
OO第一单元--多项式求导总结
多项式求导
一、简单的多项式求导
1、设计思路
第一次设计,由于项只有变量项和常数项,在没有经过充分的构思下,我建立了一个可扩展性很差的假面向对象的代码。我搭建一个类Term来解析输入的字符串,并将解析得到指数作为key,系数作为value放在Term类的hashmap里面。解析完代码将hashmap导入到Item里面,经过一系列的处理转变成字符串并且输出。两个类不像是是类更像是两种方法,因为没有独立的特性,这导致它在后续的作业中可扩展性不强的一个原因。其中Inter类用于处理带符号的整数。
以下是该程序的一个结构:
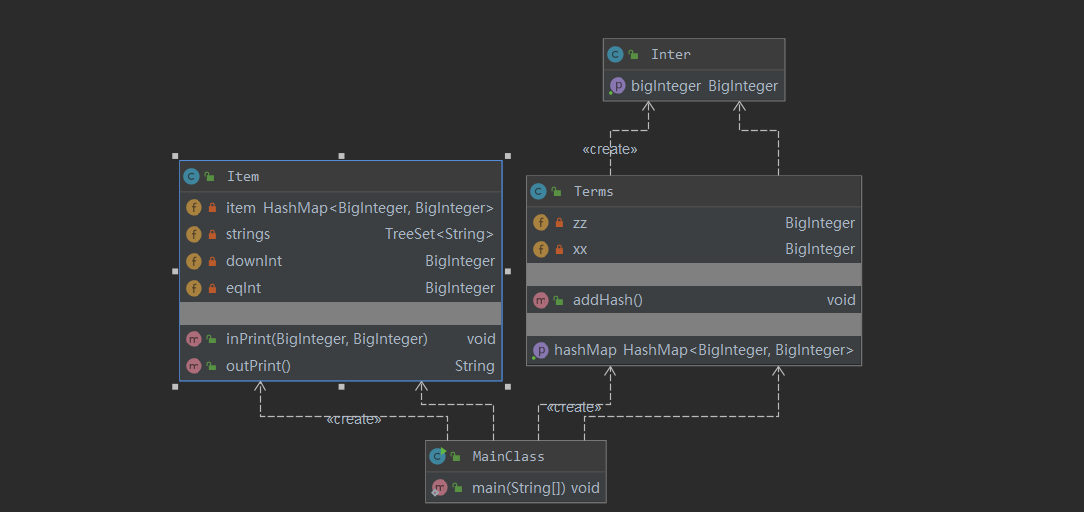
2、基于度量分析
Complexity Metrics(复杂度分析):
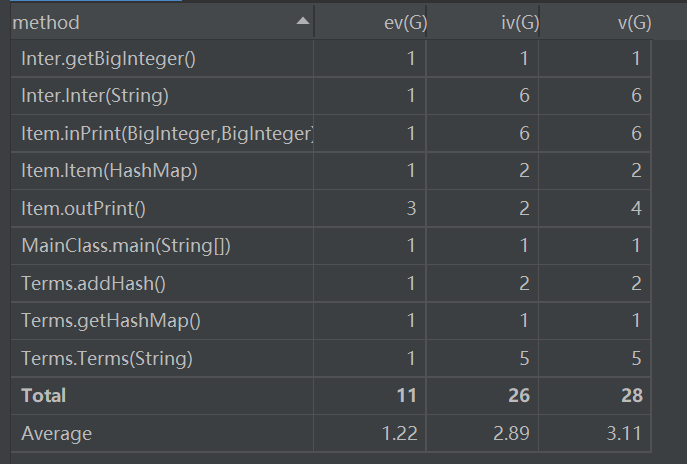
复杂度分析都不见红,表明整个结构还是比较好的,以及耦合度还是比较低,路径也不是很长,整个复杂度还是比较好的。
Dependency Metrics(依赖度分析):
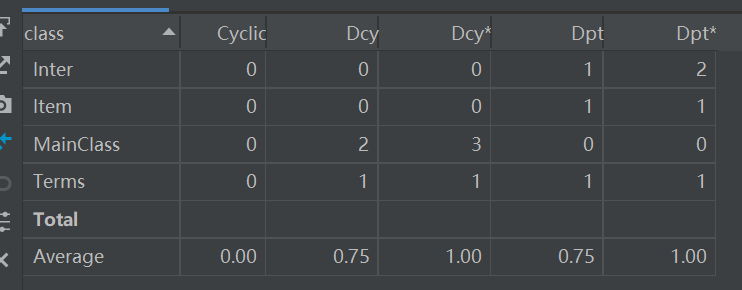
分析了该程序的依赖度,每个类之间间接或者相互依赖的数目都是零,表明这个这个设计易于理解和测试各个功能,类之间的依赖程度不高。
3、程序的bug分析和找bug策略
本次作业,强测和互测没有出现bug。在互测环节没有发现room里面同学的bug。找bug策略主要是看程序的正则表达式,以及化简。
4、总结
由于不好分析字符串的项,没有好好的考虑怎么设计一个具有很好扩展性的程序结构。由于没有考虑到工厂模式,担心如果解析项,又解析因子可能会出现一些重复的操作,因此程序只分成了解析多项式、优化输出多项式两个部份。在互测过程中,我学习到了一种将解析项和解析因子分开而又不重复正则匹配的方法,就是将所有的-全部替换成+&,然后用加号分裂表达式,使得解析字符串的难度大大降低。如果采用这种方法,那我的Inter类就显得十分的多余,因为Biginteger类可以解析字符串的数字的正负。
二、包含幂函数和正弦函数的多项式求导
1、设计思路
这次的因子存在四种,分别是常数项、幂函数、正弦函数、余弦函数。因此要想基于简单多项式的的结构进行重构,显然难度较大。经过互测阶段的代码学习,我打算通过取代部份字符,试图通过split的方法来解析出项和因子的想法,因为有可能因为将错误的多项式输入取代成正确的多项式而放弃。因为把错误取代成对所有的情况都规避掉的太容易出错了。
但是取代字符来降低解析的难度这个想法我一直都没有放弃。因此我先通过大正则来判断字符串是否正确,如果正确就进行下一步的解析过程。先处理字符串,获得每一项,在将项放进factory里面解析出因子,并且构成Item类,在factory类里面直接对Item类容器的各个元素进行求导,以及求导后的优化和输出。虽然这次项存在四种因子,但是我依然没有项把因子分开,因为没有分开便于将每个项的因子合并,以及降低求导的复杂度,和对多个类别的处理难度。
这次作业花时间最多的应该是在优化这边,我直接通过在Item类里面添加比较的方法,在Factory里面进行优化处理。针对几种三角函数独特的特性进行一定的操作,但是由于三角函数针对不同项的优化,顺序不同,产生的结果不一定是最优化。在请教了同学之后,我通过一次次的寻找两两匹配,如果找到最短项就取代输出字符串。但是因为时间有限我只是简单的进行了一次遍历,要达到最优化,还是得通过递归的方法才能达到最优的结构。
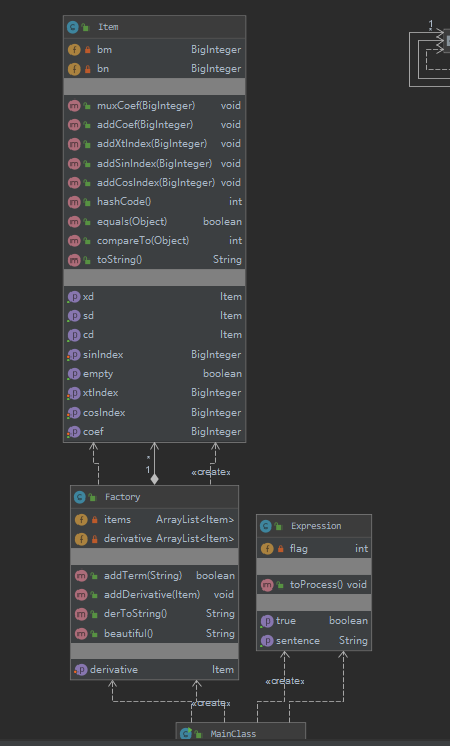
程序的结构如下图所示:
2、基于度量分析:
Complexity Metrics(复杂度分析):
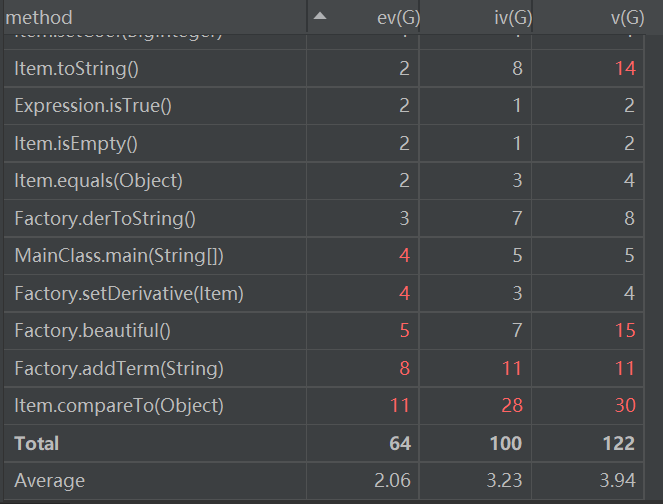 由于表格长度较长,我只截取改表格项中见红的部份。从图中可以看出Item的compareTo,Factory的addTerm以及优化方法的结构、耦合度、循环复杂度都不是很好,这可能是因为处理的单元是整个Item的项,使用较多的嵌套,调用有很大的关系。
由于表格长度较长,我只截取改表格项中见红的部份。从图中可以看出Item的compareTo,Factory的addTerm以及优化方法的结构、耦合度、循环复杂度都不是很好,这可能是因为处理的单元是整个Item的项,使用较多的嵌套,调用有很大的关系。
Dependency Metrics(依赖度分析):
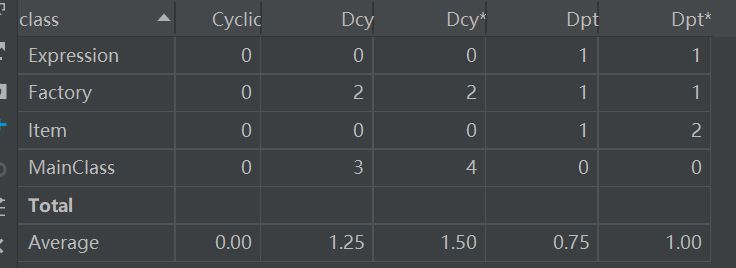
依赖度相对来说比较均衡不是很高。
3、程序的bug分析和找bug策略
在这次的强测中,我WA了两个点。但是这两个点都是一个bug:我在输出Item类的时候,为了能够优化**1的输出,忽略了 replaceAll 取代是是所有匹配到的字符串,虽然我是判断是否 endwith(**1) ,但是没有考虑到这个项中有四种可能因子。修复bug的时候我在 replaceAll 的取代正则里面加上了 (?![0-9]),即1的后面不能跟上数字,修复了bug。
互测环节中,我找到了几个bug,一个是解析字符串时忽略了-+-1的合法性,还有错误理解了指导书中关于因子的幂函数超过10000的WF。查找bug的方式,我是通过盲测和读取一部份的字符串匹配来找到bug的。
4、总结
在这次的作业中,对比同学的优秀代码,我觉得自己在面向对象的方面依旧做的不是很好,但是很明显这次想要通过面向过程,或者我第一次的结构中显得十分的困难。其中的Expression类时功能性类,Factory类承担了大部分的工作,Item类的耦合度相对来说就比较低。可以说Item类是一次很成功的类的尝试。我觉得优化部份的代码过于冗长,耦合性低,是最需要进一步进行优化的部份。
三、包含幂函数以及三角函数多项式及其组合的求导
1、设计思路
初次见到指导书,把我都给整懵了。各种嵌套,提取是个很艰难的过程,搭建表达式也是十分的困难,输出也是很困难,判断WF更是十分的困难。在苦苦想了一个晚上毫无进展的我决定放弃。
后来在讨论区中寻找解题的突破口时,我看到了一个同学的帖子,说可以把先把括号内部先给取代成一个字符,然后一步步的递归匹配下去,在匹配不到正确的项时直接输出WF。至于匹配到括号的内容放在一个数组里面。因此我进行了一次尝试,根据队列的方式,把匹配到的(......)全部取代成 @,并放进队列,再解析字符串时碰到@直接递归解析队列头的字符串,并将解析的表达式放在项结构中正确的位置 。 遵循第二次设计解析字符串的思路 ,稍作修改便可以成功解析表达式。(不知道为什么手动设计一个类似队列的数组和标记为会出现一些很迷惑的事情。)
当然搭建表达式也是一件相当困难的事情,因为表达式套项项套表达式,因子套项。曾经一度转不出圈圈,后来在研讨课上我学习了可以通过画结构图使得思路更加的清晰。显然如此复杂的结构,第二次设计中一个类就是一个项和所有因子的特性已经不再符合现有题目的复杂度。于是我只能老老实实的构建因子类,同时我把嵌套的表达式因子放在一个称为Exp的类中,Exp拥有父类因子类的所有特性,这么处理主要是为了简化我的思考。
在上述两个大魔王解决了之后,我对嵌套递归有了进一步的理解,求导,求导输出就十分的简单了。
以下是我的结构图:
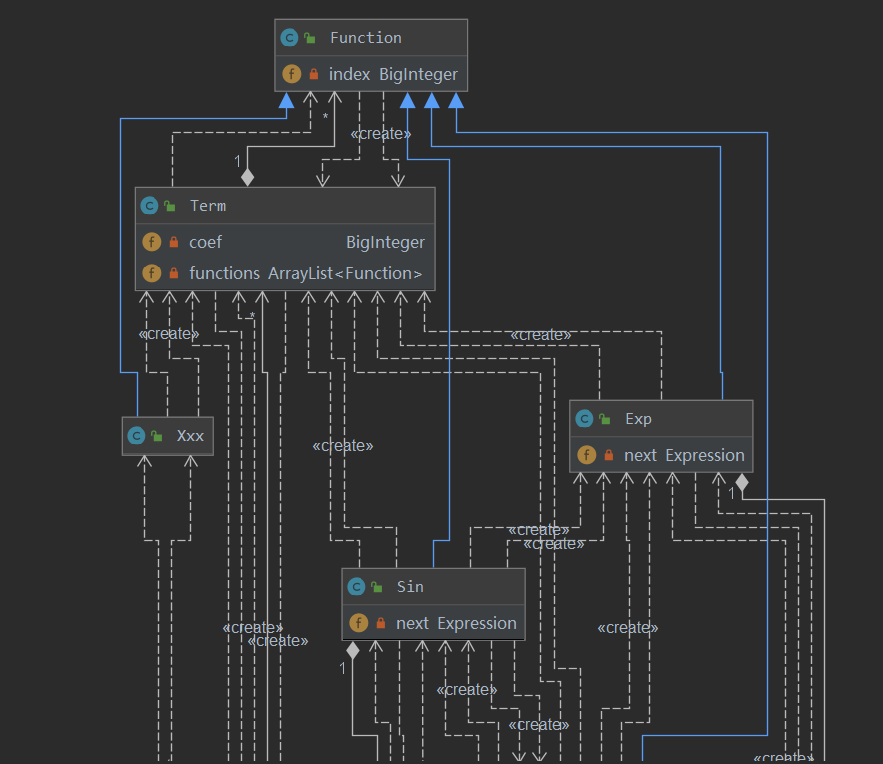
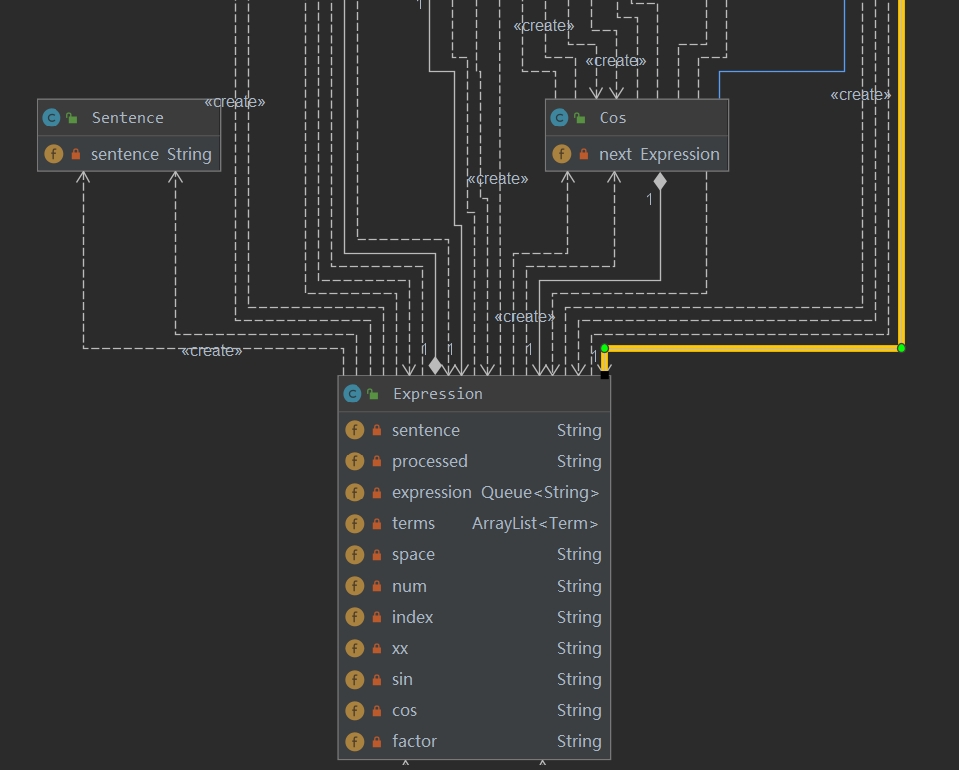
2、复杂度分析
Complexity Metrics(复杂度分析):
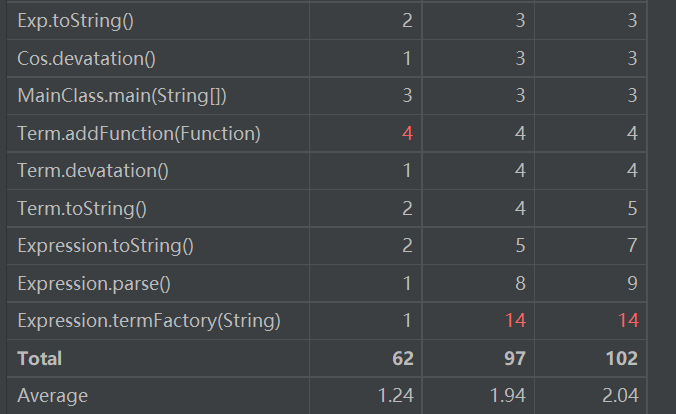
结构复杂度相对来说比较好,termFactory因为跟parse()的相关度很高,且一直不断往下递归,所以,耦合度和循环复杂度都比较高。
Dependency Metrics(依赖度分析):
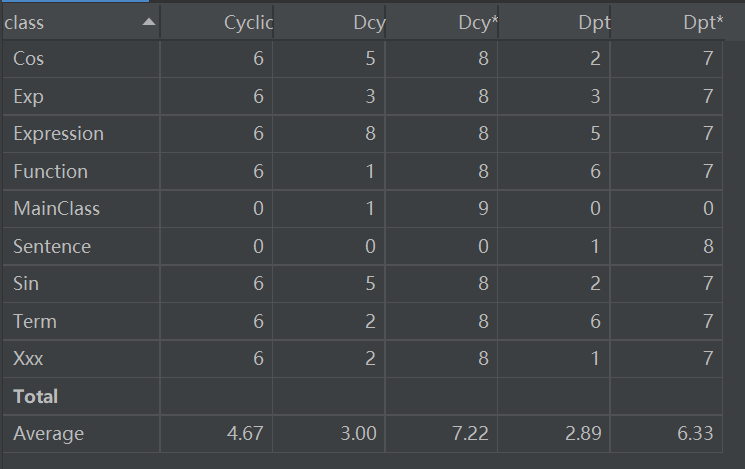
因为嵌套的原因几个因子类的依赖度还是比较大,但是整体的依赖程度还是比较好。
3、程序bug分析和找bug策略
在这次的强测中,我出现了两个WA。一个是超时,还有一个是对cos、sin的内部嵌套因子理解成表达式导致输出字符串WF。
超时的具体原因是因为这段代码:
1 for (int i = 0; i < terms.size(); i++) { 2 if (!terms.get(i).toString().isEmpty()) { 3 if (terms.get(i).toString().startsWith("-")) { 4 str = str + terms.get(i).toString(); 5 } else { 6 str = "+" + terms.get(i).toString() + str; } } }
因为偷懒没有给terms.get(i).toString()开辟一个新的空间存放,导致对一个对象连续三次调用,但是由于其本身就是一个递归的结构,循环加多次递归,导致出现多个表达式嵌套时就有爆栈的情况。吸取教训!
1 String s = "((" + matcher.group("in") + "))";
2 sentence.replaceAll( "(\\([ \t]*){3}(?<in>([^\\(\\)]*))([ \t]*\\)){3}", s);
在互测环节还被同学找到了一个bug还是replaceAll的问题,还是没有记住教训。
这次作业互测环节的找bug,由于每个人的输出都是十分的不一样,找到bug显得十分的艰难。于是我在同学的指导下,首次尝试用Ubtun写可运行程序,通过py的脚本来测试代码。找bug显得十分的容易。但是自动测试很难测试到边界条件,因此屋子里一些运行超时的我还是没有找出来。找到的bug都是一些由于优化出现的低级错误。
4、总结
这次作业让我深刻体会了什么是面向对象,虽然是再一次的重构,但是使得我对工厂模式,对对类理解的更加的深刻。虽然这次作业的bug有点多,但是我也学习了很多的经验教训。还有采用面向对象的编程方法,使得递归理解起来更加的浅显易懂。
四、应用对象创建模式
回顾这三次次作业,题目从简单到相当的复杂,我的面向过程的程序搭建显得越来越无力,因此不得不一次又一次的重构,但是我的重构也变得越来越面向对象。在第三次的作业中我细化分类,找寻相同点,构造父类,并且通过搭建工厂模式,使得我的程序一步步的细化,并且将每个小类很好的封装,使得整个搭建过程相当的舒服,并且我想它的可扩展性也变得十分的好。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号