MySQL Redo Log的设计
InnoDB正常关闭时,会把所有的脏页全都刷下去,同时做一次checkpoint,这样,redo log在逻辑上来说就是空的,下次启动不需要进行恢复。
每一个mtr都有自己预留的一个缓冲区,mtr产生的log会先被写到mtr内部的缓冲区,在mtr提交时,会做下面几件事:
- 计算该mtr所产生的所有log的字节大小。
- 把log写入到log buffer中相应的位置。
- 被该mtr修改的page会被标记为dirty,并被移动到flush链表。
- 释放mtr内部的缓冲区。
每向log buffer写入1byte的日志,current lsn就会+1。
log.write_lsn:由log writer线程更新。指向当前log buffer中还未被刷新到page cache的首位置。该lsn之前的空间可以被循环重新使用。
log.buf_ready_for_write_lsn:由log writer线程更新。该值之前的log buffer是连续没有空洞的。log.buf_ready_for_write_lsn >= log.write_lsn。
log.flushed_to_disk_lsn:由log flusher线程更新。已经被刷到磁盘的lsn。log.flushed_to_disk_lsn <= log.write_lsn。
log.sn:user线程在请求空间时更新。log.sn >= log_translate_lsn_to_sn(log.buf_ready_for_write_lsn)
log.buf_dirty_pages_added_up_to_lsn:该lsn之前的脏页都已经被挂载到flush链表上了。log.buf_dirty_pages_added_up_to_lsn <= log.buf_ready_for_write_lsn。
log.available_for_checkpoint_lsn:该值之前的脏页都被刷到磁盘上了。但这可能会比实际值小,因为往flush list上挂脏页是乱序的。由log checkpointer线程更新。
log.last_checkpoint_lsn:上一次做检查点的lsn。由log checkpointer线程更新。log.last_checkpoint_lsn<=log.available_for_checkpoint_lsn<= log.buf_dirty_pages_added_up_to_lsn.
redo log线程模型
MTR提交
每一个 mtr 都有自己预留的一个缓冲区,mtr 产生的 log 会先被写到 mtr 内部的缓冲区,在 mtr 提交时,会做下面几件事:
- 计算该
mtr所产生的所有log的字节大小。 - 把
log写入到log buffer中相应的位置。 - 被该
mtr修改的page会被标记为dirty,并被移动到flush链表。 - 释放
mtr内部的缓冲区。
redo log写入log buffer
每个 mtr 在提交时,会根据自己需要写入的日志大小,向 log buffer 申请一块自己独有的写入空间,这块空间用一个结构体来控制:
struct Log_handle {
lsn_t start_lsn;
lsn_t end_lsn;
};
每个 mtr 拿到属于自己的空间后,redo log 的写入就可以并发起来。
如何保证多线程环境下多个 mtr 拿到的写入空间是连续且没有交叉的呢?InnoDB 维护的的全局 sn 是 std::atomic<sn_t>,每一个 mtr 都会调用 sn_t start_sn = log.sn.fetch_add(len); 来获取起始的 sn ,然后使用 handle.start_lsn = log_translate_sn_to_lsn(start_sn);将 sn 转为 lsn ,而fetch_add 操作是原子的。
问题来了,因为写入是并发的,所以 log buffer 可能会产生空洞的现象,即位置靠前的的线程还正在执行写入动作,而位置靠后的线程已经写完了日志。
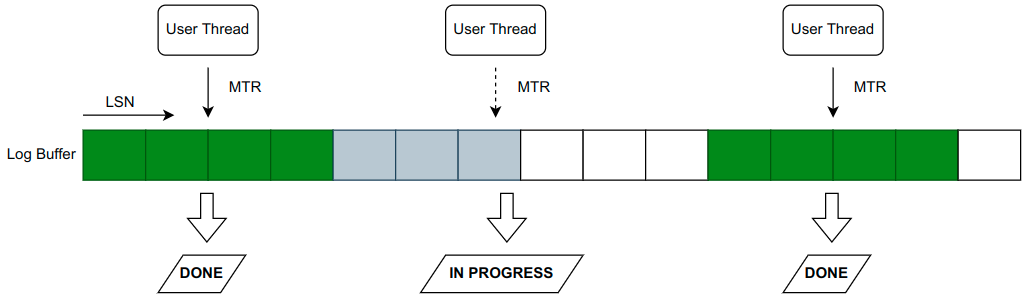
写到磁盘上的日志文件是不允许有空洞存在的,log writer 线程会不断地检测 log buffer ,将 log 从 log buffer 或者 write ahead buffer 刷新到文件系统的 page cache 中,当它发现自从上次写入后,log buffer 又产生了新的连续的日志,就会执行写入动作。那么log writer 线程在将 log 从 log buffer 往操作系统的 page cache 写入时,如何确定写的起点和终点?
InnoDB 设计了一种新的数据结构,即 Link_buf,来追踪当前 log buffer 的写入情况,直观的来看,它是一个长度固定的数组,数组中的元素可以原子的更新,刚开始数组中所有元素都是0,数组中的 1 个元素称为 1 个 slot。在逻辑上,这个数组是一个 ring buffer,每一个 lsn 都能通过取模的方式映射到数组的一个位置。用它可以非常方便的检测到当前 log buffer 有没有空洞。
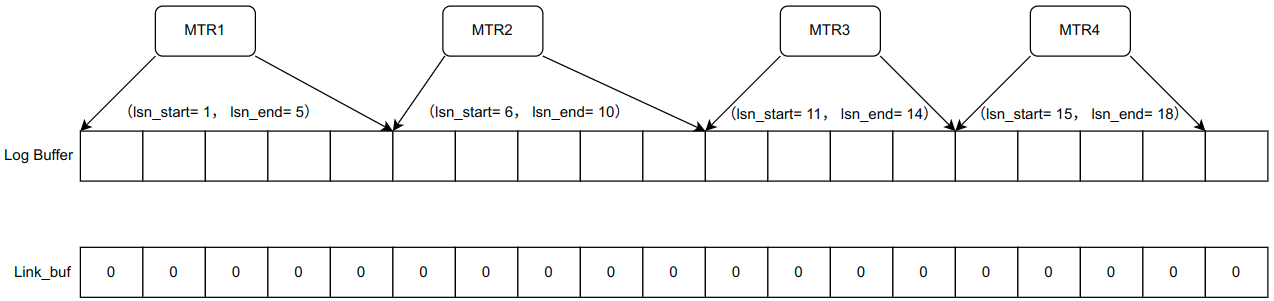
举个例子直观的感受一下:
假设当前系统产生了 4 个 MTR,它们分别获取到自己将要写入的位置,Link_buf 处于初始化状态,元素全为 0。
当一个 MTR 完成写入,就把这个 MTR 所写 log 的长度更新到 Link_buf 相对应的位置。此时,MTR1 、MTR2 、MTR4 完成了写入,而 MTR3 还正在写入,此时 Link_buf 变为:
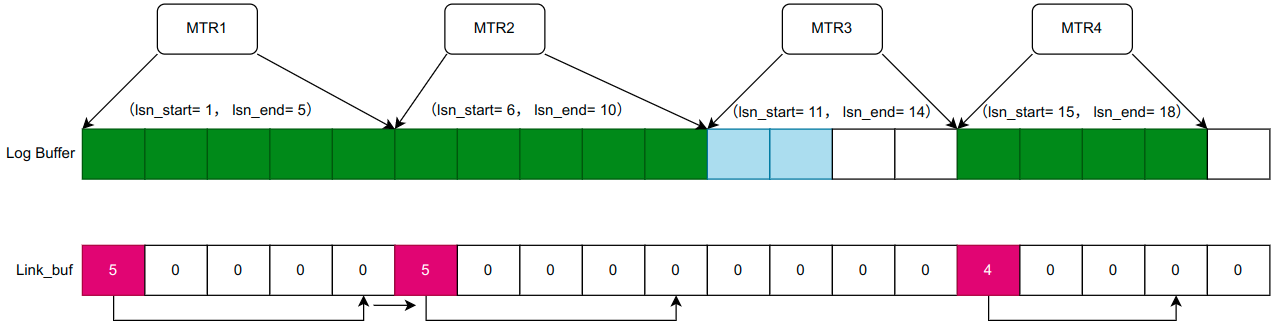
log writer 被唤醒之后,从起始位置开始扫描,依次往后跳跃,直到所跳到的位置是 0,便说明检测到了空洞的存在。
来看 Link_buf 所提供的接口:
redo log相关线程
log writer:将 log 从 log buffer 或者 write ahead buffer 刷新到 page cache 中。
log flusher:将 log 从 page cache 刷新到磁盘。
log write_notifier:通知用户线程,write 操作已经完成。
log flush_notifier:通知用户线程,fsync操作已经完成。
log checkpointer:确定可以安全 checkpoint 的 lsn 值,然后做 checkpoint。
log writer线程
log writer 线程每 10 微秒被唤醒一次,然后去检查 log buffer 中有没有新的连续的日志产生,如果有,就执行 write 操作,写入操作系统的 page cache 中。如果 log file 空间不足,那么该线程会被阻塞,唤醒 log checkpointer 线程,等待 log checkpointer 线程进行 fuzzy checkpoint 释放出空间。log writer 以 512字节为一个block单位执行写入动作。写入完成之后更新 write_lsn 的值。
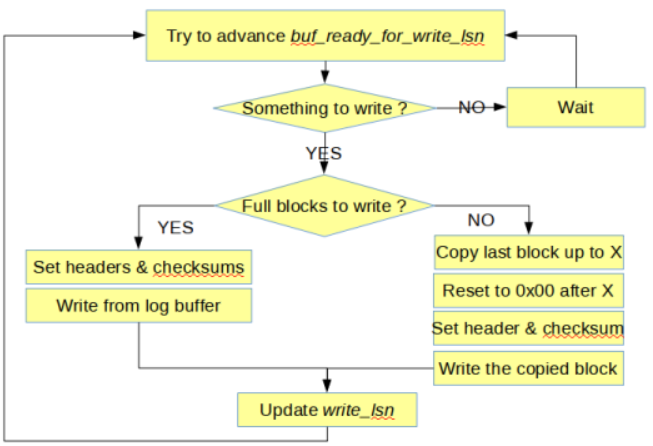
log flusher线程
由 log writer 线程执行 os_event_set 唤醒,判断 last_flush_lsn < log.write_lsn.load() ,也就是上一次 last_flush_lsn 比当前的 write_lsn,如果比他小,说明有新数据写入了, 那么就可以执行flush 操作了。
log checkpointer线程
每 1 s被唤醒一次,或者当 log 文件空间不足时被其它线程唤醒,被其它线程唤醒时,其他线程会带着一个 requested_checkpoint_lsn ,log_checkpointer 需要先同步刷新一些脏页,保证要做检查点之前的脏页都刷新到磁盘。
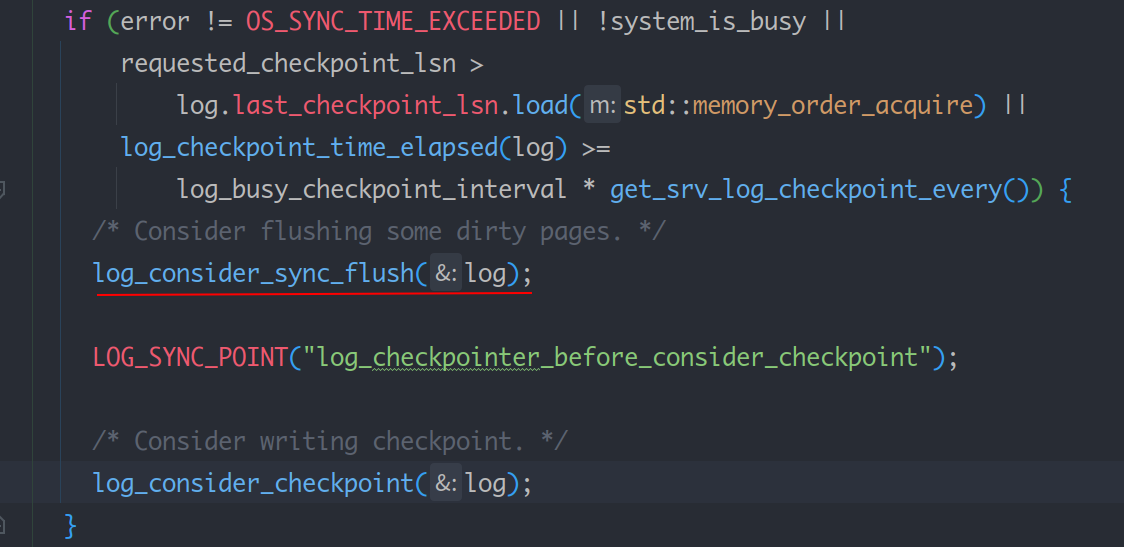
而 log_consider_checkpoint 负责计算当前可以推进的 lsn,然后将 checkpoint 信息写入 log 文件。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号