

消息队列rabbitmq
消息队列
什么是消息队列
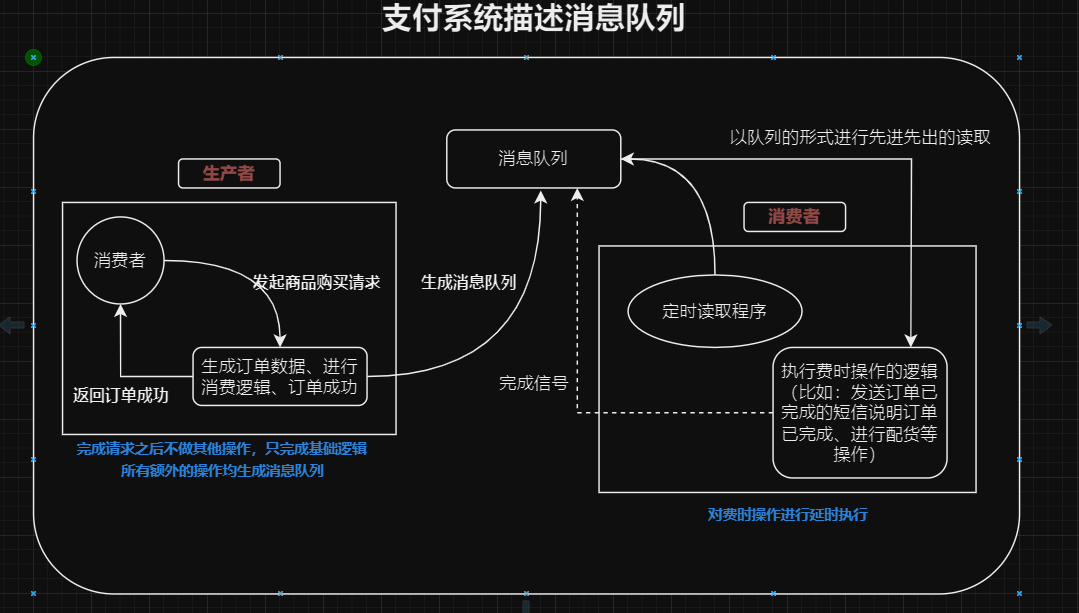
当程序系统发现某些任务耗费时间且优先级较低,迟点完成也不影响整个任务,就把这个任务丢给消息队列。
消息队列有什么好处
- 由于费时操作与基本业务相分离,系统的一部分组件失效时,不会影响到整个系統。
- 消费者可以不断的去开新的线程来处理业务,只需要让消息队列去接受返回值来确认业务是否完成。可以在确保正确性的情况下极大提高效率。
- 两边均具有可拓展性。对费时操作的拓展不会影响到主要逻辑
- 队列的先进先出的操作,可以对生产者的并发问题进行一定的缓解。
(消息无论是在生产者还是消费者,只能按照队列顺序进行处理) - 消息队列可以对得到的数据进行持久化,从而保证程序正确性和防止数据丢失(在未完成响应消费逻辑时不会自动删除)
rabbitmq消息队列
这里通过rabbitmq来介绍rabbitmq下载、rabbitmq-server服务端启动和rabbitmq_management插件启动。
启动rabbitmq-server和管理平台插件
# 通过apt或者yum下载erlang和rabbitmq-server
# 注意要做换源,换阿里云就行
# 也可以选择源码安装,直接去github拉就行了:https://github.com/rabbitmq/rabbitmq-server
apt/yum install erlang
apt/yum install rabbitmq-server
# 启动rabbitmq
systemctl start/stop/restart/status rabbitmq-server
# 开启rabbitmq管理后台
rabbitmq-plugins enable rabbitmq_management
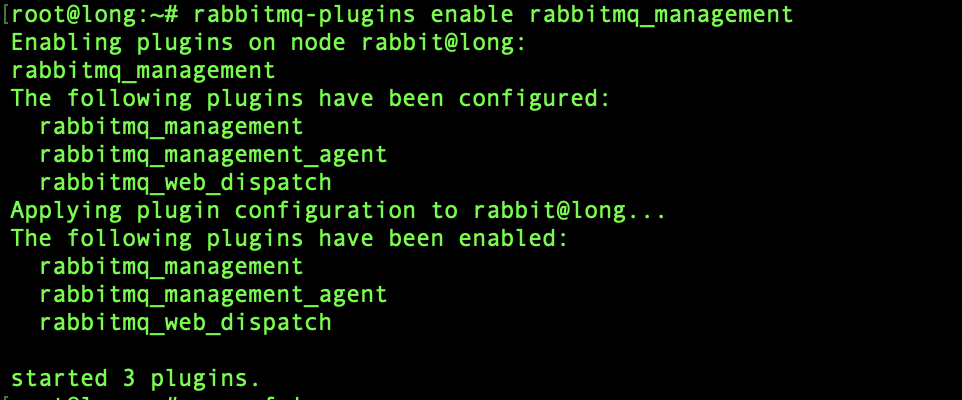
如图即为启动成功,接下来可以查找rabbitmq的后台运行端口,通过netstat查找到的服务端口如下:
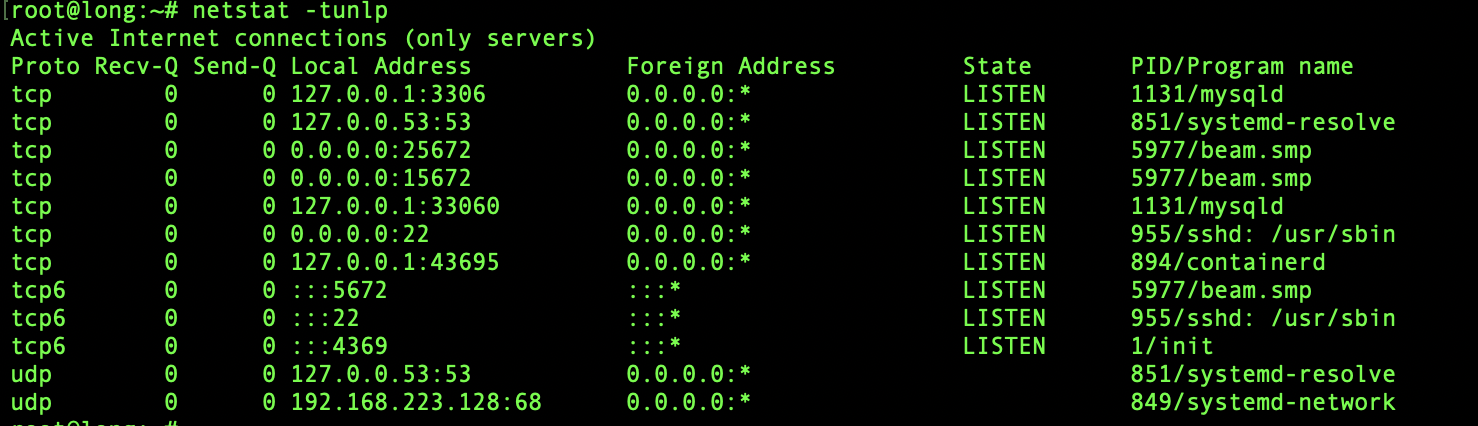
图中beam.smp即为运行端口。
查看端口可以看到如下页面:
设置账号密码查看消息队列
# 添加一个用户
rabbitmqctl add_user long 123
# 配置超级管理员权限
rabbitmqctl set_user_tags long administrator
# 给用户授权可以操作所有队列
set_permissions [-p <vhostpath>] <user> <conf> <write> <read>
rabbitmqctl set_permissions -p "/" long ".*" ".*" ".*"
接下来就可以正常登录了。
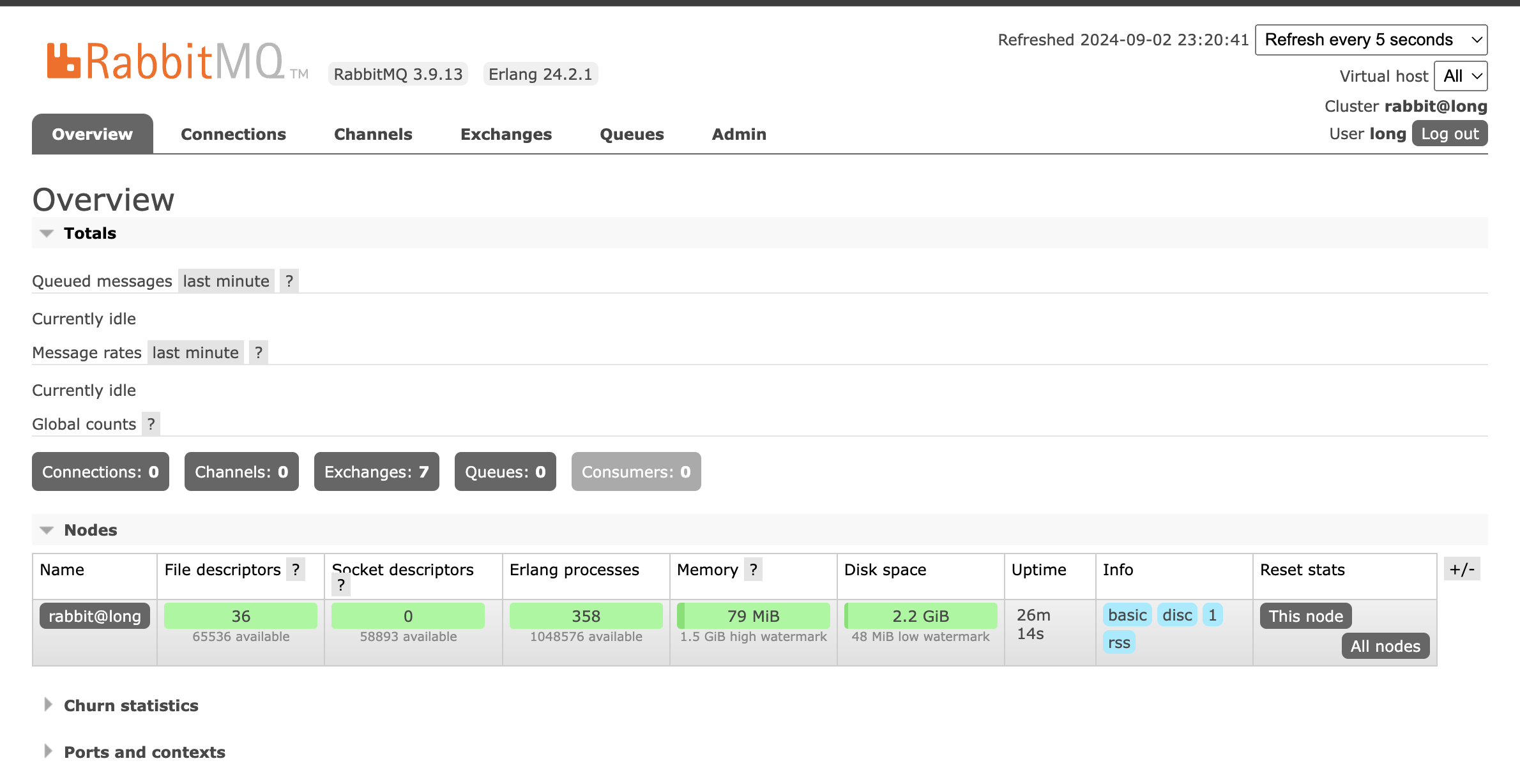
然后我们可以看到管理页面。其中队列管理如图所示:
通过python操作队列
使用pike库来进行队列操作
生产者代码
# 设置rabbitmq连接凭证
credentials = pika.PlainCredentials("long", "123")
# 配置连接参数,ConnectionParameters为(host=_DEFAULT,port=_DEFAULT,credentials=_DEFAULT,……)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.223.128',credentials=credentials))
# 执行rabbitmq连接
channel = connection.channel()
# 配置要操作的队列为hello
channel.queue_declare(queue='hello')
# basic_publish向队列发送信息routing_key为所绑定的队列情况
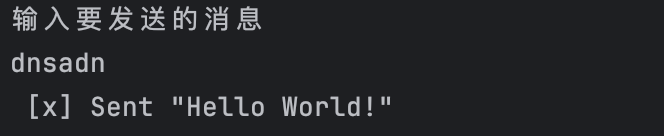
channel.basic_publish(exchange='', routing_key='hello', body=name)
print(f' [x] Sent "Hello World!"')
# 关闭连接
connection.close()
消费者代码
# 同上
credentials = pika.PlainCredentials("long", "123")
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.223.128',credentials=credentials))
channel = connection.channel()
channel.queue_declare(queue='hello')
# 构建一个信息回调函数,供消费者读取信息调用
def callback(ch, method, properties, body):
print(f' [x] Received {body.decode("utf-8")}')
ch.basic_ack(delivery_tag=method.delivery_tag)
# 消费者读取信息并调用回调函数。
# auto_ack为队列的一种读取方式
channel.basic_consume(queue='hello', on_message_callback=callback, auto_ack=False)
print(' [*] Waiting for messages. To exit press CTRL+C')
channel.start_consuming()
auto_ack的消费确认方式
-
当auto_ack为true时。消费者读取队列信息后会自动确认
-
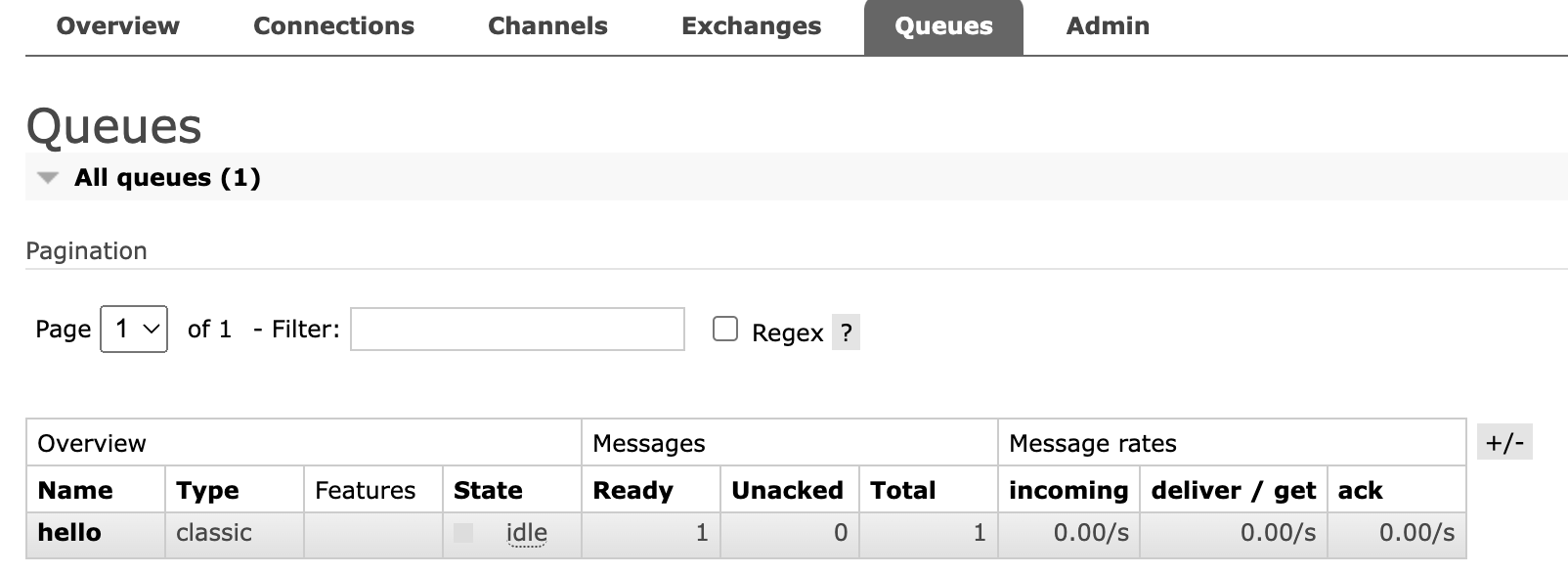
使用生产者向rabbitmq队列发送信息
![img]()
![img]()
-
使用消费者设置
auto_ack=False进行队列读取如若回调函数报错,消息队列仍会将消息移除,导致数据消失
def callback(ch, method, properties, body): int("hhh") print(f' [x] Received {body.decode("utf-8")}')![img]()
![img]()
所以在需要确保数据准确性的情况下,不建议使用
auto_ack=False的方式读取消息队列 -
-
当auto_ack为true时。
消费者读取队列信息后不会将数据删除,会等待接受一个回调之后才会删除队列信息。
def callback(ch, method, properties, body): print(f' [x] Received {body.decode("utf-8")}') ch.basic_ack(delivery_tag=method.delivery_tag)

rabbitmq消息队列持久化
消息的可靠性是RabbitMQ的一大特色,那么RabbitMQ是如何保证消息可靠性的呢——消息持久化。 为了保证RabbitMQ在退出或者crash等异常情况下数据没有丢失,需要将queue,exchange和Message都持久化。
- 生产者需要设置
durable=True队列持久化参数以及delivery_mode=2消息持久化参数
credentials = pika.PlainCredentials("long", "123")
# 配置连接参数,ConnectionParameters为(host=_DEFAULT,port=_DEFAULT,credentials=_DEFAULT,……)
connection = pika.BlockingConnection(pika.ConnectionParameters('192.168.223.128',credentials=credentials))
# 执行rabbitmq连接
channel = connection.channel()
# 实现rabbitmq持久化条件
# delivery_mode=2
# 使用durable=True声明queue是持久化
channel.queue_declare(queue='LOL',durable=True)
channel.basic_publish(exchange='',
routing_key='LOL',
body='德玛西亚万岁',
# 支持数据持久化
properties=pika.BasicProperties(
delivery_mode=2,#代表消息是持久的 2
)
)
connection.close()
- 消费者需要设置
durable=True队列持久化读取数据。并且使用auto_ack为true的方式发送回调,保证数据删除
channel.queue_declare(queue='LOL',durable=True)
'''
必须确保给与服务端消息回复,代表我已经消费了数据,否则数据一直持久化,不会消失
'''
def callback(ch, method, properties, body):
print("消费者接受到了任务: %r" % body.decode("utf-8"))
# 模拟代码报错
# int('asdfasdf') # 此处报错,没有给予回复,保证客户端挂掉,数据不丢失
# 告诉服务端,我已经取走了数据,否则数据一直存在
ch.basic_ack(delivery_tag=method.delivery_tag)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号