
DP 优化 (倍增 数据结构 单调队列 斜率优化 决策单调性 wqs二分 )
DP 优化
前言
动态规划的精髓实际在于状态设计和转移,而 DP 的各种优化方法都是在此基础上的。相较于前者,DP 的优化其实都比较套路化,但还是有必要学习。本文也只涉及了一部分。
倍增优化 DP
倍增通常可以用来优化那些其中一维是线性且转移确定的 DP。因为这种问题一般都可以将一段区间分为等长的前后两段,让每段区间的长度都为 \(2\) 的整数次幂,从而将时间复杂度其中的一维 \(O(n)\) 优化到 \(O(\log n)\)。
通常 DP 的状态中有一维 \(i\) 表示长度为 \(2^i\),这样的话就可以由两个长度为 \(2^{i-1}\) 的一前一后两个状态转移过来。
DP 的时候通常是先枚举 \(2\) 的指数 \(i\),再枚举另一维 \(j\),这样就能保证在枚举到 \((i,j)\) 的时候所有长度为 \(2^{i-1}\) 的状态都已经求出了。
ST 表
ST 表算法就可以认为是一个倍增优化 DP 。
暴力: \(f[i][j]=\max_{i\le k\le j}\{a[k]\}\)。
倍增优化可以设计状态为 \(f[i][j]\) 表示以 \(j\) 为左端点,长度为 \(2^i\) 的这个区间内的最大值。
初值设 \(f[0][i]=a[i]\)。
转移 \(f[i][j]=\max(f[i-1][j],f[i-1][j+2^{i-1}])\),就是取 \([j,j+2^{i-1}-1]\) 和 \([j+2^{i-1},i+2^{i}-1]\) 这两段的最大值。
void ST_init() {
for(int i=1;i<=n;++i) f[0][i]=a[i];
int t=log(n)/log(2)+1;
for(int i=1;i<=t;++i)
for(int j=1;j<=n-(1<<i)+1;++j)
f[i][j]=max(f[i-1][j],f[i-1][j+(1<<(i-1))]);
}
CF1175E Minimal Segment Cover
题目描述
有 \(n\) 条线段,形如 \([l,r]\)。有 \(m\) 个询问,问要覆盖 \([x,y]\) 至少需要多少条线段。
\(1\le n,m\le 2*10^5\),\(1\le l,r,x,y \le 5*10^5\)
Solution
设 \(f[i][j]\) 表示第 \(j\) 开始用 \(2^i\) 条线段最大能覆盖到的右端点(这些线段中最小的左端点不一定是 \(j\) )。
初值:\(f[0][i]=\max\{r[j]\}\,(l[j]<=i)\)。\(O(n)\) 扫一遍就可以预处理出 \(f[0][i]\)。
转移:\(f[i][j]=f[i-1][f[i-1][j]]\),非常常规的倍增转移,就是从 \(j\) 出发,选 \(2^{i-1}\) 条线段,然后从这个位置再选 \(2^{i-1}\) 条线段。
预处理出所有 \(f[i][j]\)。
查询:类似于倍增求 LCA 的跳法,从大到小枚举 \(2\) 的指数 \(i\),每次如果跳过去还不会超过 \(y\) 就跳过去,答案加上 \(2^i\)。记录下当前位置就可以实现。
#include <bits/stdc++.h>
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=500005,L=18;
int n,m,f[L+1][N],ma;
signed main() {
n=read(),m=read();
for(int i=1;i<=n;++i) {
int l=read(),r=read();
ma=max(ma,r);
f[0][l]=max(f[0][l],r);
}
for(int i=1;i<=ma;++i) f[0][i]=max(f[0][i],f[0][i-1]);
for(int i=1;i<=L;++i)
for(int j=0;j<=ma;++j)
f[i][j]=f[i-1][f[j][i-1]];
while(m--) {
int x=read(),y=read(),ans=0;
for(int i=L;i>=0;--i)
if(f[i][x]<y) x=f[i][x],ans+=1<<i;
if(f[0][x]>=y) printf("%d\n",ans+1);
else puts("-1");
}
return 0;
}
数据结构优化 DP
数据结构通常指的是线段树或者树状数组(平衡树当然也行),维护的通常是区间最值或者区间和,这样就可以把时间复杂度为 \(O(n)\) 的区间操作降到 \(O(\log n)\)。
LIS
最长上升子序列问题就可以用最简单的数据结构优化 DP 来做。
设 \(a[i]\) 表示第 \(i\) 个数的权值,\(f[i]\) 表示以 \(i\) 结尾的最长上升子序列的长度。
转移:\(f[i]=\max\{f[j]+1\}\,(\,1\le j<i,a[j]<a[i])\)。
暴力的转移枚举 \(i\) 和 \(j\) 时间复杂度是 \(O(n^2)\) 的。
发现有两个限制,其中一个是 \(1\le j<i\),这个只要从前往后枚举只管前面的就可以解决;另一个 \(a[j]<a[i]\),所以考虑以 \(a[i]\) 为下标,维护 \(f[i]\) 的前缀最大值,用树状数组或者线段树都可以解决。如果 \(a[i]\) 的值域过大就可以离散化一下。
具体实现:从 \(1\) 到 \(n\) 枚举 \(i\),每次在线段树或树状数组查询 \(1\) 到 \(a[i]-1\) 这段区间的最小值,然后把 \(f[i]\) 赋为这个值加一。再在 \(a[i]\) 这个位置加入 \(f[i]\)。
下面是 DP 部分的代码。
void DP() {
for(int i=1;i<=n;++i) {
int x=read();
f[i]=ask(x-1)+1;
add(x,f[i]);
}
}
洛谷 P3287 方伯伯的玉米田
题目描述
给定一个长度为 \(n\) 的序列 \(a[i]\)。可以进行 \(k\) 次操作,每次操作可以指定一个区间 \([l,r]\),使得 \(a[i]\gets a[i]+1\)。问所有可能的最终序列中最长的最长上升子序列的长度。
\(1\le n \le 10^4,1\le k \le 500\)
Solution
显然有一个结论:每次操作的区间的右端点一定是 \(n\)。因为是最长上升子序列,所以让后面的变大一定是不劣的。
设:\(f[i][j]\) 表示已经做了 \(j\) 个操作,且这 \(j\) 个操作的的左端点都小于等于 \(i\) 的状态下最长上升子序列的长度。这样设计状态就可以保证第 \(i\) 个数已经变成了 \(a[i]+j\),知道这个就可以转移了。
转移:\(f[i][j]=\max\{f[x][y]+1\}\,(1\le x<i,1\le y\le j,a[x]+y<a[i]+j)\)。就是选择一个最大的合法接上去。在 \(f[x][y]\) 这个状态中,\(a[x]\) 的值已经变成了 \(a[x]+y\),所以 \(a[x]+y\le a[i]+j\) 就是满足上升的条件。
考虑优化。第一个限制 \(x<i\) 只要是从小到大枚举 \(i\) 就肯定满足。要考虑的就是 \(1\le y\le j\) 和 \(a[x]+y\le a[i]+j\)。所以设 \((y,a[x]+y)\) 是一种状态,合法的状态就是一个左上角为 \((1,1)\) ,右下角为 \((j,a[i]+j-1)\) 的矩阵。所以只要维护这个矩阵的二维前缀最大值就可以快速转移了。
可以用二维树状数组和二维线段树,但树状数组要好写得多,所以建议用前者。
设 \(v=max\{a[i]\}+k\),总时间复杂度就是 \(O(nk\log v\log k)\)。
二维树状数组的数组 \(c[i][j]\) 管辖的就是宽为一维树状数组中 \(c[i]\) 管辖的范围,长为 \(c[j]\) 管辖的范围所构成的矩阵。
实现的时候两维都各自按照一维树状数组的方式来枚举就行了。
#include <bits/stdc++.h>
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=10005,K=505,M=5500;
int n,k,ans,a[N],f[N][K],t[K][M+5];
void add(int x,int y,int v) {
for(int i=x+1;i<=k+1;i+=(i&-i))
for(int j=y;j<=M;j+=(j&-j))
t[i][j]=max(t[i][j],v);
}
int ask(int x,int y) {
int res=0;
for(int i=x+1;i;i-=(i&-i))
for(int j=y;j;j-=(j&-j))
res=max(res,t[i][j]);
return res;
}
signed main() {
n=read(),k=read();
for(int i=1;i<=n;++i) a[i]=read();
for(int i=1;i<=n;++i)
for(int j=k;j>=0;--j) {
f[i][j]=ask(j,a[i]+j)+1;
add(j,a[i]+j,f[i][j]);
ans=max(f[i][j],ans);
}
cout<<ans;
return 0;
}
洛谷 P2605 基站选址
题目描述
有 \(n\) 个村庄坐落在一条直线上,第 \(i(i>1)\) 个村庄距离第 \(1\) 个村庄的距离为 \(d_i\) 。需要在这些村庄中建立不超过 \(k\) 个通讯基站,在第 \(i\) 个村庄建立基站的费用为 \(c_i\)。如果在距离第 \(i\) 个村庄不超过 \(s_i\) 的范围内建立了一个通讯基站,那么就村庄被基站覆盖了。如果第 \(i\) 个村庄没有被覆盖,则需要向他们补偿,费用为 \(w_i\)。现在的问题是,选择基站的位置,使得总费用最小。
\(n\le 20000,k\le \min(n,100)\)
Solution
设 \(f[i][j]\) 表示,前 \(j\) 个村庄内,建了 \(i\) 个基站,且第 \(i\) 个建在第 \(j\) 个村庄。
朴素的转移:\(f[i][j]=\min_{0\le k<j}\{f[i-1][k]+cost(k,j)\}\)。\(cost(k,j)\) 表示 \((k,j)\) 这个区间内的村庄没有基站,且第 \(j\) 个和第 \(k\) 个村庄有基站是 \(cost(k,j)\) 这个区间内的赔偿费用之和。
朴素转移是 \(O(n^2k)\) 的,且 \(f\) 数组中 \(i\) 这维可以直接不要,转移就变成 \(f[i]=\min_{0\le j<i}\{f[j]+cost(j,i)\}\)。
考虑数据结构优化。最直接的想法是用线段树维护最小值,所以问题在于怎么在 DP 的过程中维护 \(cost(j,i)\)。
考虑对于一个村庄会获得赔偿的条件。对于每一个村庄 \(i\) 求出 \(st[i]\) 和 \(ed[i]\) 分别表示编号最小的和最大的建立基站能使第 \(i\) 个村庄不会被赔偿的村庄。也就是说编号为 \([st[i],ed[i]]\) 这个区间内的村庄中如果有基站,第 \(i\) 个村庄就不用被赔偿。
用个指针移一移,\(O(n)\) 扫一遍或者二分查找就可以处理出所有的 \(st[i]\) 和 \(ed[i]\)。
由于 DP 的时候枚举的 \(j\) 就是离 \(i\) 最近的基站,所以对于一个村庄 \(k(k<i)\),如果 \(i>ed[k]\) 且 \(j<st[k]\),\(k\) 村庄就要被赔偿。
所以就可以通过线段树区间加在 DP 的时候动态维护 \(w\)。具体实现就是用个 vector 存对于每一个村庄 \(i\),\(ed[k]=i\) 的 \(k\)。这样的话枚举完 \(i\) 时,\(j<st[k]\) 的 \(cost(j,i)\) 就都需要加上 \(w[k]\),因为这些 \(j\) 不能覆盖到 \(k\),且以后枚举的 \(i\) 也不能覆盖到 \(k\)。所以直接线段树上区间加就好了。
因为线段树维护的是 \(f[j]+cost(j,i)\) 的最小值,所以转移就直接在线段树上查区间最小值就可以。
DP 的时候先枚举建了几个基站,在当前这个基站的 DP 转移之前,把线段树的初值设为上一个基站的 \(f[i]\) 就可以了。
#include <bits/stdc++.h>
#define ls (x<<1)
#define rs (x<<1|1)
#define mid ((l+r)>>1)
#define int long long
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=20005,K=105;
int n,k,d[N],c[N],s[N],w[N],f[N],ans;
int t[N<<2],tag[N<<2];
void update(int x) {t[x]=min(t[ls],t[rs]);}
void build(int x,int l,int r) {
tag[x]=0;
if(l==r) {
t[x]=f[l];
return;
}
build(ls,l,mid);
build(rs,mid+1,r);
update(x);
}
void pushup(int x,int v) {t[x]+=v,tag[x]+=v;}
void pushdown(int x) {
if(!tag[x]) return;
pushup(ls,tag[x]);
pushup(rs,tag[x]);
tag[x]=0;
}
void modify(int x,int l,int r,int L,int R,int v) {
if(L>R) return;
if(l==L&&r==R) {
pushup(x,v);
return;
}
pushdown(x);
if(R<=mid) modify(ls,l,mid,L,R,v);
else if(L>mid) modify(rs,mid+1,r,L,R,v);
else modify(ls,l,mid,L,mid,v),modify(rs,mid+1,r,mid+1,R,v);
update(x);
}
int query(int x,int l,int r,int L,int R) {
if(L>R) return 0;
if(l==L&&r==R) return t[x];
pushdown(x);
if(R<=mid) return query(ls,l,mid,L,R);
else if(L>mid) return query(rs,mid+1,r,L,R);
return min(query(ls,l,mid,L,mid),query(rs,mid+1,r,mid+1,R));
}
int st[N],ed[N];
vector<int> q[N];
signed main() {
n=read(),k=read();
for(int i=2;i<=n;++i) d[i]=read();
for(int i=1;i<=n;++i) c[i]=read();
for(int i=1;i<=n;++i) s[i]=read();
for(int i=1;i<=n;++i) w[i]=read(),ans+=w[i];
++n,++k;
d[n]=w[n]=1e18;
int tot=0;
for(int i=1;i<=n;++i) {
int l=1,r=i,res=1;
while(l<=r)
if(d[i]-d[mid]<=s[i]) res=mid,r=mid-1;
else l=mid+1;
st[i]=res;
l=i,r=n,res=n;
while(l<=r)
if(d[mid]-d[i]<=s[i]) res=mid,l=mid+1;
else r=mid-1;
ed[i]=res;
q[ed[i]].push_back(i);
}
for(int i=1;i<=n;++i) {
f[i]=c[i]+tot;
int len=q[i].size();
for(int _=0;_<len;++_) tot+=w[q[i][_]];
}
ans=min(ans,f[n]);
for(int i=2;i<=k;++i) {
build(1,1,n);
for(int j=1;j<=n;++j) {
f[j]=query(1,1,n,1,j-1)+c[j];
int len=q[j].size();
for(int _=0;_<len;++_)
modify(1,1,n,1,st[q[j][_]]-1,w[q[j][_]]);
}
ans=min(ans,f[n]);
}
cout<<ans;
return 0;
}
单调队列优化 DP
单调队列优化 DP 通常用来优化那些转移方程形如 \(f[i]=\min_{l\le j\le r}\{a[i]+b[j]\}\) 或者 \(f[i]=\max_{l\le j\le r}\{a[i]+b[j]\}\) 的 DP,其中 \(a[i]\) 是只与 \(i\) 有关的一个项, \(b[j]\) 是只与 \(j\) 有关的一个项;\(l\) 和 \(r\) 都随着 \(i\) 增大而单调不减或单调不增。
这样的话就可以用单调队列维护 \(j\) 和其对应的 \(b[j]\),从而维护最优决策点。
单调队列中下标 \(j\) 单调递增或递减,\(b[j]\) 单调递劣(如果题目是求最小值就单调递增,求最大值就单调递减)。
核心思想就是单调队列:“如果有人比你小还比你强,你就没用了”。
具体实现就是:枚举到 \(i\) 时,不断弹出队头直到队头元素的下标直到队头元素的下标合法,此时从队头元素转移过来一定最优。转移后把队尾中比 \(i\) 劣的元素都弹出,再把 \(i\) 加入队尾。
因为每个元素都至多被加入和弹出一次,所以时间复杂度为 \(O(n)\)。
洛谷 P2627 Mowing the Lawn G
题目描述
有一个长度为 \(n\) 的序列 \(a[i]\),我们要从中选出一些元素,要求不能连续选中 \(k\) 个元素。选中一个元素 \(i\) 就可以得到 \(a[i]\) 的贡献,一个方案的贡献就是选中的所有元素的贡献的和。问所有可行方案中最大的贡献。
\(1\le n,k\le 10^5\)
Solution
非常裸的单调队列优化 DP。
显然相邻的两个选中的元素之间最多会由一个不选的元素隔开,否则就可以把中间的选了,这样一定更优。所以就是要将原序列划分为若干个区间,每个区间的长度最多为 \(k\),相邻的两个区间间隔一个元素。
设 \(f[i]\) 表示已经考虑完了前 \(i\) 个元素,且第 \(i\) 个必选的最大贡献。答案就是 \(\max(f[i])\)。
朴素转移:枚举上一个区间的末尾,这样的话当前区间的长度和左端点都已知,在枚举的过程中保证当前区间长度合法。
形式化的,设 \(sum[i]\) 表示 \(a[i]\) 的前缀和。\(f[i]=\max_{i-k-1\le j\le i-2}\{f[j]+sum[i]-sum[j+1]\}\)。
因为 \(i-k-1\) 和 \(i-2\) 都单调递增且 \((f[j]-sum[j+1])\) 这一项只于 \(j\) 有关,所以考虑单调队列优化。
单调队列中维护 \(j\) 单调递增,\(f[j]-sum[j+1]\) 单调递减即可。具体实现上面已经讲过了。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=100005;
int n,k,sum[N],dp[N],ans,q[N],l=1,r=1;
signed main() {
n=read(),k=read();
for(int i=1;i<=n;++i) sum[i]=read()+sum[i-1];
for(int i=1;i<=n;++i) {
while(l<r&&i-q[l]-1>k) ++l;
if(i<=k) dp[i]=sum[i];
else dp[i]=dp[q[l]]+sum[i]-sum[q[l]+1];
ans=max(ans,dp[i]);
while(l<r&&dp[i]-sum[i+1]>dp[q[r]]-sum[q[r]+1]) --r;
q[++r]=i;
}
cout<<ans;
return 0;
}
CF939F Cutlet
题目描述
有 \(2\times n\) 的时间去煎一块两面的肉。给定 \(k\) 个不相交的时间段 \([l_i,r_i]\),可以在这些区间的时间内任意次翻转这块肉。问是否存在合法的方案使得两面恰好都只煎了 \(n\) 分钟。如果有,求最小翻转次数。
\(1\le n\le 10^5,1\le k \le 100\)
Solution
因为只有那 \(k\) 个区间是有用的,而且 \(O(nk)\) 能过,所以设 \(f[i][j]\) 表示已经经过了前 \(i\) 个可以翻转的区间,背面已经煎了 \(j\) 秒(当前在煎的区间是正面,另一面是背面)。设背面的时间是因为方便转移,而且这样的话答案就是 \(f[k][n]\)。
同一个区间内最多翻转两次。因为我们只关心两个事情:两面各煎了多久和进这个区间时与出这个区间时相比有没有翻面,所以翻一次和翻两次就能包含所有情况。
在一个区间内有三种情况:
不翻转:\(f[i][j]=f[i-1][j]\)。因为一直在煎正面,所以背面的时间不变。
翻一次:\(f[i][j]=\min_{0\le k\le r[i]-l[i]}\{f[i-1][r[i]-j-k]\}+1\)。枚举的 \(k\) 是翻转后煎的时间。因为翻转了一次,上个区间的背面就是当前区间的正面。当前的总时间减去当前背面再减去当前区间新煎的正面的时间就是上个区间的背面的时间。
翻两次:\(f[i][j]=\min_{0\le k \le r[i]-l[i]}\{f[i-1][j-k]\}+2\)。枚举的 \(k\) 是两次翻转之间煎的时间。
发现 \(f[i][j]\) 只会从 \(f[i-1][k]\) 转移过来(此时 \(k\) 没有意义,只是单纯作为一个变量),所以可以滚动数组。
考虑用单调队列优化翻一次和翻两次的转移,对于两种状态分别维护不同的单调队列。
翻一次:因为 \(0\le k\le r[i]-l[i]\),所以 \(l[i]-j \le r[i]-j-k\le r[i]-j\)。\(l[i]-j\) 和 \(r[i]-j\) 都随 \(j\) 的增大而单调递减。所以在单调队列中维护 \(j\) 下标递减,\(f[i-1][j]\) 单调递增。
翻两次:因为 \(0\le k\le r[i]-l[i]\),所以 \(j+l[i]-r[i] \le j-k\le j\)。\(j+l[i]-r[i]\) 和 \(j\) 都随 \(j\) 的增大而单调递增。所以在单调队列中维护 \(j\) 下标递增,\(f[i-1][j]\) 单调递增。
#include <bits/stdc++.h>
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=100005,K=105;
int n,k,l[K],r[K],l1,r1,l2,r2,q1[N*2],q2[N*2],f[2][N*2],inf;
signed main() {
n=read(),k=read();
for(int i=1;i<=k;++i) l[i]=read(),r[i]=read();
memset(f,0x3f,sizeof f),inf=f[0][0];
f[0][0]=0;
int now=0,lst=1;
for(int i=1;i<=k;++i) {
now^=1,lst^=1;
l1=l2=r2=1,r1=0;
for(int j=r[i];j>=l[i];--j) {
while(l1<=r1&&f[lst][j]<f[lst][q1[r1]]) --r1;
q1[++r1]=j;
}
for(int j=0;j<=r[i];++j) {
f[now][j]=f[lst][j];
while(l1<r1&&q1[l1]>r[i]-j) ++l1;
f[now][j]=min(f[now][j],f[lst][q1[l1]]+1);
if(j!=r[i]&&l[i]-j-1>=0) {
while(l1<=r1&&f[lst][l[i]-j-1]<f[lst][q1[r1]]) --r1;
q1[++r1]=l[i]-j-1;
}
while(l2<r2&&q2[l2]<j-r[i]+l[i]) ++l2;
f[now][j]=min(f[now][j],f[lst][q2[l2]]+2);
if(j!=r[i]) {
while(l2<=r2&&f[lst][j+1]<f[lst][q2[r2]]) --r2;
q2[++r2]=j+1;
}
}
}
if(f[now][n]>=inf) puts("Hungry");
else printf("Full\n%d",f[now][n]);
return 0;
}
洛谷 P6563 [SBCOI2020] 一直在你身旁
题目描述
有一根电线坏了,它的长度可能是 \(1\) 到 \(n\) 中的任意一个整数。你可以花 \(a_i\) 的钱购买长度为 \(i\) 的一根电线。购买之后你可以知道那根坏掉的电线长度是否大于 \(i\)。问最坏情况下最少需要多少钱才能确定坏的电线的长度。
保证 \(a_1\le a_2\le\cdots\le a_n\)。
\(1\le n \le 7100\)
Solution
设 \(f[i][j]\) 表示已经确定答案在 \([i,j]\) 这个区间后需要的最少代价,转移:
因为买了 \(k\) 就能确定电线长度是在 \([i,k]\) 还是 \([k+1,j]\)。因为是最坏情况所以取 \(\max\),因为求最少所以取 \(\min\)。最后的答案就是 \(f[1][n]\)。
这个 \(\max\) 看着很烦,所以根据那两个东西哪个更大分类讨论。
很明显 \(f[i][k]\) 随着 \(k\) 的增大而增大,\(f[k+1][j]\) 随着 \(k\) 的增大而减小。所以可以找到一个临界点 \(p\),使得 \(f[i][k]\le f[k+1][j](k < p),f[i][k]>f[k+1][j](k\ge p)\)。显然,确定 \(j\) 的情况下,\(p\) 随 \(i\) 的减小而单调递减。所以不需要花额外的时间复杂度来计算 \(p\)。
对于 \(k\ge p\) 的情况,\(f[i][j]=\min_{p\le k<j}\{f[i][k]+a[k]\}\)。因为 \(f[i][k]\) 和 \(a[k]\) 都单调递增,所以 \(k\) 直接取 \(p\) 一定最小。
对于 \(k<p\) 的情况,\(f[i][j]=\min_{i\le k<p}\{f[k+1][j]+a[k]\}\)。如果 DP 的时候先从小到大枚举 \(j\) 再从大到小枚举 \(i\),\(i\) 与 \(p\) 就都单调递减,所以就可以单调队列优化。
为了卡常,代码里的 \(f[i][j]\) 的 \(i\) 和 \(j\) 是反过来的。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=7105;
int t,n,a[N],f[N][N],q[N],l,r,k;
signed main() {
t=read();
while(t--) {
n=read();
for(int i=1;i<=n;++i) a[i]=read();
for(int j=2;j<=n;++j) {
q[l=r=1]=k=j;
f[j][j-1]=a[j-1];
for(int i=j-2;i>=1;--i) {
while(k>i&&f[k-1][i]>f[j][k]) --k;
f[j][i]=f[k][i]+a[k];
while(l<=r&&q[l]>=k) ++l;
if(l<=r) f[j][i]=min(f[j][i],f[j][q[l]+1]+a[q[l]]);
while(l<=r&&f[j][i+1]+a[i]<=f[j][q[r]+1]+a[q[r]]) --r;
q[++r]=i;
}
}
printf("%lld\n",f[n][1]);
}
return 0;
}
斜率优化 DP
当出现形如 \(f[i]=\min\{f[j]+a[i]\times b[j]\}+c[i]\) 的转移时,就不能用单调队列优化了,因为 \((a[i]\times b[j])\) 这一项既有与 \(i\) 有关的,又有与 \(j\) 有关的。当 \(a[i]\) ,也就是 \(i\) 和 \(j\) 都有的那一项中与 \(i\) 有关的那一部分,如果它具有单调性,就可以考虑斜率优化。
具体实现结合例题讲解。
洛谷 U216276 黄老大我们的黄大阳
题目描述
黄老大我们的黄大阳
黄さんのために呼吸を捧げます
有连续的 \(n\) 场比赛等着黄老大 AK,每场比赛都有两个参数 \(a_i\) 和 \(b_i\) 分别表示第 \(i\) 场比赛的时长和难度,保证 \(a_{i-1}\le a_i\),\(b_i\le b_{i-1}\)。黄老大每次可以选择连续的一些比赛来 AK,黄老大耗费的精力就是他选择的比赛中最大的时长乘最大的难度。
现在黄老大决定要 AK 所有比赛。
黄老大当然知道如何划分每次选择的区间会用最少的精力,但他想考考你最少需要花费的精力是多少。
\(1\le n \le10^6\),\(1\le a_i,b_i\le 10^6\)。
Solution
朴素 \(O(n^2)\) DP 很简单。\(f[i]\) 表示 AK 前 \(i\) 场比赛需要的最少精力。\(f[i]=\min_{0\le j<i}\{f[j]+a[i]\times b[j+1]\}\)。答案就为 \(f[n]\) 。
考虑一次函数的斜截式 \(y=kx+b\),将其移项得到 \(b=y-kx\) 。我们将与 \(j\) 有关的信息表示为 \(y\) 的形式,把同时与 \(i,j\) 有关的信息表示为 \(kx\),把要最小化的信息(与 \(i\) 有关的信息)表示为 \(b\),也就是截距。具体地,设
则转移方程就写作 \(b_i=\min_{j<i}\{y_j-k_ix_j\}\)。我们把 \((x_j,y_j)\) 看作二维平面上的点,则 \(k_i\) 表示直线斜率,\(b_i\) 表示一条过 \((x_j,y_j)\) 的斜率为 \(k_i\) 的直线的截距。问题转化为了,选择合适的 \(j\)(\(1\le j<i\)),最小化直线的截距。
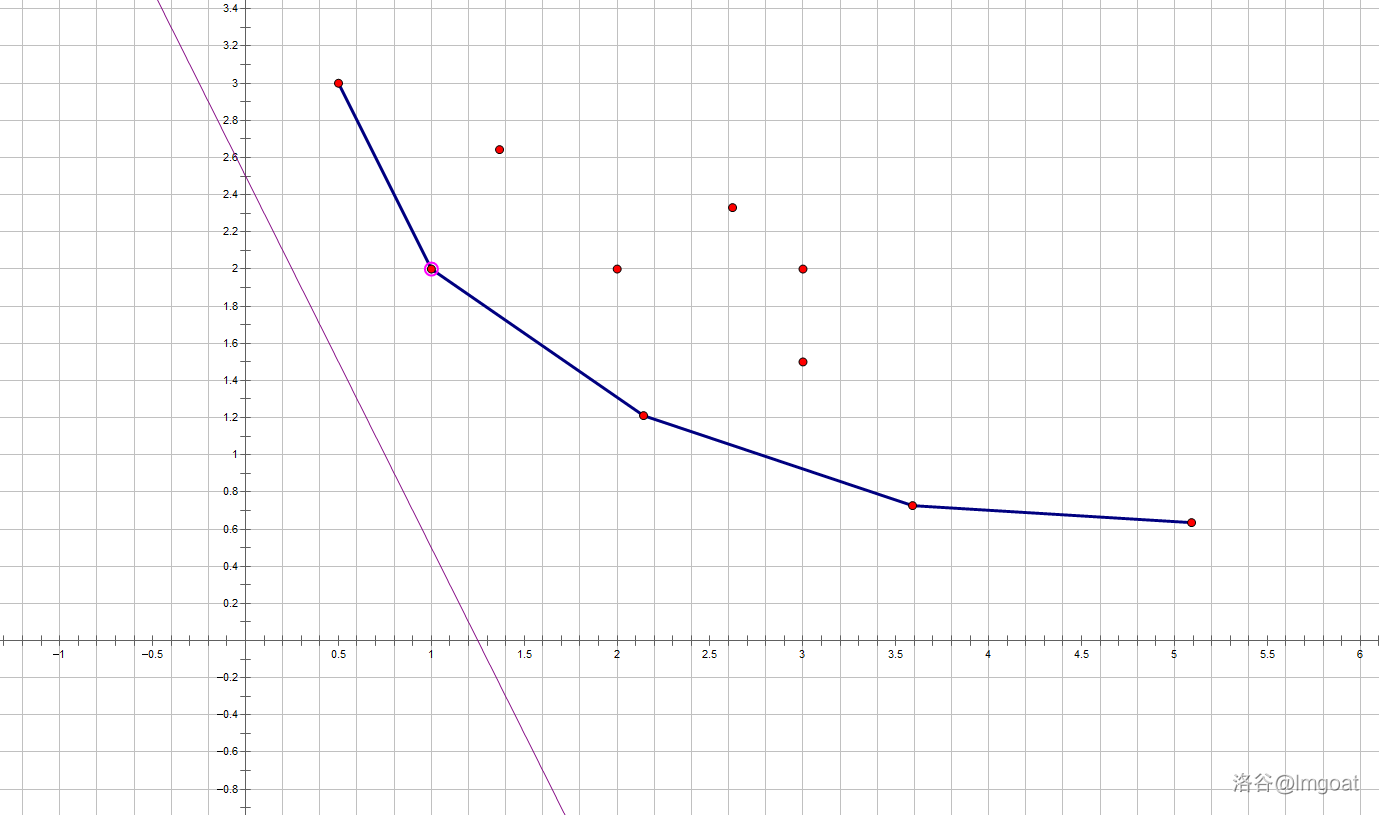
如图,我们将这个斜率为 \(k_i\) 的直线从下往上平移,直到有一个点 \((x_p,y_p)\) 在这条直线上,则有 \(b_i=y_p-k_ix_p\),这时 \(b_i\) 取到最小值。算完 \(f[i]\),我们就把 \((x_i,y_i)\) 这个点加入点集中,以做为新的 DP 决策。那么,我们该如何维护点集?
容易发现,可能让 \(b_i\) 取到最小值的点一定在下凸壳上。因此在寻找 \(p\) 的时候我们不需要枚举所有 \(i-1\) 个点,只需要考虑凸包上的点。而在本题中 \(k_i\) 随 \(i\) 的增加而递减,因此我们可以单调队列维护凸包。
具体地,设 \(K(a,b)\) 表示过 \((x_a,y_b)\) 和 \(x_b,y_b\) 的直线的斜率。考虑队列 \(q_l,q_{l+1},\ldots,q_r\),维护的是下凸壳上的点。也就是说,对于 \(l<i<r\),始终有 \(K(q_{i-1},q_i)>K(q_i,q_{i+1})\) 成立。
我们维护一个指针 \(e\) 来计算 \(b_i\) 最小值。我们需要找到一个 \(K(q_{e-1},q_e)\ge k_i>K(q_e,q_{e+1})\) 的 \(e\)(特别地,当 \(e=l\) 或者 \(e=r\) 时要特别判断),这时就有 \(p=q_e\),即 \(q_e\) 是 \(i\) 的最优决策点。由于 \(k_i\) 是单调递减的,因此 \(e\) 的移动次数是总共 \(O(n)\) 的。
在插入一个点 \((x_i,y_i)\) 时,我们要判断是否 \(K(q_{r-1},q_r)<K(q_{r-1},i)\),如果不等式不成立就将 \(q_r\) 弹出,直到等式满足。然后将 \(i\) 插入到 \(q\) 队尾。
这样我们就将 DP 的复杂度优化到了 \(O(n)\)。
参考代码:
#include <bits/stdc++.h>
#define int long long
#define double long double
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=1000005;
int n,a[N],b[N],f[N],q[N],l=1,r=1;
double X(int i) {return (double)b[i+1];}
double Y(int i) {return (double)f[i];}
double slope(int i,int j) {
double xi=X(i),xj=X(j);
if(xi==xj) return -1e9;
return (Y(i)-Y(j))/(xi-xj);
}
signed main() {
n=read();
for(int i=1;i<=n;++i) a[i]=read();
for(int i=1;i<=n;++i) b[i]=read();
for(int i=1;i<=n;++i) {
while(l<r&&slope(q[l],q[l+1])>(double)-1.0*a[i]) ++l;
f[i]=f[q[l]]+a[i]*b[q[l]+1];
while(l<r&&slope(q[r-1],q[r])<slope(q[r-1],i)) --r;
q[++r]=i;
}
cout<<f[n];
return 0;
}
洛谷 P2120 仓库建设
题目描述
有 \(n\) 个工厂,每个工厂有三个参数。\(x_i\),\(p_i\),\(c_i\) 分别表示第 \(i\) 个工厂距离第 \(1\) 个工厂的距离,现有产品数量,在第 \(i\) 个工厂建立仓库的费用。现在要在一些工厂建立仓库。每个没有建立仓库的工厂都要把其现有的产品运往编号比它大的离它最近的仓库。一个产品运送一个单位距离的费用是 \(1\)。问最小总费用(建仓库费用和运输费用的和)。
\(1\le n\le10^6\)
Solution
设 \(f[i]\) 表示第 \(i\) 个工厂必建,前 \(i\) 个工厂的最小花费。
枚举上一个仓库的位置就可以转移,我们只需要管中间这一部分的工厂的产品,这一部分的产品会运到第 \(i\) 个工厂。
设 \(sum[i]=\sum_{j=1}^ip[j]\) ,即 \(p[i]\) 的前缀和;\(px[i]=\sum_{j=1}^ip[j]\cdot x[j]\),即 \(p[i]\cdot x[i]\) 的前缀和。则状态转移方程可变形为:
用 \(O(n)\) 的时间可以预处理出 \(sum[i]\) 和 \(px[i]\)。
观察到状态转移方程中只有 \((-sum[j]\cdot x[i])\) 这一项是与 \(i\) 和 \(j\) 都有关的,且 \(x[i]\) 单调递增,所以考虑斜率优化。
设:\(x_j=sum[j]\),\(y_j=f[j]+px[j]\),\(k_i=x[i]\),\(b_i=f[i]-c[i]-px[i-1]\)。
剩下的部分就跟模板几乎一样了。因为是求最小值,所以要维护一个下凸壳,凸壳中的点的连线斜率递增。因为 \(k\) 递增,每次让队头斜率小于 \(k\) 的出队。加入的时候先踢出斜率比要加入的更大的,以保证下凸壳中斜率递增。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=1000005;
int n,x[N],p[N],c[N],f[N],sum[N],px[N],l=1,r=1,q[N],ans=1e18;
double X(int i) {return sum[i];}
double Y(int i) {return f[i]+px[i];}
double slope(int i,int j) {
double xi=X(i),xj=X(j);
if(xi==xj) return 1e18;
return (Y(i)-Y(j))/(xi-xj);
}
signed main() {
n=read();
for(int i=1;i<=n;++i) x[i]=read(),p[i]=read(),c[i]=read();
for(int i=1;i<=n;++i) sum[i]=sum[i-1]+p[i],px[i]=px[i-1]+p[i]*x[i];
for(int i=1;i<=n;++i) {
while(l<r&&slope(q[l],q[l+1])<(double)x[i]) ++l;
f[i]=c[i]+f[q[l]]+sum[i-1]*x[i]-sum[q[l]]*x[i]-px[i-1]+px[q[l]];
while(l<r&&slope(q[r-1],i)<slope(q[r-1],q[r])) --r;
q[++r]=i;
}
cout<<ans;
return 0;
}
斜率不单调的斜率优化 DP
因为横坐标依然具有单调性,所以还是可以用单调队列维护凸壳。因为凸壳中斜率具有单调性,所以对于每个斜率可以在单调队列中二分出斜率最接近它的,从而找到最优决策点。
洛谷 P5785 [SDOI2012]任务安排
题目描述
机器上有 \(n\) 个需要处理的任务,它们构成了一个序列。这些任务被标号为 \(1\) 到 \(n\),因此序列的排列为 \(1,2,3\cdots n\)。这 \(n\) 个任务被分成若干批,每批包含相邻的若干任务。从时刻 \(0\) 开始,这些任务被分批加工,第 \(i\) 个任务单独完成所需的时间是 \(t_i\)(\(t_i\) 可能为负数)。在每批任务开始前,机器需要启动时间 \(s\),而完成这批任务所需的时间是各个任务需要时间的总和。
注意,同一批任务将在同一时刻完成。每个任务的费用是它的完成时刻乘以一个费用系数 \(c_i\)。
请确定一个分组方案,使得总费用最小,求最小的总费用。
\(1\le n\le3\times 10^5,|t_i|\le 2^8\)
Solution
设 \(f[i]\) 表示前 \(i\) 个任务都被完成,所需的费用的最小值。显然:
\(time\) 是这批任务的完成时间。形式化地,\(time=\sum_{k=1}^{i}{t[k]}+cnt\cdot s\),\(cnt\) 是已经分了的组数。
看上去为了维护组数需要给 DP 再加一维,但我们可以提前算以后的费用。注意到每在 \(j+1\) 到 \(i\) 之间分一组,对于之后所有的 \(k\),其计算时的时间都要加上 \(s\),费用会加上 \(s\cdot c[k]\),总费用就会加上 \(s\cdot\sum_{k=j+1}^{n}{c[k]}\)。
设 \(st[i]\) 为 \(t[i]\) 的前缀和,\(sc[i]\) 为 \(c[i]\) 的前缀和。转移方程就变成:
发现 \((-st[i]\cdot sc[j])\) 既有 \(i\) 又有 \(j\) 所以考虑斜率优化。
设 \(x_j=sc[j],y_j=f[j]-s\cdot sc[j],k_i=st[i],b_i=f[i]-st[i]\cdot sc[i]-s\cdot sc[n]\)。因为 \(t[i]\) 可能为负数,所以 \(k_i\) 不具有单调性;又因为 \(x_j\) 有单调性,所以可以用单调队列维护下凸壳,在单调队列上二分最接近 \(k_i\) 的斜率,找到最有决策点。时间复杂度 \(O(n\log n)\)。
#include <bits/stdc++.h>
#define int long long
#define double long double
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=300005;
int n,s,t[N],c[N],f[N],cnt=1,q[N];
double X(int i) {return (double)c[i];}
double Y(int i) {return (double)f[i]-s*c[i];}
double slope(int i,int j) {
double xi=X(i),xj=X(j);
if(xi==xj) return 1e18;
return (Y(i)-Y(j))/(xi-xj);
}
int binary(double k) {
int l=1,r=cnt-1,mid,res=-1;
while(l<=r) {
mid=(l+r)>>1;
if(slope(q[mid],q[mid+1])>=k) r=mid-1,res=q[mid];
else l=mid+1;
}
if(res==-1) return q[cnt];
return res;
}
signed main() {
n=read(),s=read();
for(int i=1;i<=n;++i) t[i]=read()+t[i-1],c[i]=read()+c[i-1];
for(int i=1;i<=n;++i) {
int j=binary((double)t[i]);
f[i]=f[j]+t[i]*(c[i]-c[j])+s*(c[n]-c[j]);
while(cnt>1&&slope(q[cnt-1],i)<=slope(q[cnt-1],q[cnt])) --cnt;
q[++cnt]=i;
}
cout<<f[n];
return 0;
}
斜率和横坐标均不单调的斜率优化 DP
以上提到的斜率优化都有两个特点:斜率具有单调性、横坐标也有单调性,这样才能用单调队列。
如果斜率不具有单调性和横坐标不具有单调性,就需要用平衡树或者 CDQ 分治来维护凸壳。
用平衡树的话思路就很简单,但是实现比较繁琐。寻找决策点的时候直接在平衡树上二分,找到斜率最接近的。插入点的时候根据其横坐标在平衡树上找到其位置,加入这个节点,删除左右不满足凸壳性质的点;也有可能这个节点加入后不满足凸壳性质,那就不加入。时间复杂度 \(O(n\log n)\)。
CDQ 分治要好实现一些。对于一个区间 \([l,r]\),先把 \([l,mid]\) 的加入凸壳;再用凸壳内的点去更新 \([mid+1,r]\) 的 \(f[i]\),具体实现可以二分斜率也可以先按斜率排序然后单调队列。递归处理即可考虑到所有情况。时间复杂度 \(O(n\log^2 n)\)。
因为这种题比较少,且 DP 的思想跟斜率和横坐标都单调的斜率优化 DP 也是一样的,所以就不放例题了。
长链剖分优化 DP
长链剖分是树链剖分的一种。类比重链剖分中重儿子是子树大小最大的儿子,长链剖分中的重儿子是子树深度最大的儿子。
一般情况下可以使用长链剖分来优化的树形 DP 会有一维状态为深度。
具体操作与实现结合例题讲解。
CF1009F Dominant Indices
题目描述
给定一棵以 \(1\) 为根,\(n\) 个节点的树。设 \(d(u,x)\) 为 \(u\) 子树中到 \(u\) 距离为 \(x\) 的节点数。
对于每个点,求一个最小的 \(k\),使得 \(d(u,k)\) 最大。
\(1\le n\le 10^6\)
Solution
设 \(f[u][x]\) 表示第 \(u\) 个节点的子树内与 \(u\) 的距离为 \(x\) 的点的个数。
显然:\(f[u][x]=\sum_{v\in son_u}{f[v][x-1]}\),因为从儿子到父亲距离加了一。
考虑长链剖分优化。
设 \(dep[u]\) 表示 \(u\) 子树内深度最大的叶子节点到 \(u\) 的简单路径上的点的个数。如果 \(u\) 是某一条长链的顶端节点,那么 \(dep[u]\) 就是这条长链的节点个数。
设 \(son[u]\) 表示 \(u\) 的重儿子的编号。那么 \(son[u]\) 就是 \(u\) 的儿子 \(v\) 中 \(dep[v]\) 最大的那个,且 \(dep[u]=dep[son[u]]+1\)。
一次 DFS 即可求出 \(dep[u]\) 和 \(son[u]\)。这样就成功对原树进行了长链剖分。
优化 DP:对于点一个点,继承重儿子的 \(f\) 数组,再从轻儿子枚举距离暴力转移。
在不管轻儿子的情况下,\(f[u][x]=f[son[u]][x-1]\),就相当于把重儿子的 \(f\) 数组全部向右移了一位。这个操作可以通过指针实现,同一个长链里的状态共用一段空间。
具体地,每次将重儿子的指针起点设为当前节点的指针起点加一,然后 DFS 过去。对于轻儿子,每个轻儿子都是其所在长链的顶端节点,所以要为轻儿子分配一段长度为其 \(dep\) 的空间,再 DFS 过去,回溯时暴力转移。
因为每次指针操作是 \(O(1)\) 的,所以只考虑此操作,总时间复杂度是 \(O(n)\)。
对于从轻儿子 \(v\) 枚举距离暴力转移,每次枚举的次数是 \(dep[v]\),因为 \(dep[v]\) 是最大距离。又因为 \(dep[v]\) 也是 \(v\) 所在长链的节点数量,而除根节点外每个长链的顶端节点都只会被枚举一次,所以枚举总数是 \(n\) 减去根节点所在长链的节点个数,总时间复杂度也是 \(O(n)\)。
所以整个算法的时间复杂度为 \(O(n)\)。
因为对于每条长链分配的数组长度是其长链上点的个数,而所有长链的链长的和就是 \(n\),所以空间复杂度也是 \(O(n)\)。
大家对指针操作可能不是很熟 ,应该只有我。具体看代码。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=1000005;
int n,hed[N],nxt[N<<1],to[N<<1],cur,ans[N],orz[N],dep[N],son[N];
int *f[N],*now=orz;
void add(int x,int y) {to[++cur]=y,nxt[cur]=hed[x],hed[x]=cur;}
void dfs1(int x,int fa) {
for(int i=hed[x],y;i;i=nxt[i]) {
y=to[i];
if(y==fa) continue;
dfs1(y,x);
if(dep[y]>dep[son[x]]) son[x]=y;
}
dep[x]=dep[son[x]]+1;
}
void dfs2(int x,int fa) {
f[x][0]=1;
if(son[x]) {
f[son[x]]=f[x]+1;
dfs2(son[x],x);
ans[x]=ans[son[x]]+1;
}
for(int i=hed[x],y;i;i=nxt[i]) {
y=to[i];
if(y==fa||y==son[x]) continue;
f[y]=now,now+=dep[y];
dfs2(y,x);
for(int j=1;j<=dep[y];++j) {
f[x][j]+=f[y][j-1];
if(f[x][j]>f[x][ans[x]]||(f[x][j]==f[x][ans[x]]&&j<ans[x])) ans[x]=j;
}
}
if(f[x][ans[x]]==1) ans[x]=0;
}
signed main() {
n=read();
for(int i=1;i<n;++i) {
int x=read(),y=read();
add(x,y),add(y,x);
}
dfs1(1,0);
f[1]=now,now+=dep[1];
dfs2(1,0);
for(int i=1;i<=n;++i) printf("%lld\n",ans[i]);
return 0;
}
洛谷 P5904 [POI2014]HOT-Hotels 加强版
题目描述
给定一棵有 \(n\) 个节点的树,求有多少组点 \((i,j,k)\) 满足 \(i,j,k\) 两两之间距离相等。
\(1\le n\le 10^5\)
Solution
设 \(LCA(x,y)\) 表示 \(x\) 与 \(y\) 的最近公共祖先,\(dis(x,y)\) 表示 \(x\) 到 \(y\) 的树上唯一简单路径的距离。
以 \(1\) 为根,设 \((i,j,k)\) 中 \(j\) 的深度等于 \(k\) 的深度。
可以把满足条件的三元组分为两类。
第一种情况 \(j\) 和 \(k\) 都在 \(i\) 的子树内,也就是 \(i\) 是 \(LCA(j,k)\) 的祖先,这样的话就要求 \(dis(i,LCA(j,k))=dis(j,LCA(j,k))=dis(k,LCA(j,k))\)。
第二种情况 \(j\) 和 \(k\) 都不在 \(i\) 的子树内,显然这种情况要求满足 \(dis(j,LCA(j,k))=dis(k,LCA(j,k))=dis(i,LCA(i,j))+dis(LCA(i,j),LCA(j,k))\)。
所以设 \(f[i][j]\) 表示 \(i\) 的子树中与 \(i\) 的距离为 \(j\) 的点的个数,\(g[i][j]\) 表示 \(x,y\) 在 \(i\) 的子树中,且满足 \(dis(x,LCA(x,y))=dis(y,LCA(x,y))=dis(i,LCA(x,y))+j\) 的数对 \((x,y)\) 的个数。可得:
考虑 \(f\) 和 \(g\) 的转移。
\(f\) 的转移就和上一道题一样,\(f[i][j]=\sum_{x\in son(i)}{f[x][j-1]}\)。
\(g\) 的转移有两种转移,在同一个儿子的子树内,在不同儿子的子树内。
在算两个不同儿子的贡献时用前缀和的思想优化一下,就是 \(O(n^2)\) 的。
发现 \(f\) 和 \(g\) 的第二维都与深度有关,也可以对于重儿子把下标平移之后直接继承,对于轻儿子暴力转移。满足这个性质就可以长链剖分优化。就可以做到 \(O(n)\)。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=1000005;
int n,hed[N],nxt[N<<1],to[N<<1],cur,ans,orz[N<<2],dep[N],son[N];
int *f[N],*g[N],*now=orz;
void add(int x,int y) {to[++cur]=y,nxt[cur]=hed[x],hed[x]=cur;}
void dfs1(int x,int fa) {
for(int i=hed[x],y;i;i=nxt[i]) {
y=to[i];
if(y==fa) continue;
dfs1(y,x);
if(dep[y]>dep[son[x]]) son[x]=y;
}
dep[x]=dep[son[x]]+1;
}
void dfs2(int x,int fa) {
if(son[x]) {
f[son[x]]=f[x]+1;
g[son[x]]=g[x]-1;
dfs2(son[x],x);
}
f[x][0]=1,ans+=g[x][0];
for(int i=hed[x],y;i;i=nxt[i]) {
y=to[i];
if(y==fa||y==son[x]) continue;
f[y]=now,now+=dep[y]<<1,g[y]=now,now+=dep[y]<<1;
dfs2(y,x);
for(int j=0;j<dep[y];++j) {
if(j) ans+=f[x][j-1]*g[y][j];
ans+=f[y][j]*g[x][j+1];
}
for(int j=0;j<dep[y];++j) {
g[x][j+1]+=f[x][j+1]*f[y][j];
f[x][j+1]+=f[y][j];
if(i) g[x][j-1]+=g[y][j];
}
}
}
signed main() {
n=read();
for(int i=1;i<n;++i) {
int x=read(),y=read();
add(x,y),add(y,x);
}
dfs1(1,0);
f[1]=now,now+=dep[1]<<1,g[1]=now,now+=dep[1]<<1;
dfs2(1,0);
cout<<ans;
return 0;
}
决策单调性优化 DP
设 \(w(x,y)\) 是定义在整数集合上的二元函数。若对于定义域上的任意整数 \(a,b,c,d\),设其中 \(a\le b\le c\le d\),都有 \(w(a,d)+w(b,c)\ge w(a,c)+w(b,d)\) 成立,则称函数 \(w\) 满足四边形不等式。
定理(四边形等式的另一种定义):
设 \(w(x,y)\) 是定义在整数集合上的二元函数。若对于定义域上的任意整数 \(a,b\),其中 \(a<b\),都有 \(w(a,b+1)+w(a+1,b)\ge w(a,b)+w(a+1,b+1)\) 成立,则函数 \(w\) 满足四边形不等式。
有了这个定理,要证 \(w(x,y)\) 满足四边形不等式就只需要证 \(w(a,b+1)+w(a+1,b)\ge w(a,b)+w(a+1,b+1)\)。但在具体的题目中,有很多题目的式子都非常复杂,需要用很复杂的数学方法证明;还有部分题目可以大力分类讨论证明。所以做题时推荐直接打表确定 \(w(x,y)\) 是否满足四边形不等式。
证明:
对于 \(a<c\),有 \(w(a,c+1)+w(a+1,c)\ge w(a,c)+w(a+1,c+1)\)。
对于 \(a+1<c\),有 \(w(a+1,c+1)+w(a+2,c)\ge w(a+1,c)+w(a+2,c+1)\)。
两式相加,得到 \(w(a,c+1)+w(a+2,c)\ge w(a,c)+w(a+2,c+1)\)。
依此类推,对任意的 \(a\le b\le c\),有 \(w(a,c+1)+w(b,c)\ge w(a,c) +w(b,c+1)\)。
同理,对任意的 \(a\le b \le c\le d\),有 \(w(a,d)+w(b,c)\ge w(a,c)+w(b,d)\)。
定理(决策单调性)
对于形如 \(f[i]=min_{0\le j<i}\{f[j]+val(j,i)\}\) 的状态转移方程,记 \(p[i]\) 为令 \(f[i]\) 取到最小值的 \(j\) 的值,即 \(p[i]\) 是 \(f[i]\) 的最优决策。若 \(p\) 在 \([1,n]\) 上单调不降,则称 \(f\) 具有决策单调性。
在状态转移方程 \(f[i]=min_{0\le j<i}\{f[j]+val(j,i)\}\) 中,若函数 \(val\) 满足四边形不等式,则 \(f\) 具有决策单调性。
证明:
\(\forall{i}\in[1,n],\forall{j}\in[0,p[i]-1]\),根据 \(p[i]\) 的最优性,有:
\(\forall{i'}\in[i+1,n]\),因为 \(val\) 满足四边形不等式,有:
移项得:
与第一个不等式相加,有:
这个不等式的含义为,以 \(p[i]\) 作为 \(f[i']\) 的决策,比以 \(j<p[i]\) 作为 \(f[i']\) 的决策更优。换言之,\(f[i']\) 的决策点不可能小于 \(p[i]\),即 \(p[i']\ge p[i]\)。所以 \(f\) 有决策单调性。
实现方法
通常有两种方法:单调队列和分治,以下结合例题讲解。
洛谷 P3515 [POI2011]Lightning Conductor
题目描述
给定一个长度为 \(n\) 的序列 \(\{a_n\}\),对于每个 \(i\in [1,n]\) ,求出一个最小的非负整数 \(p\) ,使得 \(\forall j\in[1,n]\),都有 \(a_j\le a_i+p-\sqrt{|i-j|}\)。
\(1 \le n \le 5\times 10^{5}\),\(0 \le a_i \le 10^{9}\) 。
Solution
要求所有 \(p_i\),将题目给的式子移项、变形得:
绝对值不好搞,直接拆开分开搞:
我们就只考虑前面这一部分,后面这一部分直接把序列反转之后就跟前面部分一样了,结果取两次的较大值。那式子就是:
此处的 \(w(j,i)\) 就是 \(\sqrt{i-j}\),可以证明其满足四边形不等式,所以这个转移方程具有决策单调性。
证明如下:
设 \(a<b\)。
\(w(a+1,b)+w(a,b+1)=\sqrt{b-a+1}+\sqrt{b-a-1}\)
\((w(a+1,b)+w(a,b+1))^2=2(b-a)+2\sqrt{(b-a)^2-1}\)
\(w(a,b)+w(a+1,b+1)=2\sqrt{b-a}\)
\(\begin{aligned}(w(a,b)+w(a+1,b+1))^2&=4(b-a)\\ &=2(b-a)+2\sqrt{(b-a)^2}\end{aligned}\)
\(\because\sqrt{(b-a)^2-1}<\sqrt{(b-a)^2}\)
\(\therefore (w(a+1,b)+w(a,b+1))^2<(w(a,b)+w(a+1,b+1))^2\)
\(\therefore w(a+1,b)+w(a,b+1)<w(a,b)+w(a+1,b+1)\)
\(\therefore w(a,d)+w(b,c)<w(a,c)+w(b,d)\,(a<b<c<d)\)
\(\therefore w\) 满足四边形不等式,即 \(p\) 满足决策单调性。
证毕。
上面的四边形不等式符号与最初提到的相反,因为之前的是求 \(\min\),这题是求 \(\max\)。
现在已知决策单调性,考虑如何利用此性质优化复杂度。
解法一
单调队列加二分。
对于每个 \(j\),把 \(a[j]+\sqrt{i-j}\) 看成关于 \(j\) 的函数 \(f_j\)。我们要做的就是要对于每个横坐标 \(i\),找到在此位置最大的 \(f_j(1\le j\le i)\)。
最简单的想法是只留最大的那一个。但因为这个函数的增速是递减的,所以可能存在一个 \(j\) 比较小的 \(f_j\) 在某一时刻被 \(j\) 比较大的函数反超。所以我们大概需要维护这样的若干个函数:
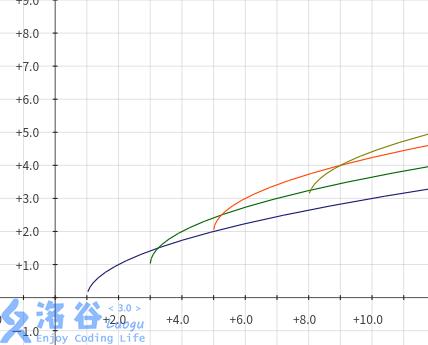
我们可以用单调队列维护这些函数,维护 \(j\) 和每两个函数之间的交点的横坐标递增。
设 \(k_{a,b},a<b\) 表示这两个函数大小关系变化的临界点的横坐标(如果两个函数没有交点,如果 \(f_a<f_b\),就设为一个较大值,否则设为一个较小值),\(h\) 表示单调队列队头,\(t\) 表示队尾。具体地,取最优队头时,不断弹出队头直到 \(k_{h,h+1}>i\),这些函数在现在和以后一定不优。加入到队尾时,不断弹出队尾直到不满足 \(k_{t-1,t}\ge k_{t,i}\),如果这个不等式满足就说明 \(f_t\) 这个函数已经没用了。
用二分算两个函数的临界点,因为设 \(i<j\),在 \(k_{i,j}\) 之前 \(f_i>f_j\),之后 \(f_i<f_j\)。
总时间复杂度 \(O(n\log n)\)。
#include <bits/stdc++.h>
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=500005;
int n,a[N],q[N],l,r,k[N];
double p[N],sq[N];
double calc(int i,int j) {return a[j]+sq[i-j];}
int getk(int i,int j) {
int l=j,r=n,mid,res=n+1;
while(l<=r) {
mid=(l+r)>>1;
if(calc(mid,i)<=calc(mid,j)) res=mid,r=mid-1;
else l=mid+1;
}
return res;
}
void DP() {
l=1,r=0;
for(int i=1;i<=n;++i) {
while(l<r&&k[r-1]>=getk(q[r],i)) --r;
k[r]=getk(q[r],i),q[++r]=i;
while(l<r&&k[l]<=i) ++l;
p[i]=max(p[i],calc(i,q[l]));
}
}
signed main() {
n=read();
for(int i=1;i<=n;++i) a[i]=read(),sq[i]=sqrt(i);
DP();
for(int i=1,j=n;i<j;++i,--j) swap(a[i],a[j]),swap(p[i],p[j]);
DP();
for(int i=n;i>=1;--i) printf("%d\n",(int)ceil(p[i])-a[i]);
return 0;
}
解法二
分治。
假设已知 \([l,r]\) 区间内的所有 \(p[i]\) 的最优决策点在 \([L,R]\) 这个区间内。
设 \(mid=\lfloor\frac{l+r}{2}\rfloor\),\(p[mid]\) 的最优决策点为 \(p\),根据决策单调性,\([l,mid-1]\) 的最优决策点在 \([L,p]\) 之内,\([mid+1,r]\) 的最优决策点在 \([p,R]\) 之内。
对于每个区间 \([l,r]\) 暴力枚举 \([L,R]\) 中的每个点找到 \(mid\) 的最优决策点 \(p\),递归下去即可。因为每次将一个区间分为两半,所以递归层数为 \(\log n\)。而每一层的所有区间的交集为空,并集为 \([1,n]\),所以处理一层的时间复杂度为 \(O(n)\)。所以总时间复杂度为 \(O(n\log n)\)。
#include <bits/stdc++.h>
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=500005;
int n,a[N];
double p[N],sq[N];
double calc(int i,int j) {return a[j]+sq[i-j];}
void solve(int l,int r,int L,int R) {
if(l>r) return;
int mid=(l+r)>>1,tmp=L;
double ma=0;
for(int j=L;j<=mid&&j<=R;++j)
if(calc(mid,j)>ma) ma=calc(mid,j),tmp=j;
p[mid]=max(p[mid],ma);
solve(l,mid-1,L,tmp),solve(mid+1,r,tmp,R);
}
signed main() {
n=read();
for(int i=1;i<=n;++i) a[i]=read(),sq[i]=sqrt(i);
solve(1,n,1,n);
for(int i=1,j=n;i<j;++i,--j) swap(a[i],a[j]),swap(p[i],p[j]);
solve(1,n,1,n);
for(int i=n;i>=1;--i) printf("%d\n",(int)ceil(p[i])-a[i]);
return 0;
}
容易发现以上提到的两种解法都有使用前提。
单调队列加二分要求必须能够快速(\(O(1)\))算出一个 \(f_j+w(j,i)\)。
对 \(f_i\) 求出的顺序没有要求就可以用分治。比如 \(f[i]=f[j]+w(j,i)\) 这种,必须先从小到大求出 \(f[i]\) 的就不能用分治。如果像 \(f[i][j]=f[i-1][k]+w(k,j)\) 这种分几次 DP,每次从上次的来转移的或者 \(f[i]\) 跟 \(f[j]\) 没有关系的就可以。看上去这种方法也要求每次 \(O(1)\) 算出 \(w(j,i)\),但对于某些情况,分治可以非常巧妙的解决单独计算 \(w(j,i)\) 为 \(O(n)\) 的问题,比如下面这道例题。
CF868F Yet Another Minimization Problem
题目描述
给定一个序列 \(a\),要把它分成 \(k\) 个子段。每个子段的费用是其中相同元素的对数。求所有子段的费用之和的最小值。
\(2 \leq n \leq 10^5\),\(2 \leq k \leq min(n,20)\),\(1 \leq a_i \leq n\) 。
Solution
设 \(f[i][j]\) 表示前 \(j\) 个数分成 \(i\) 段的最小费用。有转移: \(f[i][j]=\min_{0\le k<j}\{f[i-1][k]+w(k+1,j)\}\)。
可以证明 \(f[i][j]\) 有决策单调性。证明如下:
设 \(i<j\),\(t[i][j][k]\) 表示 \([j,k]\) 区间内等于 \(i\) 的 \(a\) 的个数。
\(w(i+1,j)+w(i,j+1)=2w(i,j)-t[a[i]][i+1][j]+t[a[j+1]][i][j]\)
\(w(i,j)+w(i+1,j+1)=2w(i,j)-t[a[i]][i+1][j]+t[a[j+1]][i+1][j]\)
\(\because t[a[j+1]][i][j]\ge t[a[j+1]][i+1][j]\)
\(\therefore w(i+1,j)+w(i,j+1)\ge w(i,j)+w(i+1,j+1)\)
\(\therefore w(b,c)+w(a,d)\ge w(a,b)+w(c,d)\,(a<b<c<d)\)
即 \(w(i,j)\) 满足四边形不等式
所以 \(f[i][j]\) 有决策单调性。
证毕。
现在问题就在于计算 \(w(i,j)\)。发现如果单独对于一个 \(w(i,j)\) 计算不太好优化,但是如果已知 \(w(i,j)\),要扩展到 \(w(i+1,j)\) 或者 \(w(i-1,j)\) 或者 \(w(i,j+1)\) 或者 \(w(i,j-1)\) 只需要维护桶就可以 \(O(1)\) 实现。
所以可以用类似于莫队的方法,维护全局指针 \(lc,rc\) 每次要计算一个区间 \([l,r]\) 就把指针一步一步移过去,在移的过程中维护 \(w(lc,rc)\) 与桶 \(t\) 数组。每次加入第 \(i\) 个数对答案的贡献就是 \(t[a[i]]\),删除第 \(i\) 个数答案就减少 \(t[a[i]]-1\)。加入或删除后再更新 \(t[a[i]]\) 的值即可。
所以现在需要使用一种算法,使得 \(lc,rc\) 的移动次数在可以接受的复杂度内。因为有决策单调性,所以考虑分治。分治的参数 \((l,r,L,R,k)\) 表示当前在 \([l,r]\) 区间,\(mid=\lfloor\frac{l+r}{2}\rfloor\),已经可以确定最优决策点在 \([L,R]\) 这个区间内,这轮 DP 是分的第 \(k\) 段。每次在 \([L,R]\) 这个区间中暴力枚举,求出 \(f[k][mid]\),与其最优决策点 \(p\)。然后递归到 \((l,mid-1,L,p)\) 和 \((mid+1,r,p,R)\)。
因为分治中 \(mid\) 的最优决策点 \(p\) 在递归的每一层单调不降,而且每次往下递归时 \(lc\) 往回走的部分在每一层的和也是 \(O(n)\),所以 \(lc\) 的移动次数是 \(O(n\log n)\) 的。
而 \(rc\) 在每个分治的区间内都是 \(mid\),同样在递归的每一层中单调不降。每次往下递归时 \(rc\) 往回走的部分在每一层的和也是 \(O(n)\) 的,所以 \(rc\) 的移动次数也是 \(O(n\log n)\) 的。
所以每次从 \([1,n]\) 开始分治的时间复杂度是 \(O(n\log n)\)。因为要做 \(k\) 次,所以总时间复杂度是 \(O(kn\log n)\)。
#include <bits/stdc++.h>
#define int long long
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const int N=100005,K=25,inf=LONG_LONG_MAX;
int a[N],f[K][N],t[N],lc=1,rc,res;
void add(int x) {res+=t[a[x]]++;}
void del(int x) {res-=--t[a[x]];}
int calc(int l,int r) {
while(lc>l) add(--lc);
while(rc<r) add(++rc);
while(lc<l) del(lc++);
while(rc>r) del(rc--);
return res;
}
void solve(int l,int r,int L,int R,int k) {
if(l>r) return;
int mi=inf,mid=(l+r)>>1,tmp=L;
for(int i=min(mid-1,R);i>=L;--i)
if(f[k-1][i]+calc(i+1,mid)<mi) mi=f[k-1][i]+calc(i+1,mid),tmp=i;
f[k][mid]=mi;
solve(l,mid-1,L,tmp,k);
solve(mid+1,r,tmp,R,k);
}
int n,k;
signed main() {
n=read(),k=read();
for(int i=1;i<=n;++i) a[i]=read();
solve(1,n,0,0,1);
for(int i=2;i<=k;++i) solve(1,n,0,n-1,i);
cout<<f[k][n];
return 0;
}
凸优化 DP
凸优化 DP 就是 wqs 二分(带权二分)优化 DP。用来解决的问题是:有 \(n\) 个物品,要选 \(m\) 个物品,要使权值最大。这类问题一般最暴力的方法就是给 DP 再加一维,但通过 wqs 二分可以给 DP 减一维,或者直接把 DP 变成贪心。具体结合例题讲解。
CF739E Gosha is hunting
题目描述
你要抓神奇宝贝!现在一共有 \(n\) 只神奇宝贝。你有 \(a\) 个『宝贝球』和 \(b\) 个『超级球』。『宝贝球』抓 \(i\) 只神奇宝贝的概率是 \(p_i\),『超级球』抓到的概率则是 \(q_i\)。不能往同一只神奇宝贝上使用超过一个同种的『球』,但是可以往同一只上既使用『宝贝球』又使用『超级球』(都抓到算一个)。请合理分配每个球抓谁,使得你抓到神奇宝贝的总个数期望最大,并输出这个值。
\(n \leq 2000\)。
Solution
为了方便,把神奇宝贝称为人,把宝贝球称为红球,超级球称为蓝球。
首先有暴力 \(O(n^3)\) DP:\(f[i][j][k]\) 表示前 \(i\) 个人用了 \(j\) 个红球和 \(k\) 个蓝球。
就是不用球、用红球、用蓝球、用两个球。
显然,当 \(i,j\) 固定时,关于 \(k\) 的函数 \(f[i][j][k]\) 单调递增,且增速递减,也就是上凸的。但是我们不能快速求出函数上的任意一点。
我们设原函数为 \(f(x)\),再引入一些直线与 \(f(x)\) 上的某些点相切,设 \(g(x)\) 为其截距,有 \(g(x)=f(x)-kx\)。因为 \(f(x)\) 是凸函数,对于一个斜率为 \(k\) 的一次函数要选一个与 \(f(x)\) 上的一个点 \(x\) 与之相切使得截距最大,肯定是选斜率最接近 \(k\) 的点。而上凸函数上斜率递减,所以最优的 \(x\) 随 \(k\) 递减而单调递增。
所以我们就可以二分斜率 \(k\),算出对于 \(k\) 最优的 \(g(x)\) 与其对应的 \(x\)。二分 \(k\) 时如果 \(x\) 比 \(b\) 大就将 \(k\) 增大,如果比 \(b\) 小就将斜率减小,刚好等于 \(b\) 的话说明这就是答案,根据 \(g(x)\) 算出 \(f(x)\) 就是答案。就是 wqs 二分。
现在问题就在于怎么对于 \(k\) 算出其最大的 \(g(x)\) 与其对应的 \(x\)。我们可以将 \(k\) 视作一个额外的权值,这样的话选 \(x\) 个就刚好会让算出来的答案等于真实答案减 \(kx\),就是之前提到的 \(g(x)=f(x)-kx\)。所以就可以 DP 求解:\(f[i][j]\) 表示前 \(i\) 个人用了 \(j\) 个红球的最大期望。
在 DP 的时候记录下使用蓝球的数量 \(cntb\),最后真实的答案就是 \(f[n][a]+k*cntb\)。所以上文提到的 “对于 \(k\) 的最优的 \(x\)” 就是 \(cntb\),二分的时候就是通过 DP 得到的 \(cntb\) 来调整 \(k\),直到 \(cntb=b\)。
这样的话就把时间复杂度降到了 \(O(n^2\log v)\),\(v\) 是二分实数产生的。足以通过此题。
但我们发现对于第二维 \(j\) 也可以一样的 wqs 二分,所以就直接 wqs 二分套 wqs 二分。DP在二分出红球和蓝球的斜率或者说权值后就直接变成了贪心。每次直接选贡献最大的即可。时间复杂度为 \(O(n\log^2 v)\)。
#include <bits/stdc++.h>
#define double long double
using namespace std;
int read() {
int x(0),f(0);
char ch=getchar();
while(!isdigit(ch)) f|=(ch=='-'),ch=getchar();
while(isdigit(ch)) x=x*10+ch-'0',ch=getchar();
return f?-x:x;
}
const double eps=1e-8;
const int N=2005;
int n,a,b,ta[N],tb[N],cnt1,cnt2;
double p[N],q[N],pq[N],tot,v1,v2,mid1,mid2;
void check() {
cnt1=cnt2=0,tot=0;
for(int i=1;i<=n;++i) {
bool flag1=0,flag2=0;
double tmp=0;
if(p[i]-mid1>tmp+eps) tmp=p[i]-mid1,flag1=1,flag2=0;
if(q[i]-mid2>tmp+eps) tmp=q[i]-mid2,flag1=0,flag2=1;
if(pq[i]-mid1-mid2>tmp+eps) tmp=pq[i]-mid1-mid2,flag1=flag2=1;
if(flag1) ++cnt1;
if(flag2) ++cnt2;
tot+=tmp;
}
}
signed main() {
n=read(),a=read(),b=read();
for(int i=1;i<=n;++i) cin>>p[i];
for(int i=1;i<=n;++i) cin>>q[i];
for(int i=1;i<=n;++i) pq[i]=1-(1-p[i])*(1-q[i]);
double l1=0,r1=1;
while(l1+eps<r1) {
mid1=(l1+r1)/2;
double l2=0,r2=1;
while(l2+eps<r2) {
mid2=(l2+r2)/2;
check();
v2=mid2;
if(cnt2==b) break;
if(cnt2>b) l2=mid2;
else r2=mid2;
}
v1=mid1;
if(cnt1==a) break;
if(cnt1>a) l1=mid1;
else r1=mid1;
}
cout<<tot+v1*a+v2*b;
return 0;
}

 浙公网安备 33010602011771号
浙公网安备 33010602011771号