AWS MSSQL to PG
背景介绍:
公司业务完全在AWS 云上,因为历史原因和业务发展需要, DBA需要维护aws RDS的异构数据长期持续同步,AWS US的RDS(SQL Server 2016)有db1作为数据的源端,
AWS CN的RDS(PostgreSQL 12)有db2 作为数据的目的端, 仅仅需部分表持续复制,可以将AWS US,AWS CN看做2朵物理分开的不同云。经过大量测试决定使用AWS DMS作为数据持续同步的工具。
难点介绍:
难点1:2朵跨地域的云网络受限。 通过拉专线解决。
难点2:DMS 设计用于一次性迁移使用并不适合长期持续复制。
难点3:DMS不稳定出错后需要重新完全加载数据。
难点4:有10几张巨大表。
难点5:DMS需要SQL Server端开启CDC来实现持续复制,DMS内部实现数据的获取/转换/分发完全是一个黑盒。
难点6:RDS的CDC capture job 和CDC clean job权限有限制,对用户透明。
难点7:每天的业务变更数据行不稳定,无法定一个合适的 CDC capture job 参数。
难点8:通过调查和profile 发现DMS通过 fn_dblog函数获取SQL Server的变更,既要保证SQL server 维持一定量的日志不被截断,又要尽量保证SQL Server的日志文件使用量在一个合理大小范围内保证DMS task 高效。
解决方案:
难点1/3:研究发现 DMS与源端的流量远远大于DMS与目的端的流量,并且大部分DMS 问题发生在DMS 实例与源端之间。 经过测试发现把DMS 实例放在源端局域网内,更稳定,延迟更小。
难点3:在SQL Server端设置JOB 不断的获取日志点,DMS task 2步同步数据的方式,1)FULL load 完全加载数据 2) DMS task 指定日志点的方式,可以选择靠前几小时的日志点进行持续复制变更数据。
这样如果以后DMS task 发生了无法修复的错误,并不需要大量时间完全加载数据,我们只需要修改 把2)的日志点修改为发生错误前的日志槽点即可。
难点4:和业务沟通发现巨大表中包含了全球数据但是CN 只需要CN部分的业务的数据. 在SQL Server端通过JOB 间隔性的把CN的数据分离出来到****_CN 表,只需要在DMS task中将****_CN表在目的端做一个rename回原表明即可。
难点5/6/7/8: 研究发现如下
CDC 相关的JOB 运行参数可以入下图方式获取,并且默然一天运行一次[CDC capture job] 来释放log这会导致拥有一个巨大log file,是DMS task 获取数据效率下降,可以使用本地实例验证猜想
use [db1]
go
exec sys.sp_cdc_help_jobs

DMS 内部运行原理如下图
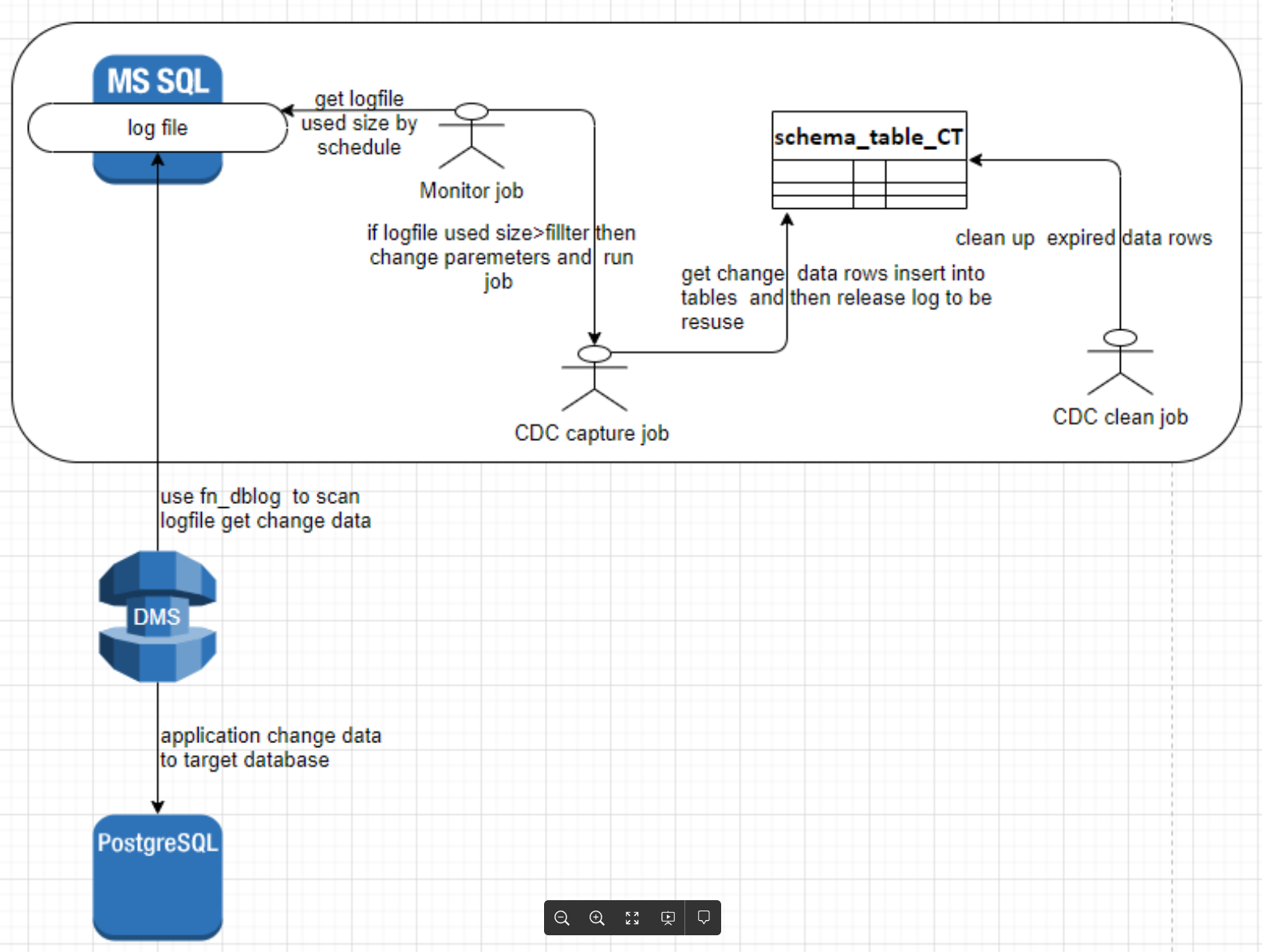
针对以上难点设计了一个procedure 来根据log file 空间使用量 梯段变更[CDC capture job] 的 maxtrans 和 maxscans的参数值,并运行[CDC capture job] 。 使 log file 始终保持在一个合理大小范围内。
使用SQL agnet 定时调用改prodedure. pridedure 的梯段值和 job 运行的评率可以根据情况调整满足各自的需求。
step1 在对应源端的db创建procedure
use [db1]
go
/*
run demo:
exec [dbo].[updba_Dynamic_cdc_capture_parameter]
get running record:
select * from dbo.dmsdba_capture_audit
*/
alter proc [dbo].[updba_Dynamic_cdc_capture_parameter]
as
begin
set nocount on
if object_id('dbo.dmsdba_capture_audit') is null
begin
create table dbo.dmsdba_capture_audit(
intime datetime primary key,
log_used_MB int,
after_log_used_MB int,
starttime datetime,
endtime datetime,
pollinginterval bigint,
maxtrans int,
maxscans int
)
end
else
begin
delete dbo.dmsdba_capture_audit where intime<dateadd(DAY,-90,GETDATE())
end
declare @log_used_MB int ,@after_log_used_MB int
declare @start datetime, @end datetime
select @log_used_MB =FILEPROPERTY ( name , 'SpaceUsed' )/128
from sys.database_files with(nolock) where type_desc='Log'
declare @pollinginterval_input bigint
,@maxtrans_input int
,@maxscans_input int
if @log_used_MB>5120 and @log_used_MB<10240
begin
/* set parimeter for job cdc.MyCadent_captur */
select @pollinginterval_input=86399
,@maxtrans_input=10000
,@maxscans_input=2
end
if @log_used_MB>=10240 and @log_used_MB<20480
begin
/* set parimeter for job cdc.MyCadent_captur */
select @pollinginterval_input=86399
,@maxtrans_input=20000
,@maxscans_input=4
end
if @log_used_MB>=20480
begin
/* set parimeter for job cdc.MyCadent_captur */
select @pollinginterval_input=86399
,@maxtrans_input=40000
,@maxscans_input=8
end
if @log_used_MB>5120
begin
declare @job_status1 nvarchar(200),@job_status2 nvarchar(200)
--run job capture job to get CDC data into ***CT, and then release CDC log
EXEC sys.sp_cdc_change_job @job_type = 'capture' ,@pollinginterval = @pollinginterval_input,@maxtrans=@maxtrans_input,@maxscans=@maxscans_input
begin try
exec sp_cdc_stop_job 'capture'
end try
begin catch
select 1
end catch
waitfor delay '00:00:05'
select @start=getdate()
exec sp_cdc_start_job 'capture'
WHILE 1=1
BEGIN
SELECT @job_status1= NULL,@job_status2=null
select @job_status1=scan_phase from sys.dm_cdc_log_scan_sessions
where start_time>=(select max(start_time) from sys.dm_cdc_log_scan_sessions )
waitfor delay '00:00:05'
select @job_status2=scan_phase from sys.dm_cdc_log_scan_sessions
where start_time>=(select max(start_time) from sys.dm_cdc_log_scan_sessions )
IF @job_status1=N'Done' and @job_status2=N'Done'
BREAK
WAITFOR DELAY '00:00:05'
END
select @end=getdate(),@after_log_used_MB =FILEPROPERTY ( name , 'SpaceUsed' )/128
from sys.database_files with(nolock) where type_desc='Log'
insert into dbo.dmsdba_capture_audit(intime,log_used_MB,after_log_used_MB,starttime,endtime,pollinginterval,maxtrans,maxscans)
select getdate(), @log_used_MB, @after_log_used_MB,@start,@end,@pollinginterval_input,@maxtrans_input,@maxscans_input
--after capture data, run clean job to clean ***CT table
begin try
exec sp_cdc_stop_job 'cleanup'
end try
begin catch
select 1
end catch
waitfor delay '00:00:05'
exec sp_cdc_start_job 'cleanup'
--finally change @maxtrans/@maxscans back to a small value to maksure dms do not lost log
EXEC sys.sp_cdc_change_job @job_type = 'capture' ,@pollinginterval = 86399,@maxtrans=5,@maxscans=2
begin try
exec sp_cdc_stop_job 'capture'
end try
begin catch
select 1
end catch
waitfor delay '00:00:05'
exec sp_cdc_start_job 'capture'
end
end
GO
step2 创建 JOB 根据需要定时运行 procedure updba_Dynamic_cdc_capture_parameter

 浙公网安备 33010602011771号
浙公网安备 33010602011771号