Rotate to Attend: Convolutional Triplet Attention Module && GINet: Graph Interaction Network for Scene Parsing 论文阅读笔记
Rotate to Attend: Convolutional Triplet Attention Module
论文和代码开源地址: https://arxiv.org/abs/2010.03045
https://github.com/LandskapeAI/triplet-attention
本文研究了轻量但有效的注意力机制,并提出了triplet attention,这是一种通过使用三分支结构捕获跨维度交互来计算注意力权重的方法。对于输入张量,triplet attention通过旋转操作和随后的残差变换来建立维度间相关性,并且以可以忽略的计算开销对通道间和空间信息进行编码。
Cross-Dimension Interaction(跨纬度交互)
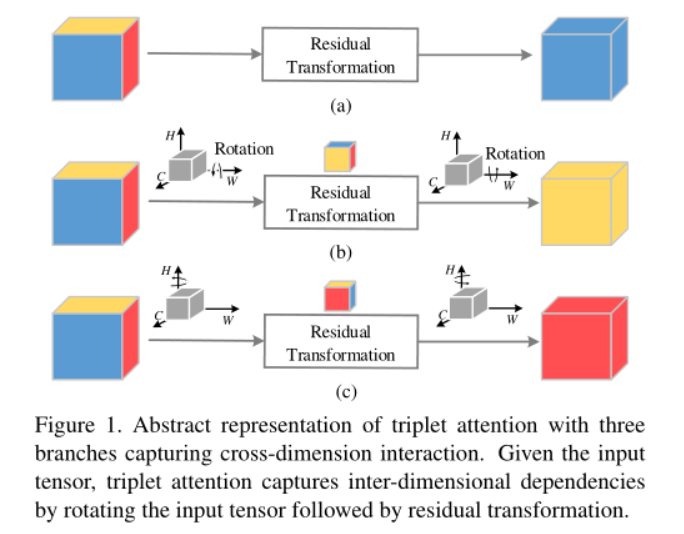
本文提出的triplet attention,有效地解释了跨维交互作用。triplet attention由三个分支组成,每个分支负责捕获输入的空间维度和通道维度之间的交叉维度。给定一个形状为(C×H×W)的输入张量,每个分支负责聚合空间维度H或W与信道维度C之间的跨维交互特征。我们通过简单地排列每个分支中的输入张量,然后通过Z池传递张量,然后传递核大小为k×k的卷积层,然后由S型激活层生成关注权重,然后对置换后的输入张量施加关注权重,然后将其置换回原始输入形状。
Triplet Attention
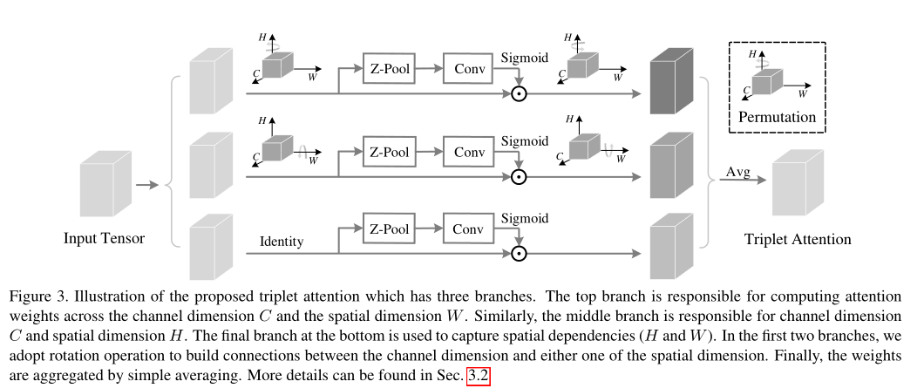
Triplet Attention由3个分支组成,其中两个分支负责捕获通道C和空间H或W之间的跨维交互。最后一个Branch类似于CBAM,用于构建Spatial Attention。最终3个Branch的输出使用简单的平均进行聚合
相较于以往的注意力方法,主要有两个优点:
- 可以忽略的计算开销
- 强调了多维交互而不降低维度的重要性,从而消除了通道和权重之间的间接对应。
网络结构
-
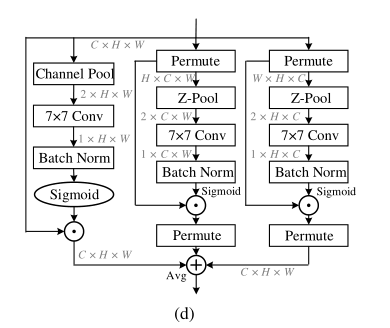
第一个分支:通道注意力计算分支,输入特征经过Z-Pool,再接着7 x 7卷积,最后Sigmoid激活函数生成通道注意力权重
-
第二个分支:通道C和空间W维度交互捕获分支,输入特征先经过permute,变为H X C X W维度特征,接着在H维度上进行Z-Pool,后面操作类似。最后需要经过permuter变为C X H X W维度特征,方便进行element-wise相加
-
第三个分支:通道C和空间H维度交互捕获分支,输入特征先经过permute,变为W X H X C维度特征,接着在W维度上进行Z-Pool,后面操作类似。最后需要经过permuter变为C X H X W维度特征,方便进行element-wise相加
最后对3个分支输出特征进行相加求Avg
Z-pool:这里的Z-POOL层负责通过连接跨该维度的平均池化和最大池化,层负责将C维度的Tensor缩减到2维,将该维上的平均汇集特征和最大汇集特征连接起来。这使得该层能够保留实际张量的丰富表示,同时缩小其深度以使进一步的计算量更轻。可以用下式表示:

Complexity Analysis:

与其他标准注意机制相比,验证了Triplet Attention的参数效率。C表示层的输入信道数,r表示计算信道关注度时的最大似然比,用于二维卷积的核大小由k;k<<<C。与此方法方法相比,不同关注层带来的参数开销要高得多。
Experiments:
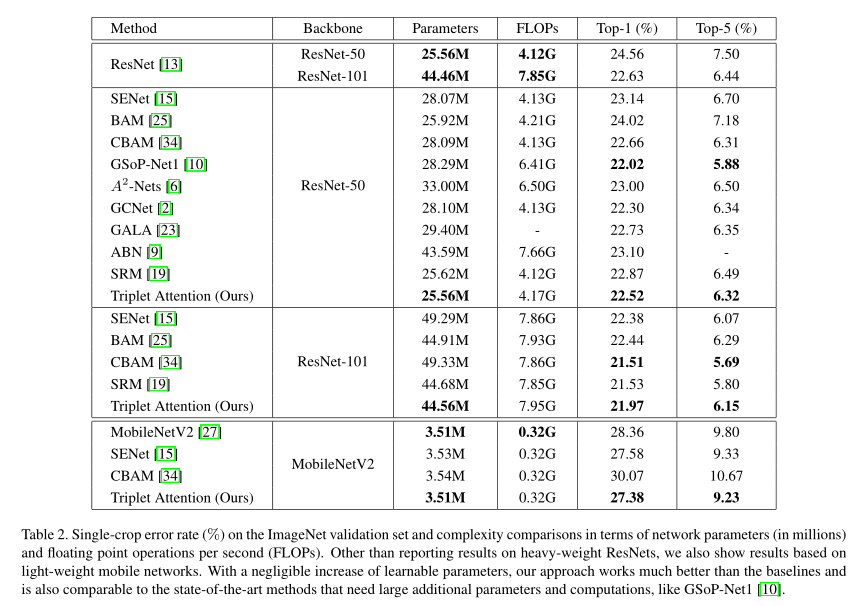
ImageNet:
Object Detection:


Ablation Study on Branches:
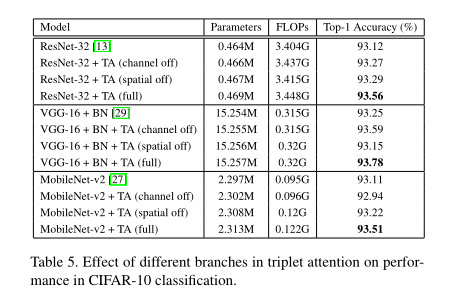
conclusion
实验表明, Triplet Attention 提高了ResNet和MobileNet等标准神经网络结构在ImageNet上的图像分类和MS Coco上的目标检测等任务上的基线性能,而只引入了最小的计算开销。
部分参考:https://mp.weixin.qq.com/s/zwIcFTmNEvdZAC4YAkrt5w (侵删)
GINet: Graph Interaction Network for Scene Parsing
论文:https://arxiv.org/pdf/2009.06160.pdf
Abstract:
近年来,利用局部卷积以外的图像区域进行上下文推理在场景解析方面显示出了巨大的潜力。这篇论文通过提出一个图交互单元(GI单元)和一个语义上下文损失(SC-Loss)来探索如何利用语言知识来促进基于图像区域上的上下文推理。GI单元能够在高级语义上增强卷积网络的特征表示,并根据每个样本自适应地学习语义一致性。
具体地说,首先将基于数据集的语言知识结合到GI单元中,以促进视觉图形上的上下文推理,然后将视觉图形的进化表示映射到每个局部表示,以增强场景解析的区分能力。通过SC-Loss对GI单元进行进一步改进,增强了基于样例的语义图的语义表示。我们进行全面的消融研究,以证明在我们的方法中每个组件的有效性。特别的,本文提出的图交互网络Ginet在包括Pascal-Context和COCO-Stuff数据集在内的流行基准测试中表现优于最先进的方法。
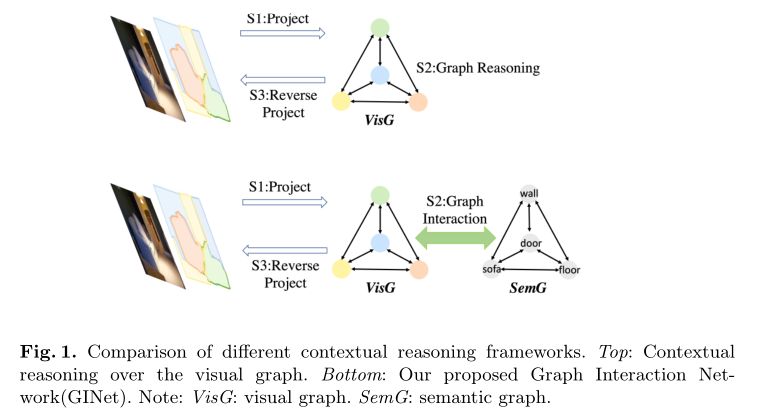
不同语境推理框架的比较
-
图一顶部:仅对2D输入图像或视觉特征的视觉图形表示执行上下文推理
-
图一底部:提出了一个图形交互单元(GI Unit),它首先将基于数据集的语言知识合并到视觉图形上的特征表示中,然后将视觉图形的进化表示重新投影到每个位置表示中,以增强区分能力
图交互网络框架(Ginet)
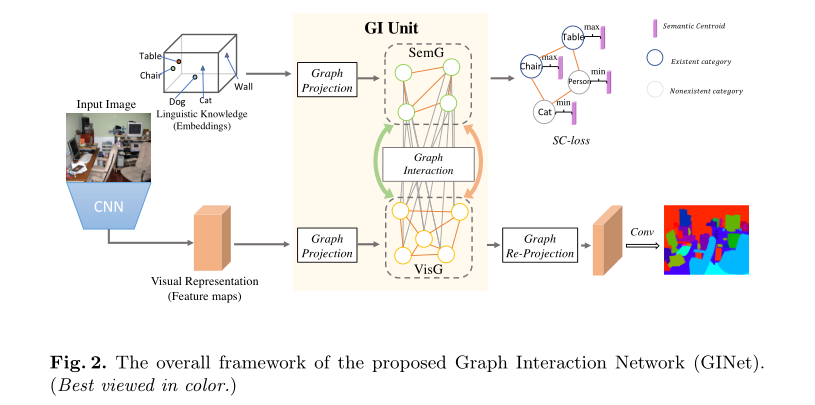
- 首先,采用预先训练好的ResNet作为骨干网络,在这里可以根据输入的2D图像提取视觉特征。同时,可以以范畴实体(类)的形式提取基于数据集的语言知识,并将其馈送到词嵌入以实现语义表示。
- 其次,通过GI单元中的图形投影操作传递视觉特征和语义嵌入表示,分别构造两个图形。因此,将编码可视区域之间的依赖性的一个图构建在可视特征之上,其中节点指示可视区域,而边表示这些区域之间的相似性或关系。另一个图建立在依赖于数据集的类别(由词嵌入表示)上,对语言相关性和标签相关性进行编码。
- 接下来,在GI单元中进行图形交互操作,其中使用语义图来促进视觉图形上的上下文推理,并指导从视觉图形中提取的基于样本的语义图的生成。然后,对GI单元生成的进化视觉图进行Graph重投影操作,以增强对每个局部视觉表示的区分能力,同时在训练阶段通过语义上下文丢失对语义图进行更新和约束。
- 最后,采用1×1卷积和简单的双线性上采样来获得解析结果。
Experiments
通过一系列实验来评估本文提出的图交互单元和SC-Lost的有效性。 对本文提出的方法在 Pascal-Context、CoCo Stuff和ADE20K这些数据集上进行了广泛的评估和消融研究。

-
从表一可以看到在+VisG之后添加GINet模块,把语义信息加进来之后可以提高0.8个点,进一步用SC-loss来约束又可以提高0.7个点。在ResNet50和ResNet101上都获得类似的性能。
-
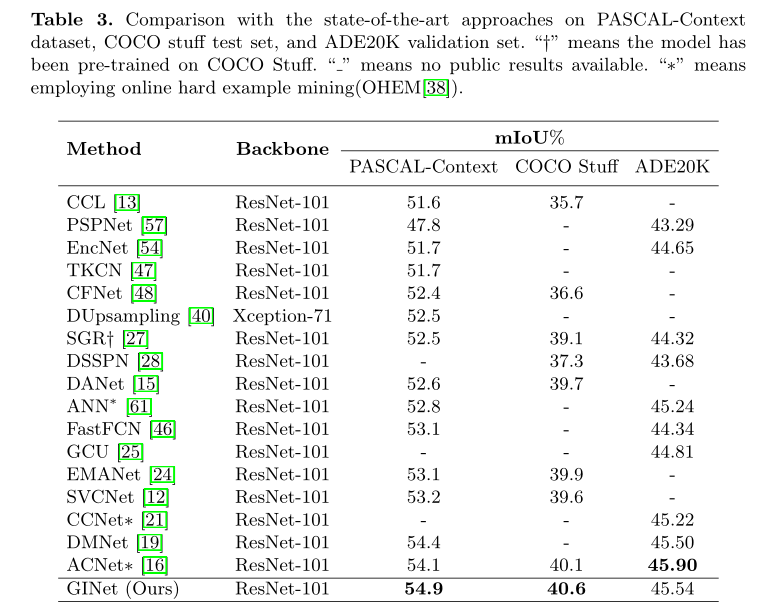
表二是和一些常见方法的比较,从表中看出GInet获得了较高的性能和速度。
-
和其他方法的SOTA比较,在PASCAL-Context和COCO Stuff上获得了比较高的性能,在ADE20K也达到了不错的性能
场景解析结果和投影矩阵的可视化
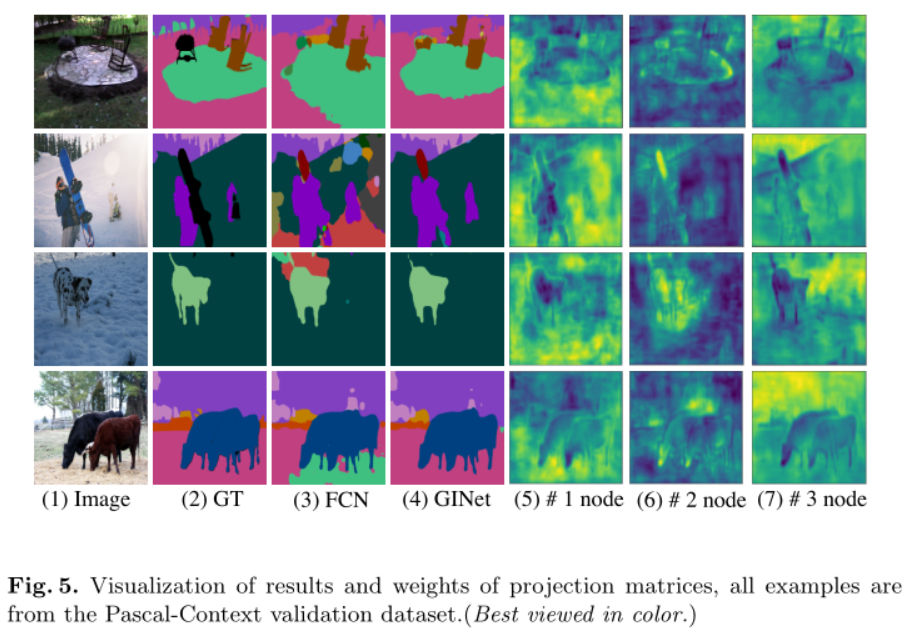
第一列和第二列分别列出了RGB输入图像和地面真实场景解析图像。
- 从第2行和第3行可以看出,与FCN相比GINet方法有较大改进
- 由于第二和第四示例中的照明变化,雪景在纹理和颜色上发生了显著变化。通过引入语义图来促进可视化图上的推理,本文提出的方法成功地获得了更准确的句法分析结果
- 在第四行中,仅通过空间上下文较难区分图像中的绿草和黄草,本文的方法仍然通过结合语义信息来正确识别目标,其中颜色的变化误导了FCN方法。
conclusion:
本文基于提出的图交互单元和语义上下文丢失,提出了一种称为图交互网络(Ginet)的新框架。基于新框架提出的方法在PASCAL-CONTEXT和COCO STUSET两个具有挑战性的场景分析基准上的性能明显优于现有方法,在ADE20K数据集上获得了与之相当的性能。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号