
第一次个人编程作业
作业要求
| 项目 | 内容 |
|---|---|
| 这个作业属于哪个课程 | 软件工程 |
| 这个作业要求在哪里 | 作业要求 |
| 这个作业的目标 | 论文查重个人项目+PSP表格+性能测试+单元测试+Git管理 |
作业所在Github地址
开发前预估PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | |
| Estimate | 估计这个任务需要多少时间 | 30 | |
| Development | 开发 | 120 | |
| Analysis | 需求分析(包括学习新技术) | 20 | |
| Design Spec | 生成设计文档 | 20 | |
| Design Review | 设计复审 | 20 | |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | |
| Design | 具体设计 | 30 | |
| Coding | 具体编码 | 20 | |
| Code Review | 代码复审 | 30 | |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | |
| Reporting | 报告 | 30 | |
| Test Repor | 测试报告 | 30 | |
| Size Measurement | 测试工作量 | 20 | |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | |
| Total | 合计 | 480 |
模块接口的设计与实现过程
代码组织
代码所用函数关系图如下
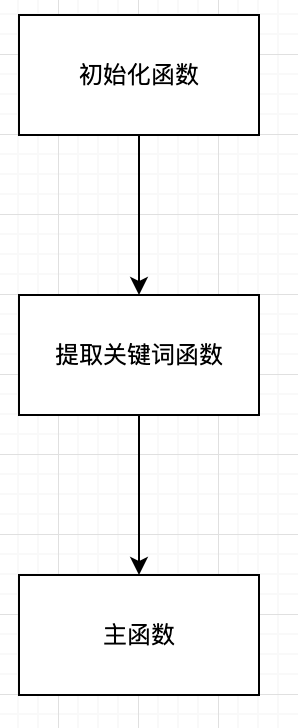
由于python中有关于MinHash算法的库存在,因此代码实现起来较为简单(关于MinHash算法请查阅我的GitHub中对MinHash算法的原理介绍)。只需要设置一个类,在这个类中再分别定义初始化函数,用于提取关键词的函数以及主函数即可。它们的关系就是先调用提取关键词的函数对文档进行关键词提取,再将经过关键词提取处理后的文档交给主函数,让主函数调用MinHash函数进行计算,得出文档之间的相似度
关键函数说明
def main(self):
# 去除停用词
# jieba.analyse.set_stop_words('./files/stopwords.txt')
# MinHash计算
m1, m2 = MinHash(), MinHash()
# 提取关键词
s1 = self.extract_keyword(self.s1)
s2 = self.extract_keyword(self.s2)
for data in s1:
m1.update(data.encode('utf8'))
for data in s2:
m2.update(data.encode('utf8'))
return m1.jaccard(m2)
主函数调用了MinHash()函数,分别计算出两篇文章的具有MinHash签名的完整向量。最后通过比较两个向量中具有相同MinHash签名的数量来得出两篇文章的相似度
独到之处
def extract_keyword(content): # 提取关键词
# 正则过滤 html 标签
re_exp = re.compile(r'(<style>.*?</style>)|(<[^>]+>)', re.S)
content = re_exp.sub(' ', content)
# html 转义符实体化
content = html.unescape(content)
# 切割
seg = [i for i in jieba.cut(content, cut_all=True) if i != '']
# 提取关键词
keywords = jieba.analyse.extract_tags("|".join(seg), topK=200, withWeight=False)
return keywords
对于用于查重的这几篇文章,有几篇是单纯的文本文档,而剩余的文章都为带有html标签的文档,为了使查重时减少html因素的影响。在提取关键词函数中加入了对html标签的过滤。并且将html转义符实体化,这样就可以减少html标签与转义符对查重结果的影响,使结果更准确
程序运行截图
程序运行截图如下,在命令行中输入文章地址参数


模块接口部分的性能改进
改进性能所花费的时间
约100分钟
改进思路
由于项目要求在运行main.py时则要从命令行中输入命令地址参数,因此在第二版代码中采用了getopt模块来实现这个功能,但随后在性能测试中发现在传参这个模块中耗时较长,随后查阅资料后采用了sys库来实现这个功能,性能大为改进
Pycharm cProfiler 性能分析
性能分析图如下
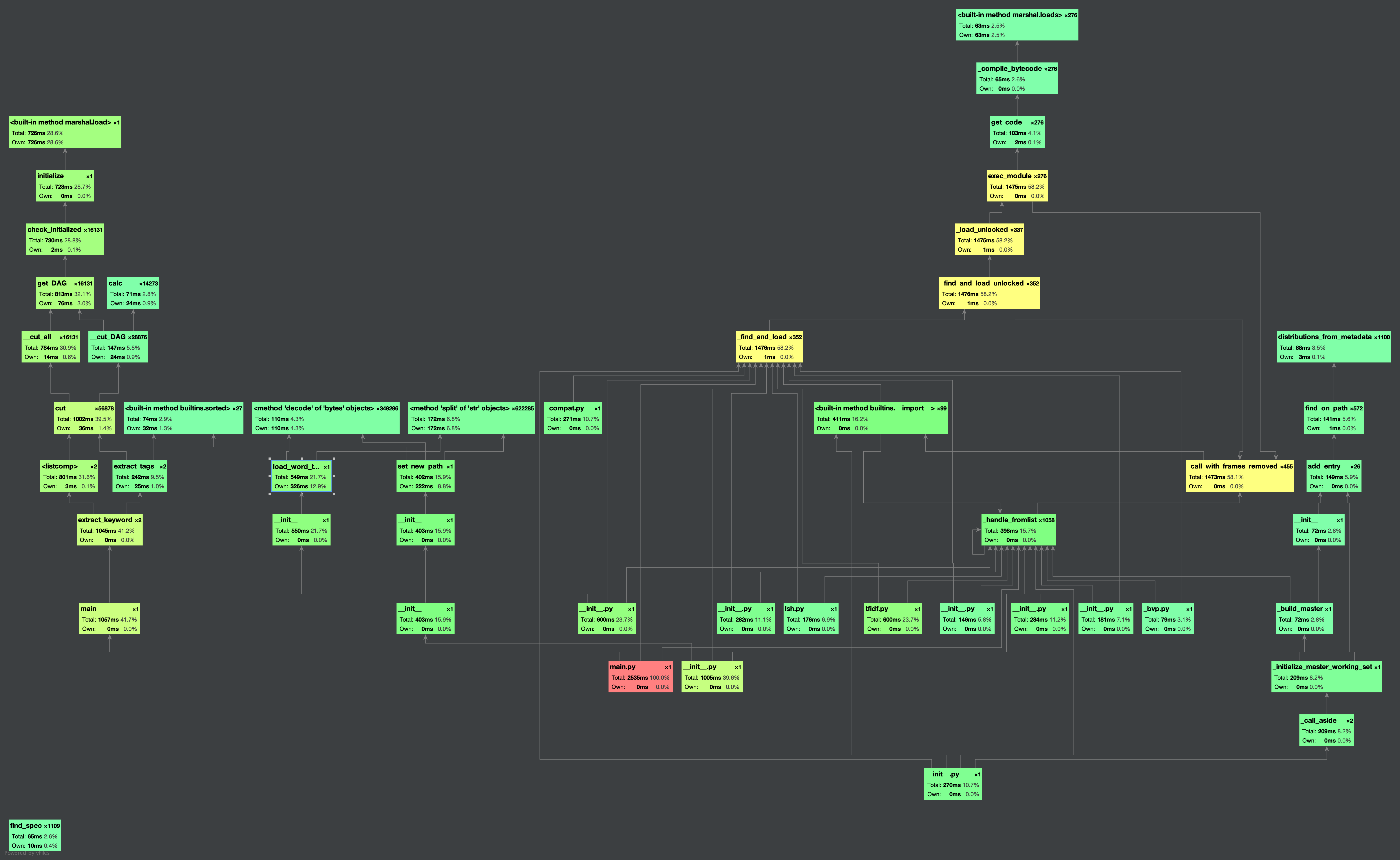
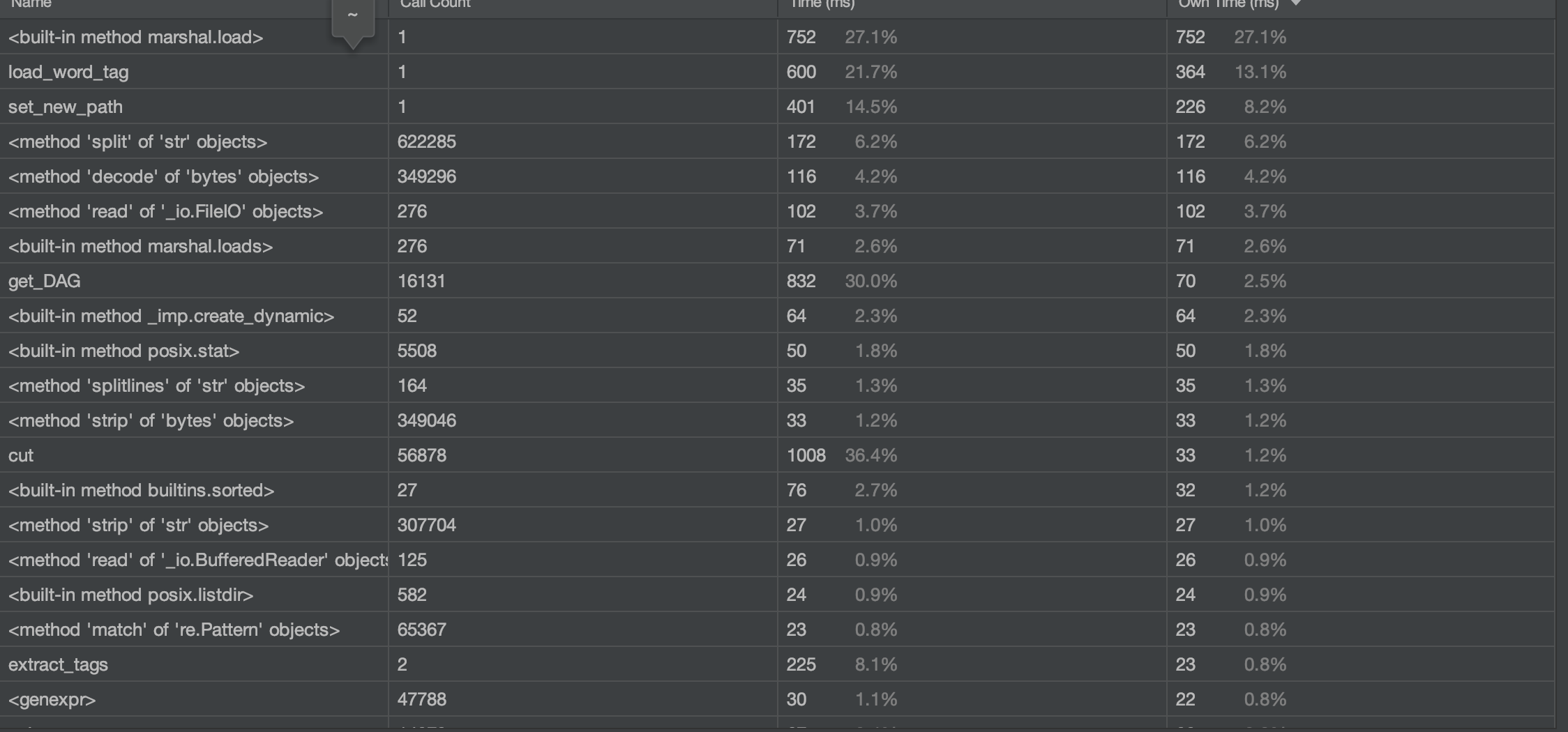
程序中消耗比较大的函数如下
单元测试
采用python自带单元测试工具unittest进行单元测试
1.对提取关键词函数进行单元测试,尝试输出提取出来的关键词,程序如下
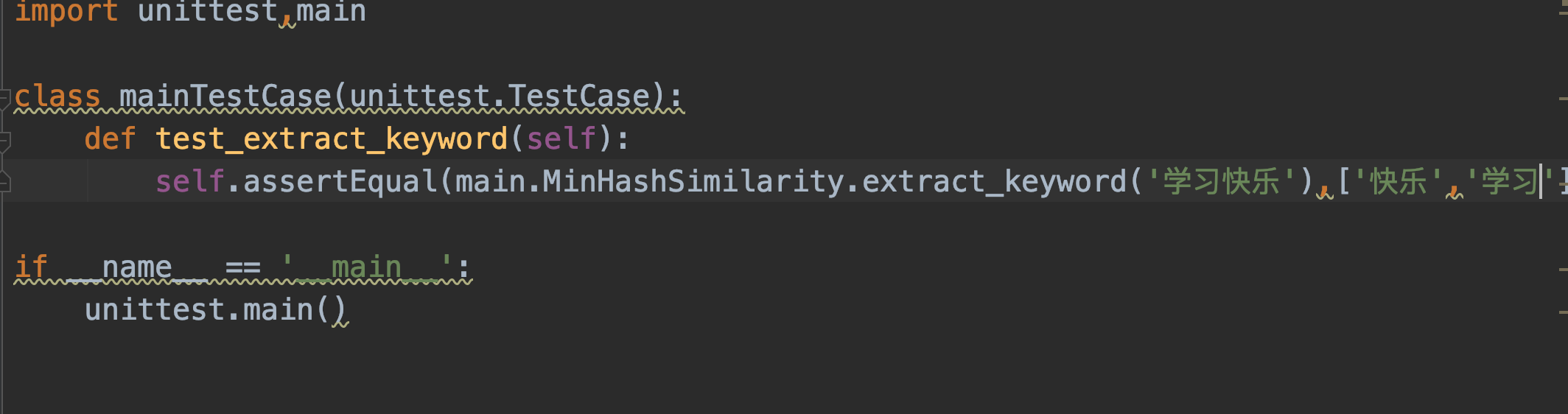
输出结果如下,成功通过测试
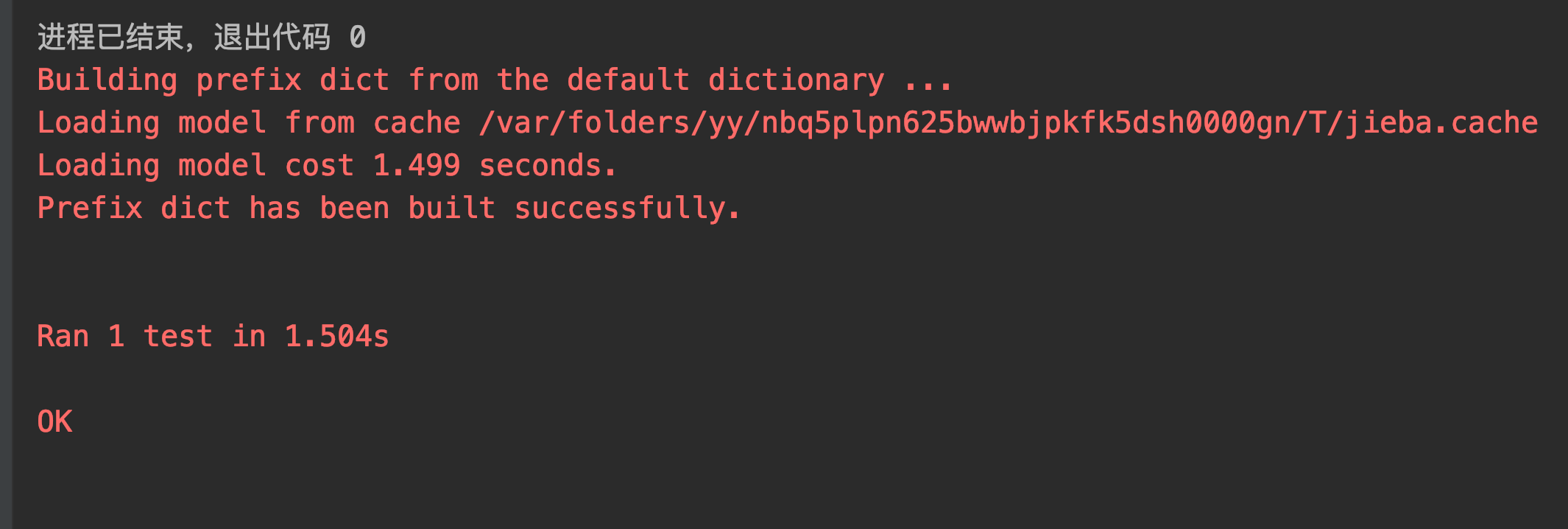
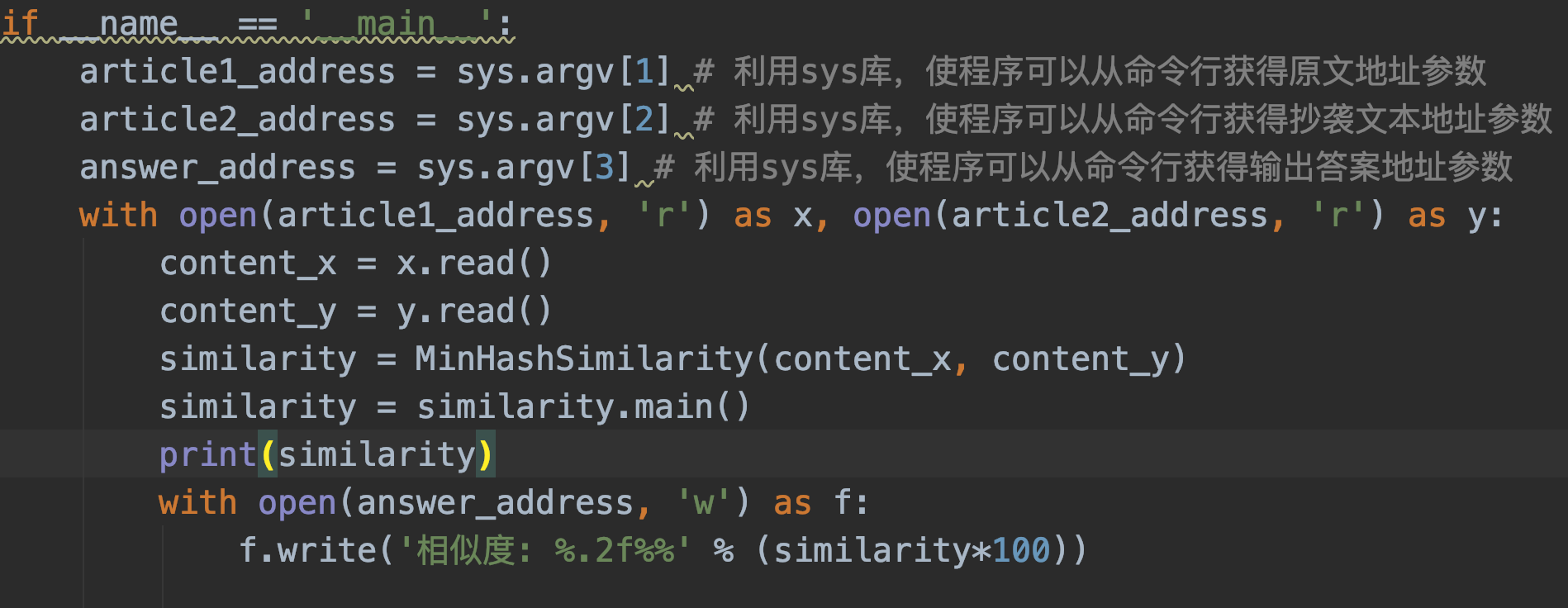
2.对主函数进行单元测试,测试通过jaccard()函数计算出的文本相似度是否正确,程序如下
输出结果如下,成功通过测试

异常处理
1.当运行程序时没有在命令行中输入文章地址时报错,截图如下

2.若不对文章的html标签进行过滤,则结果将大大降低,程序截图如下

输出结果如下

开发后统计PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 30 | 25 |
| Estimate | 估计这个任务需要多少时间 | 30 | 20 |
| Development | 开发 | 120 | 105 |
| Analysis | 需求分析(包括学习新技术) | 20 | 17 |
| Design Spec | 生成设计文档 | 20 | 15 |
| Design Review | 设计复审 | 20 | 17 |
| Coding Standard | 代码规范(为目前的开发制定合适的规范) | 30 | 22 |
| Design | 具体设计 | 30 | 40 |
| Coding | 具体编码 | 20 | 22 |
| Code Review | 代码复审 | 30 | 21 |
| Test | 测试(自我测试,修改代码,提交修改) | 30 | 42 |
| Reporting | 报告 | 30 | 32 |
| Test Repor | 测试报告 | 30 | 22 |
| Size Measurement | 测试工作量 | 20 | 13 |
| Postmortem & Process Improvement Plan | 事后总结,并提出过程改进计划 | 20 | 24 |
| Total | 合计 | 480 | 437 |

 浙公网安备 33010602011771号
浙公网安备 33010602011771号