
字符编码知多少(二)
BOM头
BOM头全程Byte Order Mark (字节顺序标记), 是Unicode编码标准中,最早是用于UTF32/16中标识字节顺序的特殊字符,后来随着UTF-8的出现,为了兼容,又有了标识文本编码格式的作用。
最初主要是为了解决UTF32/16编码方案中大小端的问题,(大端BE:高字节在前,小端LE:低字节在前)。所以需要在字符串前增加一个特殊标记,以方便识别解析。
随着UTF-8的出现,不再需要BOM头。但微软为了方便自家软件能快速区分UTF-8与ANSI编码,而额外引入了非标准拓展。因此有了独特的UTF-8 BOM 编码方式
不同Unicode编码中的BOM头表现
| 编码格式 | BOM头字节序列 | 长度 | 说明 |
|---|---|---|---|
| UTF-8 BOM (微软特色) | EF BB BF | 3字节 | 仅作编码标识,无字节顺序问题 |
| UTF-8 | - | - | - |
| UTF-16 BE(大端) | FE FF | 2字节 | 表示高位字节在前 |
| UTF-16 LE(小端) | FF FE | 2字节 | 表示低位字节在前 |
| UTF-32 BE | 00 00 FE FF | 4字节 | 表示高位字节在前 |
| UTF-32 LE | FF FE 00 00 | 4字节 | 表示低位字节在前 |
眼见为实
使用文本编辑器,选择另存为,保存为不同的编码方案
public static void Run()
{
var utf8_path = @"C:\Users\liu\Documents\utf-8.txt";
var utf8_bom_path = @"C:\Users\liu\Documents\utf-8 bom.txt";
var utf16_le_path = @"C:\Users\liu\Documents\utf-16 be.txt";
var utf16_be_path = @"C:\Users\liu\Documents\utf-16 le.txt";
var utf8= BitConverter.ToString(File.ReadAllBytes(utf8_path));
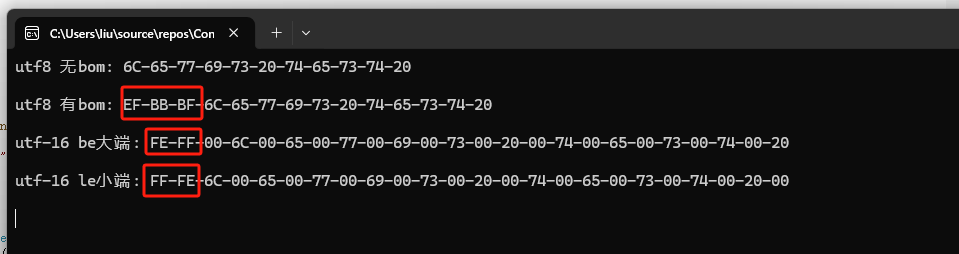
Console.WriteLine("utf8 无bom: "+utf8 +"\n");
var utf8_bom= BitConverter.ToString(File.ReadAllBytes(utf8_bom_path));
Console.WriteLine("utf8 有bom: "+utf8_bom + "\n");
var utf16_le= BitConverter.ToString(File.ReadAllBytes(utf16_le_path));
Console.WriteLine("utf-16 be大端: "+utf16_le + "\n");
var utf16_be = BitConverter.ToString(File.ReadAllBytes(utf16_be_path));
Console.WriteLine("utf-16 le小端: "+utf16_be + "\n");
}
为什么UTF-8不需要BOM
BOM的本质是为了解决UTF-16/32大小端歧义的问题,而UTF8的编码特性从根本上解决了BOM要处理问题,所以BOM对UTF-8而言既无必要,而且还属于"额外附加"的内容。
UTF-16/32为什么需要
假如我要传输一个字符串“中“,Unicode编码:U+4E2D,在我传输给你的过程中,它可以是FE-FF-4E-2D(大端),也可以是FF-FE-2D-4E(小端),如果我没有标识字节顺序,你如何解析?
UTF-8 核心编码规则
要想知道为什么UTF-8不需要BOM,先从它的原理开始说起。
- 可变长编码
用1-4个字节表示一个Unicode字符,码点越小,占用的字节数越小。 - 标准的字节格式
每个字符的起始字节,会有一个特殊标识来表示该字符占用的总字节数,后续的字节用固定格式来表示,相当于有一个标准模板来定义UTF-8字符。
| 字符占用字节数 | 起始字节二进制格式 | 续字节二进制格式 | 可表示的Unicode码点范围 | 说明 |
|---|---|---|---|---|
| 1字节 | 0xxxxxxx |
无续字节 | U+0000 ~ U+007F |
对应ASCII字符 |
| 2字节 | 110xxxxx |
10xxxxxx |
U+0080 ~ U+07FF |
欧洲、中东等字符 |
| 3字节 | 1110xxxx |
10xxxxxx |
U+0800 ~ U+FFFF |
中文、日文、韩文等常用字符 |
| 4字节 | 11110xxx |
10xxxxxx |
U+10000 ~ U+10FFFF |
罕见字符、emoji等 |
眼见为实,以"中"举例
- 确定字节数
"中"这个字符的码点为U+4E2D,在U+0800~U+FFFF范围内,占用 3 字节。 - 十六进制转换成二进制
4E2D转成二进制,得到0100 1110 0010 1101
![image]()
- 按照UTF-8模板格式填充
已知占用3字节,模板格式为:1110xxxx10xxxxxx10xxxxxx(起始字节+2个续字节)
-----------得到UTF-8编码111001001011100010101101 - 二进制转换成十六进制
11100100=>0xE4
![image]()
10111000=>0xB8
![image]()
10101101=>0xAD
![image]()




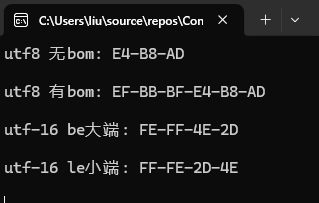
最终"中"这个字符的UTF-8编码序列是E4 B8 AD ,也就是我们日常中经常看到的UTF-8 十六进制表示
眼见为实,以"A"举例
- 确定字节数
"A"的码点为U+0041,在U+0000~U+007F访问内,占用1字节。 - 十六进制转换成二进制
0041转成二进制,得到0100 0001
![image]()
- 按照UTF-8模板格式填充
1字节的模板格式为:0xxxxxxx(起始字节)
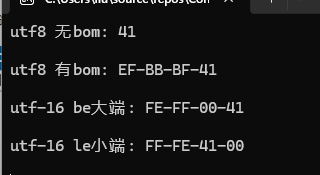
----得到UTF-8编码:01000001 - 二进制转换成十六进制
实际上又转换回来,又变回了0041。

UTF-8 以一种很
偷鸡又巧妙的办法 ,实现了与ASCII的兼容。
因为ASCII只占用7bit,最高位默认为0,而UTF-8,1字节的模板也是0xxxxxxx ,从而实现了与ASCII的兼容
回到主题
-
UTF-8 不存在大小端问题
由于UTF-8的可变长编码与标准的字节格式,所以每个字符的格式是固定的,有明确的先后顺序。
比如"中"的U+4E2D,UTF-8编码是E4-B8-AD, 这三个字节的顺序是唯一且固定的,解析时如果顺序颠倒,就会解析失败,所以不用管大端还是小端,严格按照顺序解析即可。 -
UTF-8能够自我解析/识别,无需BOM作为签名
BOM 还有一个附加作用:作为文件编码的 “签名”,帮助软件快速识别 Unicode 编码格式。但对于 UTF-8 而言,这种 “签名” 也是多余的。
因为解析软件可以通过扫描文本的二进制内容,根据UTF-8的格式规则,(上面提到的0xxxxxxx、110xxxxx等),直接判断文件是否为 UTF-8 编码,无需依赖文件开头的 BOM 标记
为什么有UTF-8 BOM的存在?
UTF-8 BOM并非Unicode官方标准,而是微软为解决兼容问题而留下的历史包袱。
早期的Windows默认编码是 本地化ANSI,它是Windows早期为适配本地语言设计的历史编码方案,它千好万好,为windows全球化立下了汗马功劳,但有一个致命的缺点,文件开头没有任何特殊标识。
比如中文系统默认 GBK/GB2312,英文系统默认 ISO-8859-1,日文系统默认 Shift_JIS—— 这些 ANSI 编码都是无标记的多字节编码,和 UTF-8 一样,文件开头没有任何特殊标识。

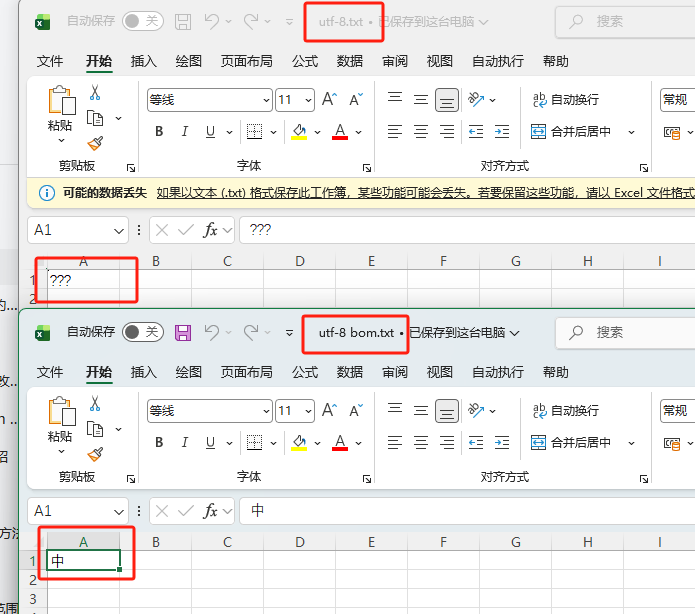
眼见为实
比如用户在记事本中写了字符"中",保存为 UTF-8(无 BOM),下次打开时,记事本没有任何标记可以判断这是 UTF-8,可能会按照系统ANSI ,比如GBK来解析,导致出现乱码。
为什么中文在UTF-16下占用2字节,反而在UTF-8中占用3字节了?
简单来说,就是运气问题,UTF-8 的字节数是按码点容量分层设计的,中文的码点大小决定了它只能落在 3 字节区间。
我们日常使用的 99% 以上的中文,码点都在BMP 平面的U+4E00(一)~U+9FA5(龥) 区间,
而UTF-16的编码规则是,对BMP平面字符直接用2字节编码,对SMP平面用4字节编码。而刚好落在BMP的中文码点自然而然的就使用2字节编码
但UTF-8的编码规则是根据Unicode 码点的大小来决定字节数,而中文的U+4E00~U+9FA5 刚好落在了U+0800 ~ U+FFFF这个3字节码点的区间内,因此要遵守3字节编码的规则。
为什么UTF-8不把中文设计为2字节?
主要是2字节的UTF-8区间U+0080 ~ U+07FF容量有限,装不下这么多中文。
2字节的UTF-8 去掉前面的110,10 标识位,只剩下5+6=11位的有效容量,只能表示2^11=2048个码点,容纳不下中文。只有3字节的有效容量是4+6+6=16 ,可以表示2^16=65536个码点,刚好覆盖整个 BMP 平面,足以容纳所有中文常用字。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号