculate_stack = []
# 后缀遍历
for element in expressions_result:
# 若是数字则入栈, 操作符则将栈顶两个元素出栈
if element not in operators:
calculate_stack.append(element)
else:
# 操作数
num1 = calculate_stack.pop()
# 操作数
num2 = calculate_stack.pop()
# 除数不能为0
if num1 == "0" and element == '÷':
return [False, []]
# 结果
result = self.operate(num2, num1, element)
if result.denominator == 0 or '-' in result.to_string():
return [False, []]
stage_results.append(result.to_string())
# 结果入栈
calculate_stack.append(result)
# 返回结果
return [calculate_stack[0], stage_results]
判断重复思路
1.由于考虑到题目说1+2+3,2+1+3相等,1+2+3和3+2+1是不相等的,一开始是从字符串的处理考虑,但是复杂度有点高。
2.所以换了一个角度考虑,从运算顺序入手,就想到用后缀表达式进行去重,并且这样也不用考虑括号,符合题目所说的(1+2)+3和1+2+3相等
3.具体就是存储每一次运算出来的结果,然后进行一一比较
例如(这里举的是比较简单的例子): 1+2+3,压入的数字:[3, 6]; 3+2+1,压入的数字:[5,6],所有两个判断为不相等
4.但是这样会出现1+3和2+2判断为重复的情况,所以添加两个数组——[操作数],[运算符],作为比较的依据
5.再来考虑效率,用字典的数据结构,以答案为键,其他三个比较标志作为值,只在答案相等的情况下判重
附:最终选定了添加后缀计算的去重模式,就是为了避免 (1÷1)+3 和 1+(3÷1) 这种不为重复表达式的情况,但是效率确实比只判断(操作数、运算符)的模式低了
代码实现
# 用答案作为索引构建的字典,
{
"1'2/2": [
[[压入的数字], [操作数], [运算符]],
[[压入的数字], [操作数], [运算符]],
...
]
}
# 通过比较上述字典, 确认新表达式是否已经在上述字典中
def judge_repeat(self, answer, test_sign):
for expression_sign in self.no_repeat_dict[answer]:
# 记录相同的个数
same_num = 0
for i in range(3):
if collections.Counter(expression_sign[i]) == collections.Counter(test_sign[i]):
same_num += 1
# 如果中间结果、操作数、运算符均相等,则为重复
if same_num == 3:
return False
return True
实际测试
通过命令行控制
python Myapp.py [args|args]
[args]
├─ -h --help # 输出帮助信息
├─ -n # 指定生成表达式数量,默认100
├─ -r # 指定生成表达式各个数字的取值范围,默认100
├─ -a # 需和 -e -f 参数共同使用进行批改,指定答案文件
├─ -e # 需和 -a -f 参数共同使用进行批改,指定练习文件
├─ -f # 需和 -e -a 参数共同使用进行批改,指定生成文件的份数
├─ -c # 后跟文件名,查看文件内容
└─ -g # 赋非零值开启GUI
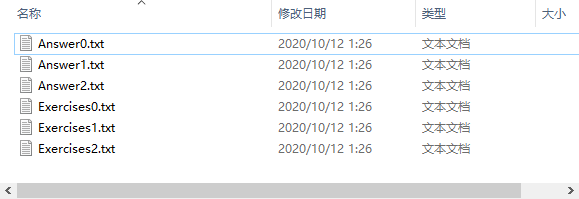
- 执行生成三份题目与答案文件代码
python Myapp.py -n 10 -r 10 -f 3
可以看到程序运行界面如下

可以看到docs文件夹中已经生成了三份题目文件与三份答案文件,如下图所示
- 执行批改代码
python Myapp.py -e <exercisefile>.txt -a <answerfile>.txt
- 以下面的命令为例
python Myapp.py -e Exercises0.txt -a Answer0.txt
程序运行界面如下

可以看到docs文件夹中已经生成了一份成绩文件,如下图所示

- 执行查看文件内容
python Myapp.py -c Grade0.txt
程序运行界面如下

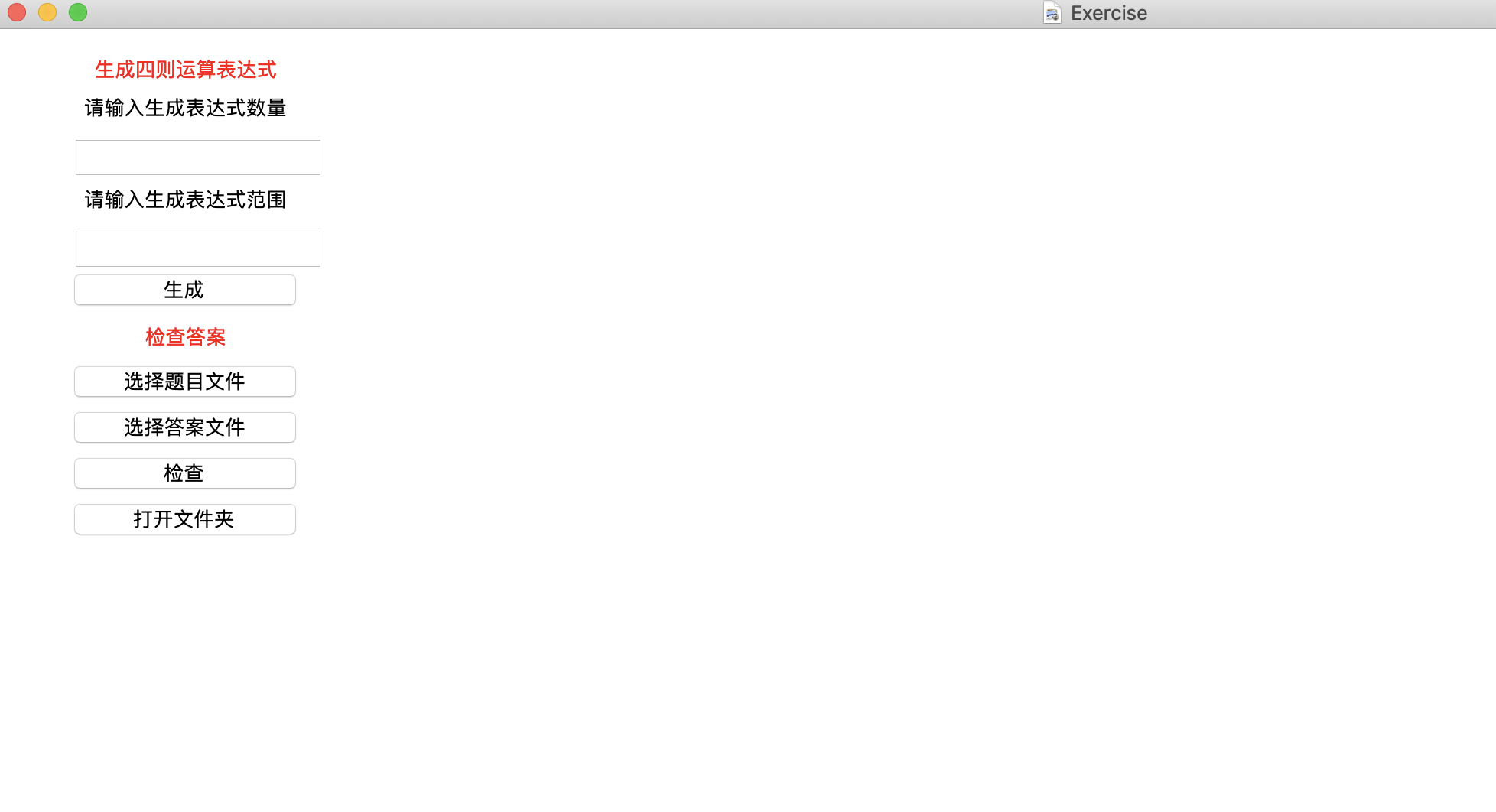
通过图形化界面控制
- 打开图形化界面代码
python Myapp.py -g 1
GUI界面如图所示
输入参数,系统自动生成题目文件与答案文件,如下图所示
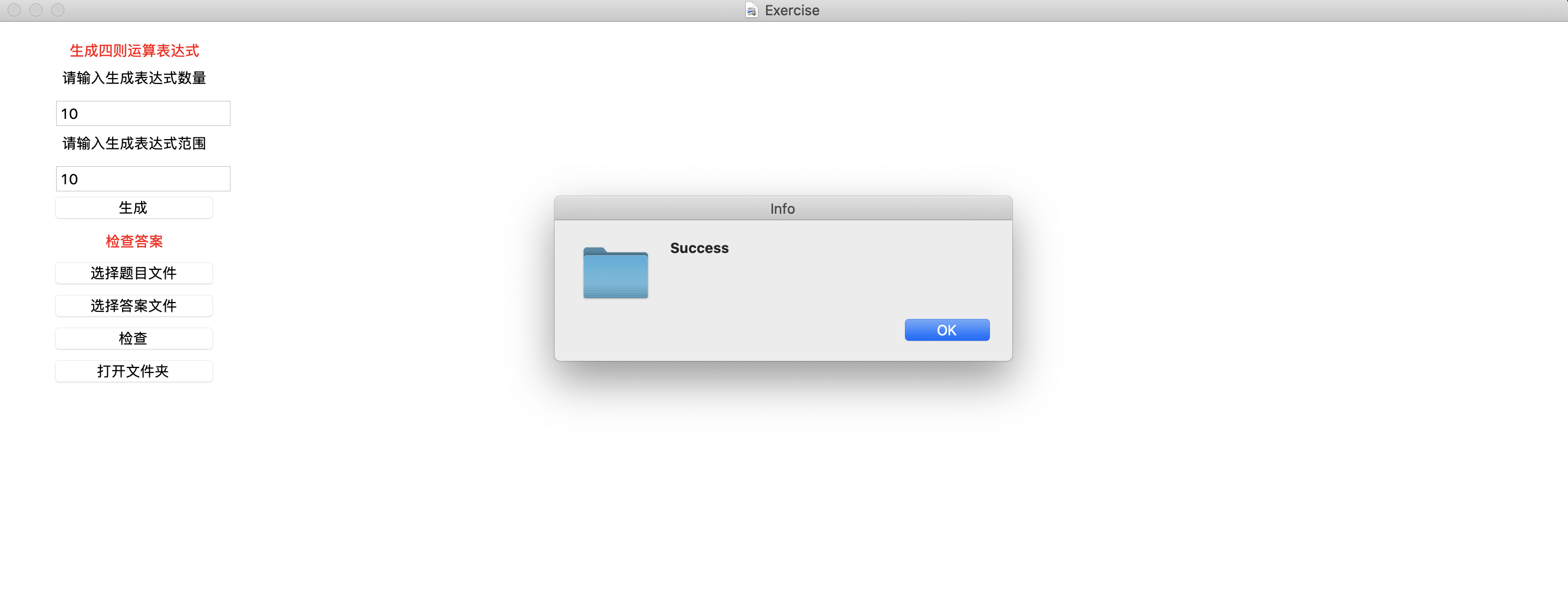
可以看到docs文件夹中再次生成了一份题目文件与一份答案文件,如下图所示
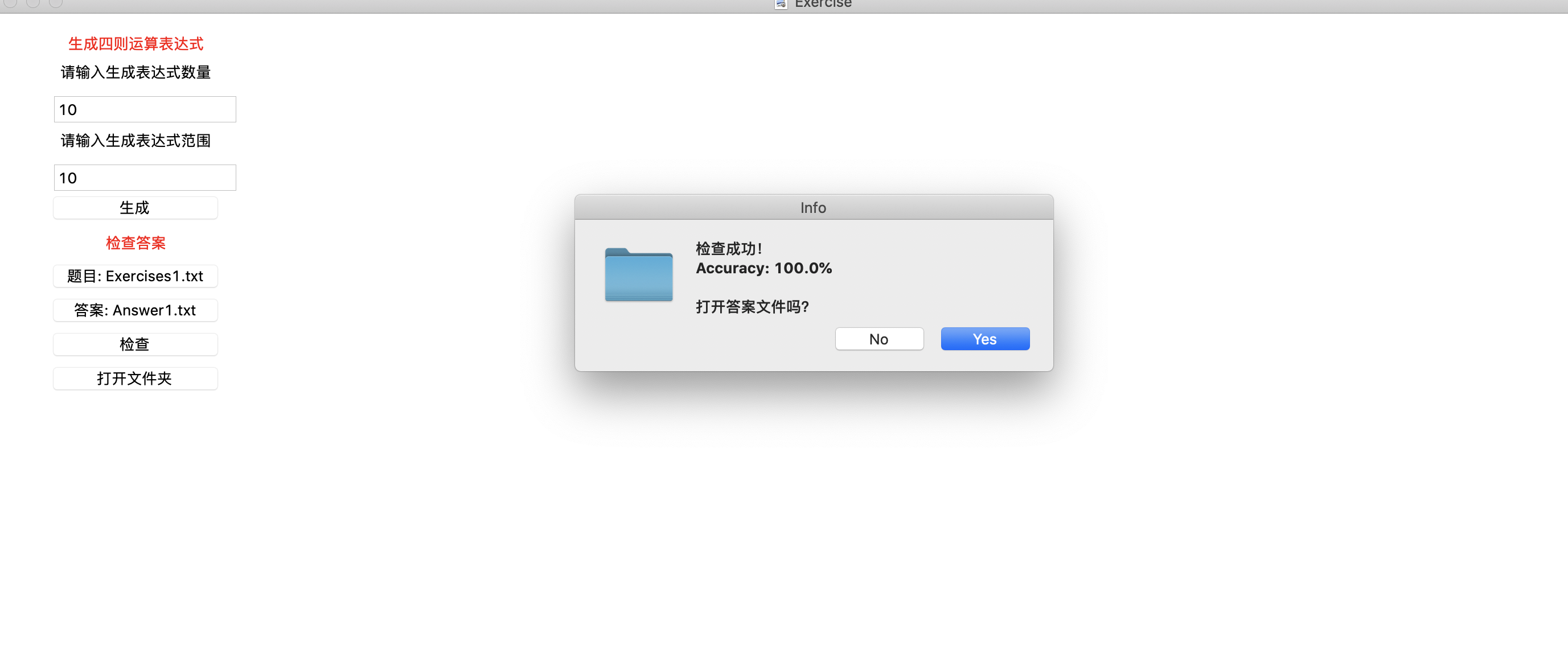
手动选择该题目文件与答案文件,通过GUI界面的检查功能对答案进行批改,如下图所示
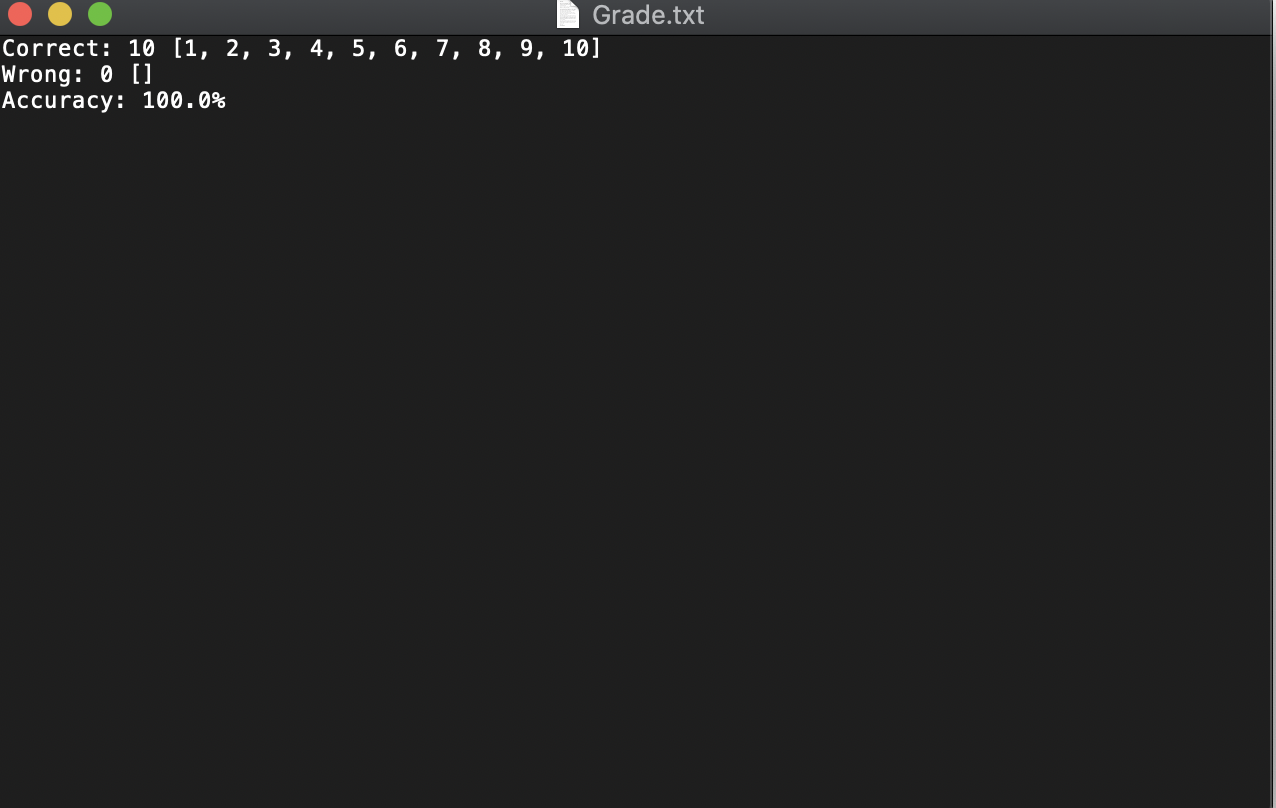
可以发现docs文件夹中生成了一份成绩文件,打开该文件后如下图所示
独到之处及异常处理
-
采用了多线程的界面,任何操作不会阻塞其他操作,例如:可以在生成答案的同时批改作业
-
得益于上面的设计,可以同时生成多个表达式文件,存储形式如下所示
![]()
-
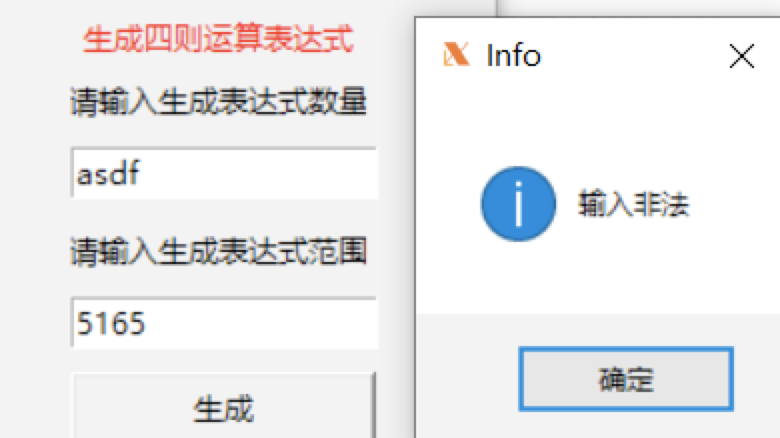
对于错误的输入,会有提示,如下所示
![]()
-
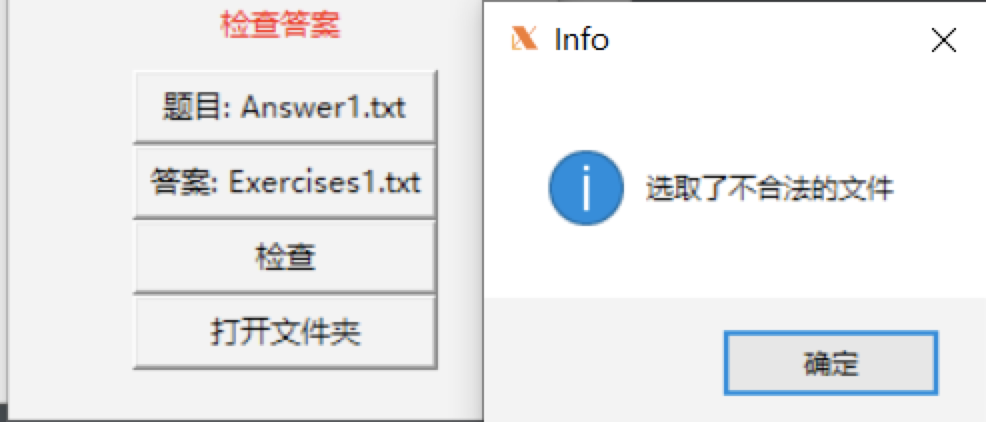
对于文件选择后,点击批改,对于文件的格式有错误检查
![]()
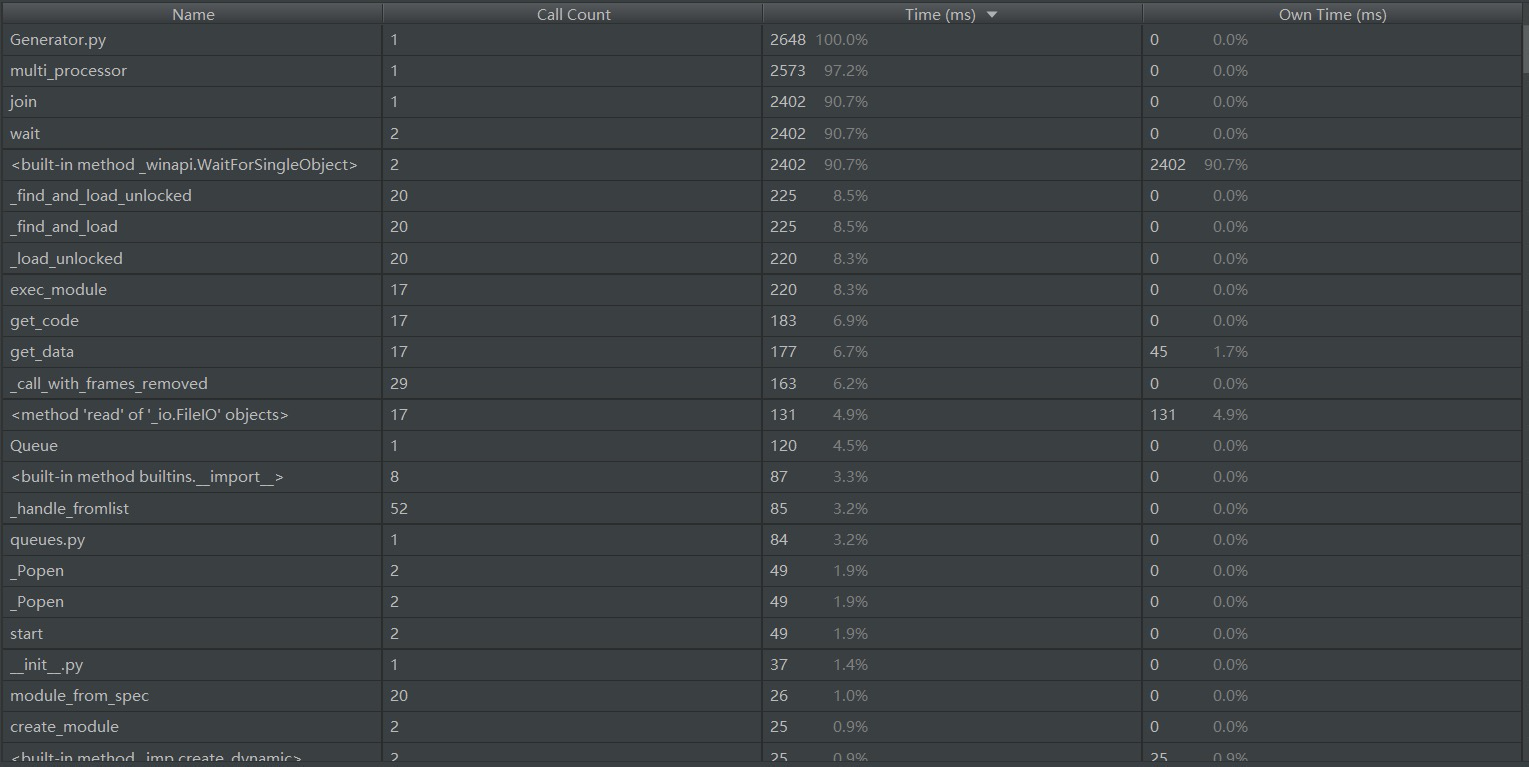
性能分析
通过Pycharm自带测试器测试结果如下
测试代码覆盖率结果如下

PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 37 |
| Estimate | 估计这个任务需要多少时间 | 30 | 23 |
| Development | 开发 | 500 | 600 |
| Analysis | 需求分析(包括学习新技术) | 60 | 80 |
| Design Spec | 生成设计文档 | 40 | 79 |
| Design Review | 设计复审 | 20 | 17 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | 40 |
| Design | 具体设计 | 30 | 45 |
| Coding | 具体编码 | 20 | 22 |
| Code Review | 代码复审 | 30 | 21 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 42 |
| Reporting | 报告 | 30 | 45 |
| Test Repor | 测试报告 | 30 | 40 |
| Size Measurement | 测试工作量 | 20 | 45 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 30 |
| Total | 合计 | 920 | 1166 |
总结
黄炜恒
- 这一次的项目要求与同伴一起合作完成,对我这样的基础薄弱的学生来说是一大挑战,好在我的结对伙伴小陈给了我许多的鼓励与支持,使我们得以完成了这次的结对作业。在完成项目的过程中,我体会到了合作的重要性,如果没有成员之间的意见交换与集思广益,完成这样一个项目将会十分困难,与此同时我也从这个项目中学习到了许多的编程技巧以及技术。总结这次结对项目,无论是从技术还是精神层面我都受益匪浅,再次感谢我的结对伙伴小陈,希望能在他的身上学习到更多。
陈伟升
- 这一次的项目,与前一次不同的是有了更多更细化的需求。在这样背景下的代码编写设计,就要对许多的细节和新添加的小功能进行调整。这也是我在这次编程中耗费最多时间和精力的地方。同时,做到与小组成员的交流和沟通也是提高效率的基本前提,通过线下和线上逐步地对应每条需求分析、交流和提出相应的解决方案。对于完成项目过程中遇到的困难,我得到了结对伙伴小黄的帮助和鼓励。彼此之间良好的交流和合理的分工都是促进项目进展的因素。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号