快速排序时一种简单且实际上也非常有效地的排序算法,输入是n个数的的序列。最坏的运行时间为Θ,平均性能最好的期望运行时间Θ,。
首先描述快速排序算法。假定各个数都互不相同。
输入:n个不同的元素序列。
输出:排序后的序列的元素集合
最坏的情况下,快速排序要进行Ω次比较运算,及选择x的不同导致此情况。如1~n个数,我们选择n作为基准x。最快速排序要进行n-1此比较,产生一个大小为0的空列表以及一个大小为n的列表。依次选择n-1,n-2, ... ,2,1作为基准。则快速排序需要进行:
次比较。
一般的,我们在使用快速排序算法时,总是希望能够尽可能的均分列表,使得我们的运行性能最好(比较的次数最少)。即n个元素的类别我们希望每一个子列表大小至多为。则比较多的次数有如下关系
。
其解为,这个是排序最好的结果。
即可以说,把输入序列分成两个大小至少为的字表的任意基准元素序列都需要运行次。
如何保证算法总能选择有效地基准元素?
显然,如果使用随机化过程选取基准值,不大可能总是选择到不是很好的值。而随机化的过程的比较次数为,这个结果比使用比较排序的界要好。
Ps
简单证明:
一个随机变量。不妨设如果比较,并交换了,则为1,否则为0。
则其线性期望
因为从每一个子序列中独立选且均匀的随机选取,即取1的概率是。利用,
又有满足,故
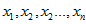 的序列。最坏的运行时间为Θ
的序列。最坏的运行时间为Θ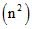 ,平均性能最好的期望运行时间Θ
,平均性能最好的期望运行时间Θ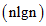 ,
, 。
。
 的序列。最坏的运行时间为Θ,平均性能最好的期望运行时间Θ,。
的序列。最坏的运行时间为Θ,平均性能最好的期望运行时间Θ,。

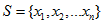 。
。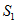
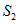
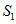 和
和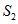 进行快速排序;
进行快速排序;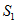
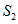
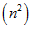
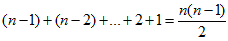
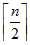 。则比较多的次数
。则比较多的次数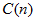 有如下关系
有如下关系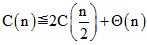
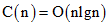 ,这个是排序最好的结果。
,这个是排序最好的结果。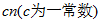 的字表的任意基准元素序列都需要运行
的字表的任意基准元素序列都需要运行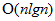 次。
次。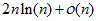 ,这个结果比使用比较排序的界
,这个结果比使用比较排序的界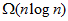 要好。
要好。
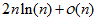 :
:
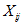 。不妨设如果
。不妨设如果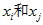 比较,并交换了,则
比较,并交换了,则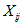 为1,否则为0。
为1,否则为0。
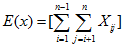
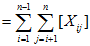
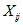 取1的概率是
取1的概率是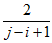 。利用
。利用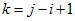 ,
,
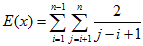
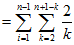
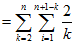
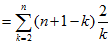
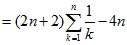
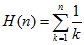 满足
满足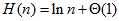 ,故
,故
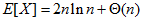 。
。
 浙公网安备 33010602011771号
浙公网安备 33010602011771号