
给自己看的mongoDB快速入门
简介
最近公司项目用到了mongoDB,快速学习实操一把,加深了解。
MongoDB 是一款开源、跨平台的文档型 NoSQL 数据库(非关系型数据库) ,主打「灵活、高性能、易扩展」,是目前最主流的 NoSQL 数据库之一。
数据以「文档(Document)」为基本单位存储,格式是 BSON(二进制 JSON,兼容 JSON 并扩展了日期、二进制、数值等类型),类似我们熟悉的 JSON 对象:
{
_id: ObjectId("654321f98765432109876543"), // 默认唯一主键(不可修改)
name: "张三",
age: 25,
tags: ["前端", "MongoDB"],
createTime: ISODate("2025-01-01T00:00:00Z")
}
Redis/MongoDB/数据库之间的互相协作
三者的本质差异是 “设计目标与核心场景不同”:关系型数据库主打「结构化数据+强事务+复杂联表」,MongoDB 主打「半结构化数据+灵活扩展+复杂查询」,Redis 主打「高频数据+极致性能+轻量功能」。
| 对比维度 | 关系型数据库(MySQL/PostgreSQL) | MongoDB(文档型 NoSQL) | Redis(内存型键值 NoSQL) |
|---|---|---|---|
| 核心定位 | 通用型结构化数据持久存储(“系统核心数据库”) | 灵活文档型数据持久存储(“替代部分 MySQL 场景”) | 高性能内存缓存/轻量功能实现(“系统加速器”) |
| 数据模型 | 固定 Schema(表结构+行列),支持外键关联 | 动态 Schema(BSON 文档,类似 JSON),支持嵌套/数组,无外键 | 键值对模型(支持字符串、哈希、列表、有序集合等 8 种数据结构) |
| 存储方式 | 磁盘存储(内存作为查询缓存),数据持久化是核心设计 | 磁盘存储(优化了文档存储引擎),默认持久化,支持内存缓存加速 | 内存存储(核心),可选持久化(RDB/AOF,非核心目标,持久化会降性能) |
| 查询能力 | 极强:支持 SQL 语法、复杂联表(JOIN)、分组(GROUP BY)、子查询、窗口函数等 | 强:支持类 SQL 过滤、排序、分页、聚合(类似 GROUP BY)、地理空间查询、文本搜索,无原生联表(需通过聚合模拟) | 弱:仅支持“键查询”+ 数据结构原生操作(如有序集合范围查询、哈希字段查询),无复杂过滤/聚合 |
| 事务支持 | 完全支持 ACID 事务(多表/多行原子性、一致性、隔离性、持久性),适合核心业务 | 4.0+ 支持多文档事务(ACID),但性能/隔离级别弱于 RDBMS;单文档事务原生支持 | 仅支持“单命令原子性”,多命令需通过乐观锁(WATCH)实现弱事务,无完整 ACID 保障 |
| 性能特点 | 读写性能稳定(万级 QPS),复杂联表/大数据量查询延迟较高(毫秒级) | 读写性能优秀(万级 QPS),文档查询效率高,延迟毫秒级(略优于 RDBMS 复杂查询) | 极致高性能(百万级 QPS),延迟微秒级(内存直接操作),远超磁盘数据库 |
| 数据容量 | 支持海量数据(TB/PB 级),依赖磁盘扩容,适合长期存储 | 支持海量数据(TB/PB 级),原生分片支持水平扩展,磁盘存储成本低 | 受限于内存容量(GB 级),大容量场景硬件成本极高,不适合长期存储 |
| 扩展能力 | 垂直扩展(升级硬件)容易,水平扩展(分库分表)复杂(需中间件如 ShardingSphere) | 原生支持分片(Sharding)+ 副本集,水平扩展简单,适合分布式场景 | 支持主从复制、哨兵模式、集群分片(Redis Cluster),扩展适合缓存场景(不适合海量数据存储扩展) |
| 核心优势 | 强事务、数据一致性、结构化存储、复杂联表查询、成熟稳定 | 灵活无 Schema、文档模型贴近业务、复杂查询能力、易扩展、持久化可靠 | 极致性能、丰富数据结构、原子操作、支持过期时间/发布订阅/分布式锁 |
| 典型场景 | 金融交易、电商订单核心、用户账户、ERP 系统(需强事务+结构化数据) | 用户详情、商品内容、日志分析、CMS 系统(需灵活结构+复杂查询+持久化) | 缓存(减轻数据库压力)、秒杀限流、计数器、实时排行榜、消息队列、分布式锁、Token 存储 |
| 数据可靠性 | 极高(磁盘持久化+事务+日志恢复) | 高(磁盘持久化+副本集故障转移) | 中(内存数据易丢失,依赖持久化+主从复制,容灾能力弱于前两者) |
三者的“互补关系”
用户请求 → Redis(缓存层:热门数据、Token、计数器)
↓
MongoDB/MySQL(业务存储层:用户/商品/订单数据)
↓
MySQL(核心交易层:支付、账务等强事务场景)
示例(电商平台):
- MySQL:存储支付记录、用户账户余额、订单核心信息(强事务+一致性要求);
- MongoDB:存储商品详情(多规格、富文本,结构灵活)、用户行为日志(非结构化,需聚合分析);
- Redis:缓存热门商品数据(减少 MongoDB 查询压力)、实现秒杀库存计数器(原子操作防超卖)、存储用户登录 Token(过期自动清理)。
与数据库类似的地方
| MongoDB | Mysql |
|---|---|
| 集合Collection | 表Table |
| 文档Document | 行Row |
| 字段Field | 列Column |
| 索引Index | 索引Index |
| _id | 主键Primary Key |
| $lookup | join |
| $group | group by |
基本操作
help 帮助命令
test 默认数据库
命令符前面的test,代表当前正在使用的数据库名称, test 是mongodb的一个默认数据库,是一个空数据库,并没有被创建。mongodb的特点就是,只有真正有数据才会创建
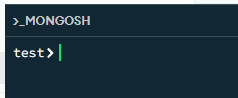
show database/show dbs 查看当前有哪些数据库
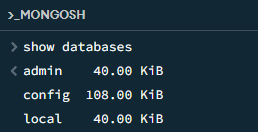
use xxx 切换数据库
tips:如同test一样,mongodb可以use 一个不存在的数据库,你也可以use game(game数据库并不存在),也不会造成任何问题。直到插入了数据,才会真正创建数据库。
insertOne/insertMany 插入数据
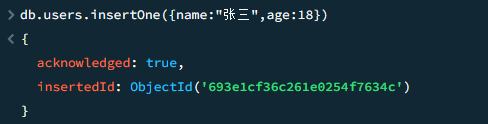
tips:可以看到,我们并没有提前构建列的schemad
limit 限制返回
sort 排序
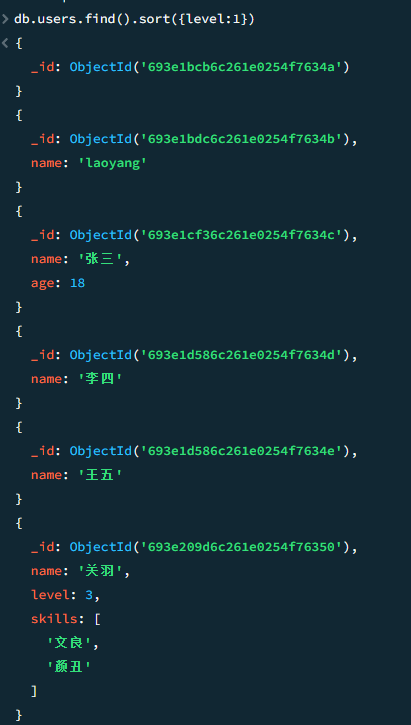
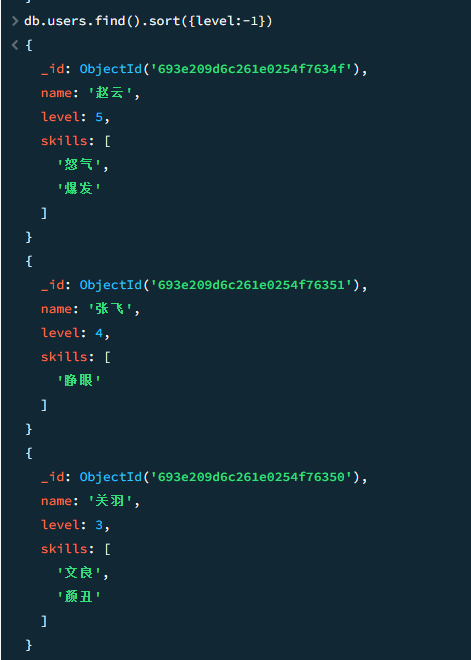
tips : 1代表升序,-1代表降序
skip 跳过查询结果
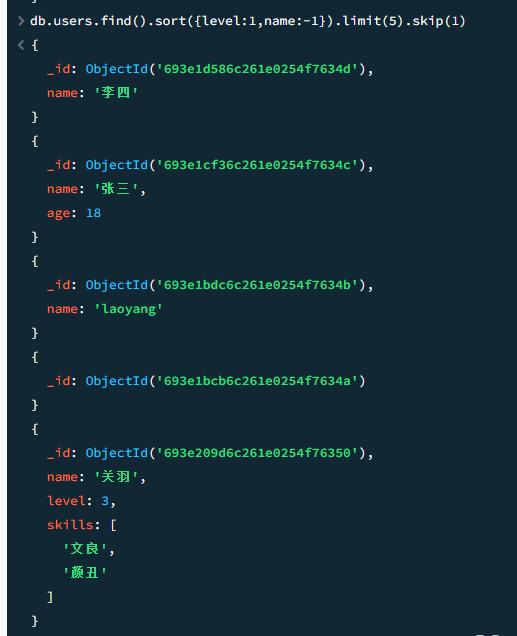
一般来说,sort+limit+skip 就能实现分页了
find 条件查询
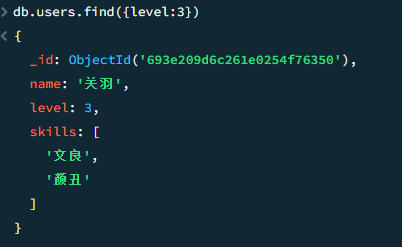
严格的数据类型
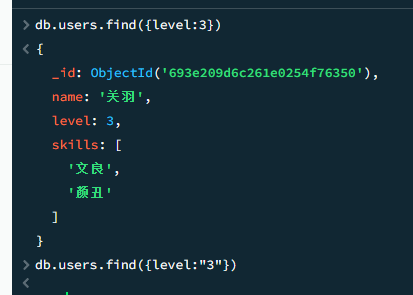
mongo db 对于数据类型非常严格,传入是字符串的话,就会严格按照string 3来查找,而不是查找int 3
select 返回特定字段
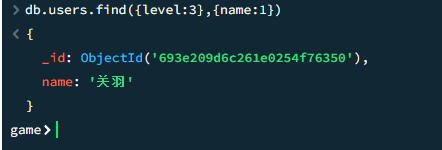
类似sql 中select xxx,xxx,xxx from table where level=3
其中_id是mongodb默认返回的,如果不想返回,可以追加一个_id:0
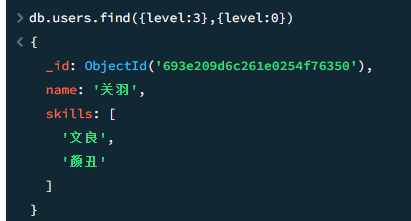
也可以取反,返回除了level之外的所有字段
$gt,$gte/$lt,$lte
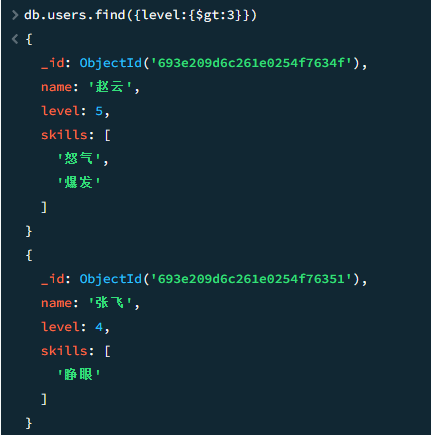
等价于SQL中的 >,>=,<,<=
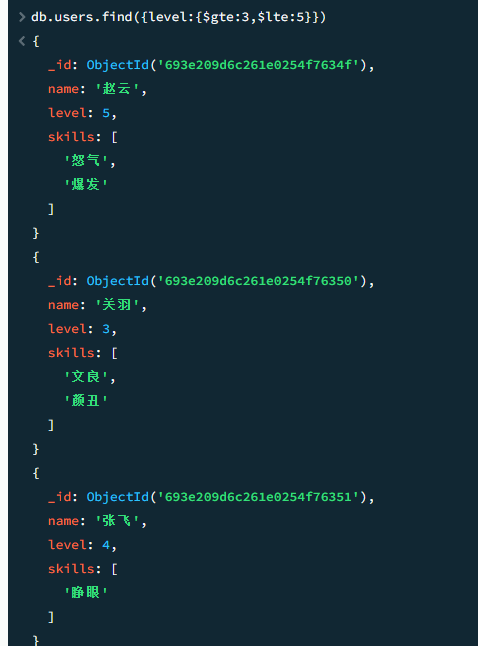
组合使用,实现类似between效果
$in/$nin
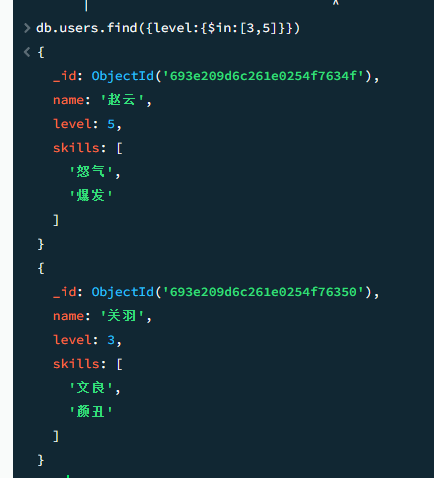
等价于SQL中的 In
$exists 字段是否存在
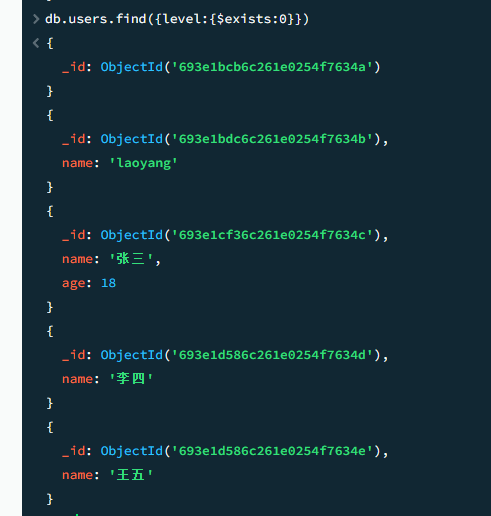
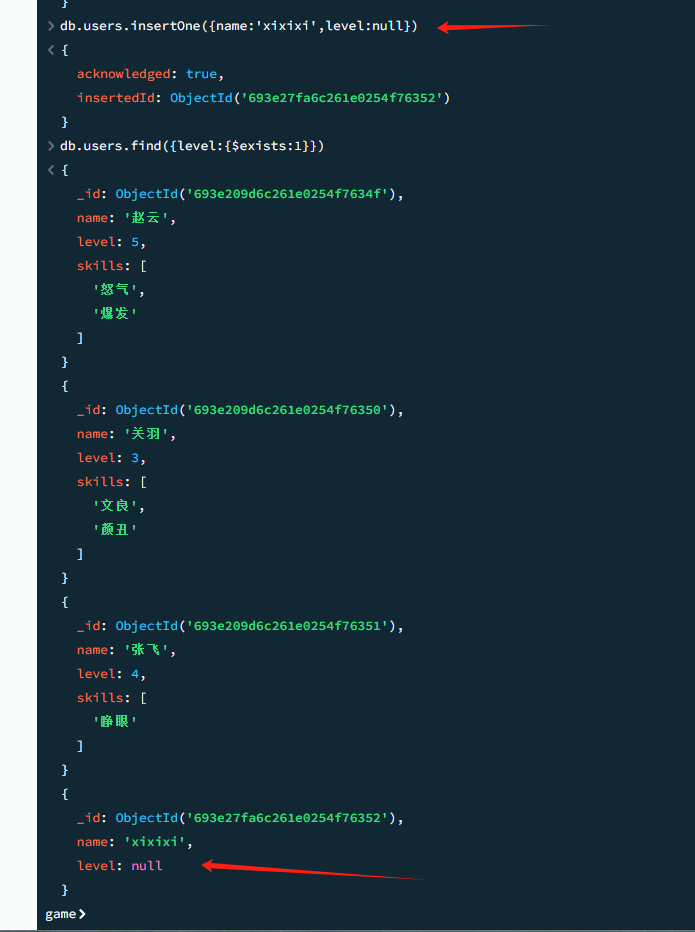
特别需要注意的是,$exists只能查询字段是否存在,不能查询字段的值是否存在
and/or
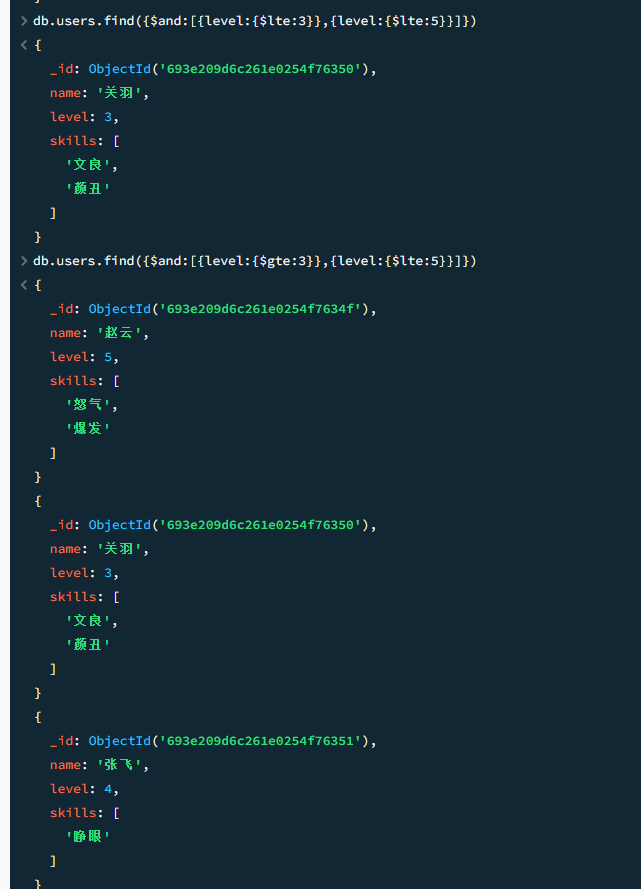
db.users.find({$and:[{level:{$gte:3}},{level:{$lte:5}}]})
$not 不等于
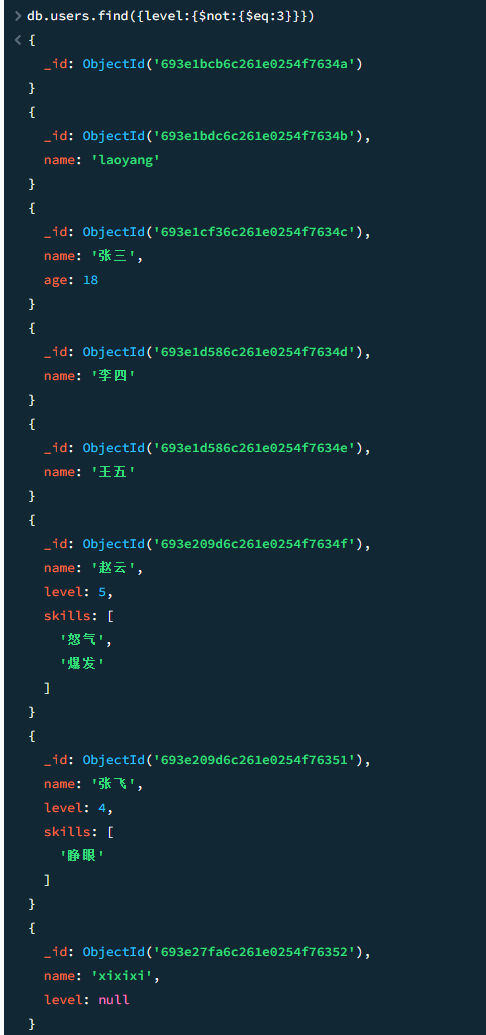
db.users.find({level:{$not:{$eq:3}}})
$regex 正则
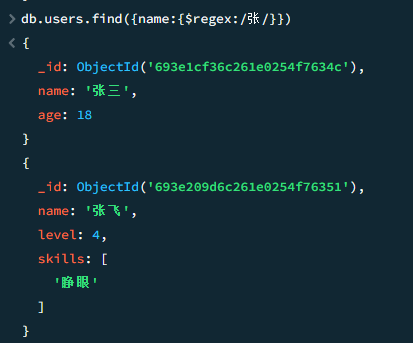
db.users.find({name:{$regex:/张/}})
聚合
countDocuments 统计数量
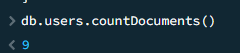

db.users.countDocuments()
db.users.countDocuments({level:3})
updateOne/updateMany 更新字段
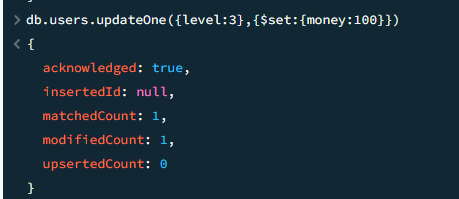
如果被更新的字段不存在,mongodb也会帮我们自动创建
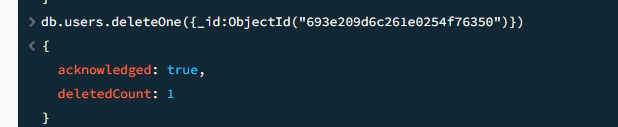
deleteOne/deleteMany 删除数据
游标方法执行顺序
MongoDB处理sort/skip/limit有固定的顺序,不会按照调用顺序执行。
比如db.users.find().sort({level:1,name:-1}).limit(5).skip(1) ,你可能会误认为先取5条,再跳过1条。最后返回4条数据。
实际上mongoDB会按照sort=>skip=>limit顺序执行。
完整的执行顺序如下:
db.users.find({age: {$gt: 18}}) // 先过滤条件
.sort({level:1}) // 再排序
.skip(1) // 再跳过
.limit(5) // 再限制条数
.project({name:1, level:1}) // 最后投影字段
总结


 浙公网安备 33010602011771号
浙公网安备 33010602011771号