

字符编码知多少(一)
前言
曾经在一场面试中,问到过UTF-8与UTF-16的区别,我一脸懵逼,惨遭羞辱。
最近在使用rider这个IDE的过程中,发现在visual studio中好好的代码,在rider中是乱码。
故此深入了解一下字符编码的前世今生。
前世:编码的蛮荒时代
由于计算机只能存储0/1二进制数据,因此计算机字符编码的起点,本质是为了解决字符与二进制数据的映射问题。
ASCII
计算机诞生于美国,因此最早的编码需求仅针对英文字符。1967年发布的ASCII(American Standard Code for Information Interchange)成为第一个通用编码:
- 特点
使用一个字节(8位)中的低7位来表示字符,因此可以表示2^7=128个字符。
其内容主要包括,英语字母的大小写,数字0-9,标点符号,以及一些控制字符(换行\n,回车\r等符号)。 - 优点
简单,高效,仅占1个字节,完全满足英文场景下的计算机使用需求,成为计算机编码的底层基石。 - 缺点
只能表示英语字符,对于其它语言捉襟见肘。
眼见为实
var originalString = "C#编程";
Console.WriteLine($"originalString = {originalString}");
//ASCII编码
try
{
var asciiBytes=Encoding.ASCII.GetBytes(originalString);
Console.WriteLine($"ASCII 编码 (字节数: {asciiBytes.Length}):");
Console.WriteLine($" 字节: {BitConverter.ToString(asciiBytes)}");
Console.WriteLine($" 解码回字符串: \"{Encoding.ASCII.GetString(asciiBytes)}\"");
}
catch (Exception)
{
Console.WriteLine("ASCII 解码失败");
}
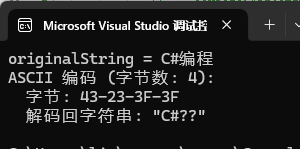
可以看到,对于英文字符C,与特殊符号# 。 ASCII能够正常编码解码,但对中文就无能为力了。
拓展ASCII与多字节字符(MBCS)
鉴于ASCII的缺点,各国为了能在计算机中表示自己的语言,开始制定自己的编码标准。
同样是英文语系的西欧语言,选择利用ASCII的最高位,将编码范围拓展到2^8=256个,比如ISO 8859-1。
- 特点
前128位与ASCII完全一致,拓展了后128位。补充了西欧重音字符以及特殊符号 - 缺点
仅覆盖西欧,对亚洲,非洲,俄文依旧不支持。
由于ASCII与ISO-8859-1无法满足多语言需求,各国纷纷开始定制专属的本地化编码,只为适配本国文字,毫无兼容性可言,因此开始了编码最混乱的时代。
像中文这样拥有成千上万字符的语言,靠拓展ASCII是远远不够的,一个字节最多表示256个字符,所以人们发明了多个字节来表示一个字符的方法。
- GB2312
作为中国的国家标准,GB2312大约收录了6763个常用汉字,后续推出的GBK作为其超集(支持1-2字节编码,覆盖更多生僻汉字和符号),GB18030则进一步扩展为1-4字节编码,兼容GBK并覆盖全球所有字符。 - BIG5
中国台湾/香港地区使用的繁体中文编码标准 - Shift_JIS
日本使用的编码标准
这个时候的核心问题在于,大多数国家和地区都各自为政,互不兼容。比如一个GBK编码的文件,在使用Big5编码的程序中打开,就会显示为乱码。
编码之间的混乱,导致了软件开发,数据交互的国际化几乎是不可能的。
眼见为实
// 错误地使用UTF-8来解码GBK的数据
try
{
Encoding gbk = Encoding.GetEncoding("GBK");
var gbkData = gbk.GetBytes(originalString);
string garbledText = Encoding.UTF8.GetString(gbkData);
Console.WriteLine($"GBK原始字节: {BitConverter.ToString(gbkData)}");
Console.WriteLine($"用UTF-8错误解码的结果: \"{garbledText}\"");
}
catch (Exception)
{
Console.WriteLine("解码失败");
}
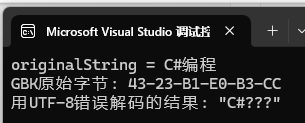
使用UTF-8来解码GBK,会乱码。
过渡:Unicode 字符集的诞生
本地化编码的乱象,催生出一个核心诉求:给全球所有的字符分配唯一的数字编号,彻底摆脱编码冲突。
所以Unicode诞生的应运而生,它作为字符=>数据的映射表,它为世界上所有的文字分配了一个唯一的数据编号,这个编号被称为码点,格式为U+XXXX(XXXX为16进制数字)。
- 码点范围
U+0000 ~ U+10FFFF,共划分17个平面。 - 核心平面
码点范围 U+0000 ~ U+FFFF,覆盖了全球 99% 的常用字符(中英文、数字、主流符号、日韩常用字等)。 - 拓展平面
剩余 16 个平面,用于表示生僻字、古文字、Emoji、专业符号等。
| 平面编号 | 平面名称 | 码点范围 | 核心用途 | 日常使用频率 |
|---|---|---|---|---|
| 0号 | 基本多文种平面(BMP) | U+0000~U+FFFF | 英文/中文/数字/主流符号 | ✅✅✅ 100% |
| 1号 | 多文种补充平面(SMP) | U+10000~U+1FFFF | Emoji/古文字/音乐符号 | ✅✅ 偶尔 |
| 2~3号 | CJK扩展平面A/B | U+20000~U+3FFFF | 中文生僻字/古汉字 | ✅ 极少 |
| 4~13号 | CJK扩展C~G+其他扩展 | U+40000~U+DFFFF | 极生冷僻字/专业符号 | ❌ 几乎无 |
| 14号 | 补充特殊用途平面(SSP) | U+E0000~U+EFFFF | 专业自定义字符 | ❌ 无 |
| 15~16号 | 私用使用区(PUA) | U+F0000~U+10FFFF | 完全自定义字符/保留区 | ❌ 无 |
今生:UTF系列编码
虽然Unicode解决了编码的乱象,却没有规定这个数字编码应该怎么存储.
比如汉字”中“的码点是U+4E2D,这个十六进制的数字可以存为2字节,4字节。传输过程中还会遇到大端法/小端法的顺序问题。
而UTF(Unicode Transformation Format)就是这么一组编码方案。简单来说Unicode 是字符集(定义码点),而 UTF-8/16/32 是「Unicode 编码方案」(将码点转换为字节序列的规则)。
UTF-32
UTF-32是Unicode最早的实现方案,思路极其简单。固定使用4个固定字节来表示一个Unicode码点,无脑将码点转换成一个32位的二进制来存储。
优点
- 编码/解码逻辑最简单:固定4字节表示1个Unicode码点,直接映射码点数值,无需判断长度/代理对/字节序;
- 完美随机访问:字符位置与字节位置一一对应(字符数=字节数/4),极致适合字符精准定位的底层场景。
缺点
- 空间浪费极致严重:所有字符均占4字节,纯英文文本比ASCII浪费300%,纯中文比UTF-8浪费33%,比UTF-16浪费100%;
- 生态支持极少:几乎无主流协议/数据库/编程语言支持,仅部分底层系统/学术场景偶尔使用;
- 传输/存储成本过高:完全不适合网络传输、文件存储,仅能用于内存临时处理的极特殊场景。
眼见为实
//UTF32编码
try
{
var utf32Bytes = Encoding.UTF32.GetBytes(originalString);
Console.WriteLine($"UTF-32 (Unicode) 编码 (字节数: {utf32Bytes.Length}):");
Console.WriteLine($" 字节: {BitConverter.ToString(utf32Bytes)}");
Console.WriteLine($" 解码回字符串: \"{Encoding.UTF32.GetString(utf32Bytes)}\"");
Console.WriteLine();
}
catch (Exception)
{
Console.WriteLine("UTF-32 解码失败");
}
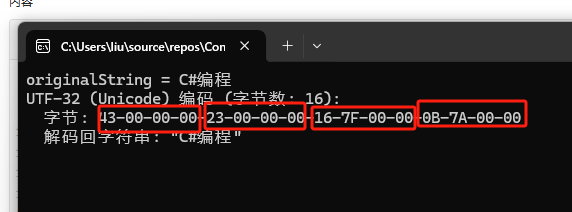
可以看到,空间浪费极其严重。总共用了 16 个字节。每个字符都占 4 个字节。
UTF-16
于1996年推出,是对UTF-32的优化,也是可变长度编码的首次尝试。
针对Unicode的BMP字符,用2字节存储,超出BMP的拓展字符,用2个2字节(代理对)拼接存储(共4字节)
优点
- BMP平面字符固定2字节:常用中文(U+4E00~U+9FFF)、英文、主流符号均占2字节,纯中文场景空间效率远高于UTF-8;
- 字符处理更高效:BMP内可随机访问字符,计算长度、截取字符串无需遍历,直接按字节数/2即可,适合编程语言内部存储;
- 原生适配主流语言运行时:.NET的
string类型、Java的char类型、JavaScript的String类型、Windows内核均原生基于UTF-16实现,无编码转换损耗。
缺点
- 不兼容ASCII:英文/数字也占2字节,纯英文文本空间浪费100%,混合文本效率低于UTF-8;
- 存在字节序问题:分UTF-16BE(大端)、UTF-16LE(小端),跨平台传输必须加BOM标记,否则必乱码;
- 非BMP字符需代理对:生僻字/Emoji(扩展平面)需用「2个2字节」拼接(代理对),占4字节,解码时需额外处理代理对逻辑,易出bug;
- 生态兼容差:互联网协议/数据库/前端均不默认支持,仅适用于编程语言内部/Windows系统,跨端传输需转UTF-8。
眼见为实
//UTF16编码
try
{
var utf16Bytes = Encoding.Unicode.GetBytes(originalString);
Console.WriteLine($"UTF-16 (Unicode) 编码 (字节数: {utf16Bytes.Length}):");
Console.WriteLine($" 字节: {BitConverter.ToString(utf16Bytes)}");
Console.WriteLine($" 解码回字符串: \"{Encoding.Unicode.GetString(utf16Bytes)}\"");
Console.WriteLine();
}
catch (Exception)
{
Console.WriteLine("UTF-16 解码失败");
}
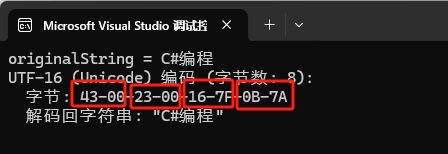
相对UTF-32,存储空间占用有了极大改善,总共用了 8 个字节。每个字符都占 2 个字节(因为 "编程" 在 BMP 范围内)。
UTF-8
当前版本答案,于1992年推出。是目前最主流,最通用的Unicode编码方案。
根据字符的码点大小,动态分配字节数。
✔ 英文字母,数字占用1字节
✔ 欧洲,西亚文字占用2字节
✔ 中/日/韩文占用3字节
✔ 生僻字,Emoji,拓展符号占用4字节
优点
- 完全兼容ASCII:ASCII字符(英文/数字/基础标点)占1字节,与传统ASCII文件无缝互通,无历史兼容成本;
- 无字节序问题:无需BOM标记,跨平台(Linux/Mac/Windows)、跨系统传输零乱码风险;
- 空间效率均衡:混合文本(英文+中文+符号)场景下,整体空间利用率最高(英文1字节抵消中文3字节的损耗);
- 生态兼容无敌:HTML/JSON/HTTP/数据库/主流编程语言/文件系统均默认支持,是互联网、后端开发的唯一标准;
- 错误容错性强:自同步编码规则,解码时可快速识别字符边界,局部错误不会导致整段乱码。
缺点
- 中文/日韩字符占3字节:纯中文文本场景,比UTF-16多占用1字节/字符;
- 变长解码稍复杂:1-4字节可变长度,需通过首字节判断字符长度,无法随机访问字符(计算字符串长度需遍历,而非直接取字节数/2);
- 纯东亚文本空间稍浪费:无任何英文的纯中文/日文文本,空间占用比UTF-16高50%。
眼见为实
//UTF8编码
try
{
var utf8Bytes = Encoding.UTF8.GetBytes(originalString);
Console.WriteLine($"UTF-8 编码 (字节数: {utf8Bytes.Length}):");
Console.WriteLine($" 字节: {BitConverter.ToString(utf8Bytes)}");
Console.WriteLine($" 解码回字符串: \"{Encoding.UTF8.GetString(utf8Bytes)}\"");
Console.WriteLine();
}
catch (Exception)
{
Console.WriteLine("UTF-8 解码失败");
}
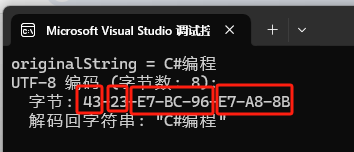
总共用了 8 个字节。C(43), #(23) 各占 1 个字节,“编”(E7-BC-96) 和 “程”(E7-A8-8B) 各占 3 个字节。
挖坑待埋
- 为什么中文在UTF-16下占用2字节,反而在UTF-8中占用3字节了?
- UTF-16/UTF-8都是不定长编码规则,它们是如何解析的?
- UTF-16的BOM标记长什么样?
- 未完待续......

 浙公网安备 33010602011771号
浙公网安备 33010602011771号