
20244216 实验四《Python程序设计》实验报告
课程:《Python程序设计》
班级: 2442
姓名: 白程聿
学号:20244216
实验教师:王志强
实验日期:2025年5月13日
必修/选修: 公选课
1.实验内容
Python综合应用:爬虫、数据处理、可视化、机器学习、神经网络、游戏、网络安全等。
大学英语四六级考试是每位大学生都要面对的,为此,我利用爬虫技术编写了一个程序,用于爬取网页的英语高频词进行学习。
2. 实验过程
(一)导入依赖库

urllib.request :Python内置的HTTP请求库,用于发送网络请求、获取网页内容。
re :处理正则表达式,用于移除HTML标签、提取单词等文本清洗操作。
time :记录爬取、处理、分析各阶段的耗时,并生成报告时间戳。
Counter :简化词频统计流程,快速计算单词出现次数。
(二)定义核心函数

参数: url 为目标网页的URL,通过交互式输入获取。
功能:封装爬取、文本处理、词频分析、结果输出的完整流程。
(三)爬取网页内容

设置请求头User-Agent,模拟真实浏览器
使用with语句进行自动连接
忽略错误字符减少错误率
(四)提取文本内容

本环节借鉴网络及ds,学习通过正则表达式匹配标签;过滤特殊字符;进行空格标准化
(五)分析词频,以此为依据生成并输出报告
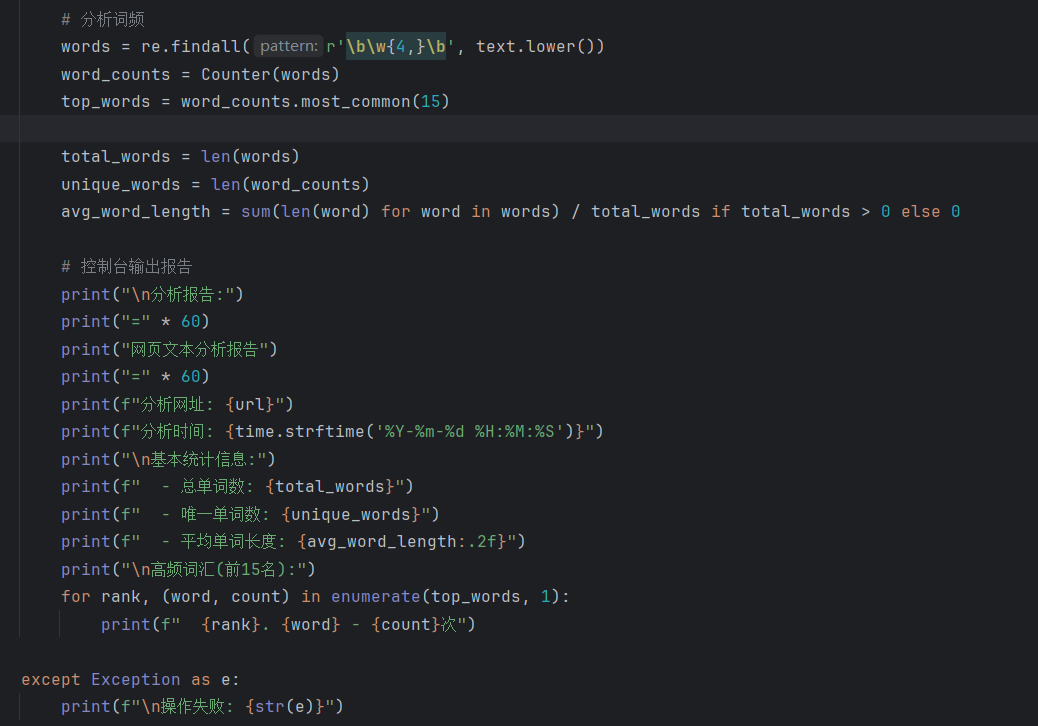
单词提取规则: r'\b\w{4,}\b' 确保只提取由字母组成、长度≥4的单词(如 'hello' ),排除短词(如 'a' , 'the' )和非单词字符。
Counter 用法:自动统计单词出现次数, most_common(15) 按频率降序返回前15个单词。
数据过滤:通过 text.lower() 将文本转为小写,确保 'Hello' 和 'hello' 被视为同一个单词。
最后按照各种规则输出
在异常时提示错误
(六)交互式输入与协议补全(主程序入口)
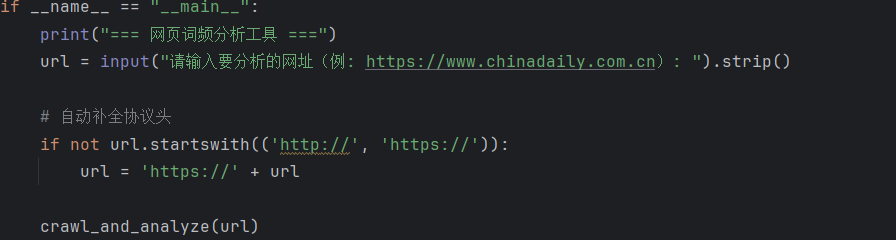
输入处理: strip() 去除输入前后的空格,避免因多余空格导致URL无效。
协议补全:自动为裸网址(如 example.com )添加 https:// ,简化用户输入。
完整程序
点击查看代码
import urllib.request
import re
import time
from collections import Counter
def crawl_and_analyze(url):
"""爬取网页文本并分析词频"""
try:
print(f"\n正在爬取网页: {url}")
print("=" * 60)
# 爬取网页内容
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/91.0.4472.124 Safari/537.36'
}
req = urllib.request.Request(url, headers=headers)
with urllib.request.urlopen(req) as response:
html = response.read().decode('utf-8', errors='ignore')
# 提取文本内容
text = re.sub(r'<[^>]+>', ' ', html)
text = re.sub(r'[^\w\s]', ' ', text)
text = re.sub(r'\s+', ' ', text).strip()
# 分析词频
words = re.findall(r'\b\w{4,}\b', text.lower())
word_counts = Counter(words)
top_words = word_counts.most_common(15)
total_words = len(words)
unique_words = len(word_counts)
avg_word_length = sum(len(word) for word in words) / total_words if total_words > 0 else 0
# 控制台输出报告
print("\n分析报告:")
print("=" * 60)
print("网页文本分析报告")
print("=" * 60)
print(f"分析网址: {url}")
print(f"分析时间: {time.strftime('%Y-%m-%d %H:%M:%S')}")
print("\n基本统计信息:")
print(f" - 总单词数: {total_words}")
print(f" - 唯一单词数: {unique_words}")
print(f" - 平均单词长度: {avg_word_length:.2f}")
print("\n高频词汇(前15名):")
for rank, (word, count) in enumerate(top_words, 1):
print(f" {rank}. {word} - {count}次")
except Exception as e:
print(f"\n操作失败: {str(e)}")
if __name__ == "__main__":
print("=== 网页词频分析工具 ===")
url = input("请输入要分析的网址(例: https://www.chinadaily.com.cn): ").strip()
# 自动补全协议头
if not url.startswith(('http://', 'https://')):
url = 'https://' + url
crawl_and_analyze(url)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号