


5.RDD操作综合实例
一、词频统计
A. 分步骤实现
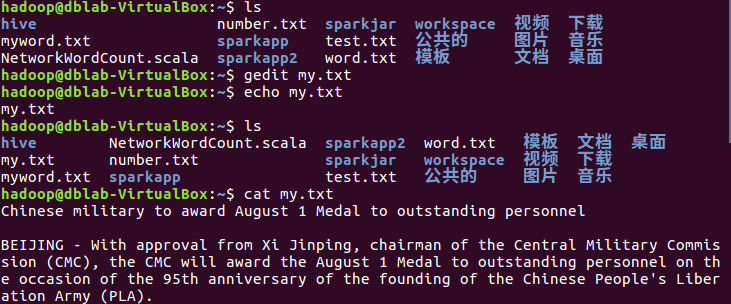
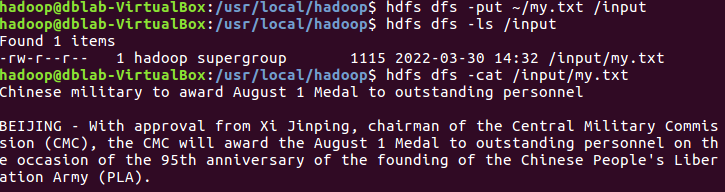
1.上传到hdfs上
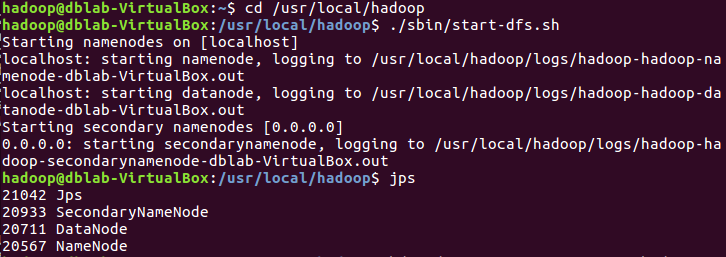
2.读文件创建RDD

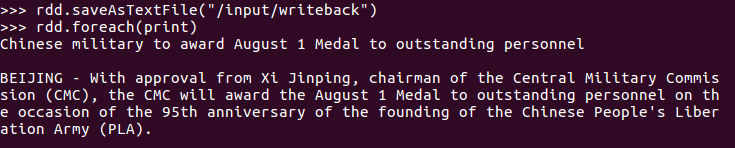
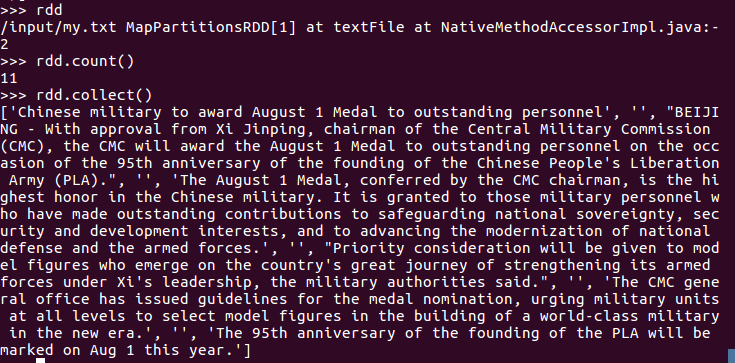
3.分词

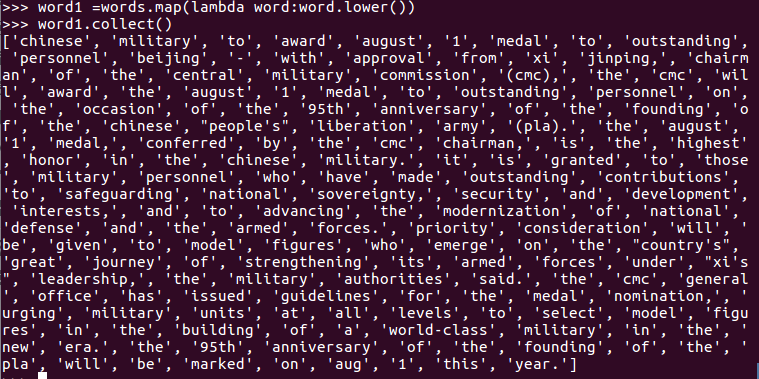
4.排除大小写lower(),map()
标点符号re.split(pattern,str),flatMap()

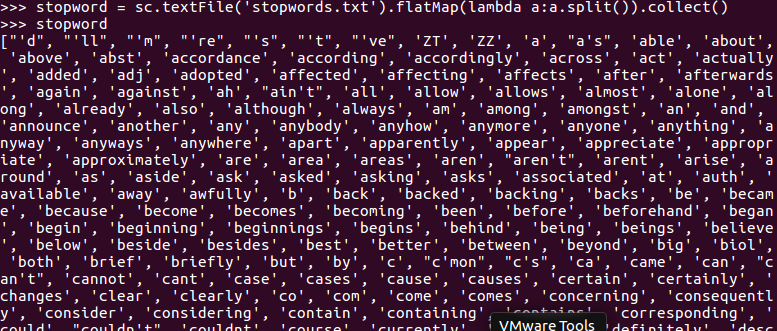
停用词,可网盘下载stopwords.txt,filter(),


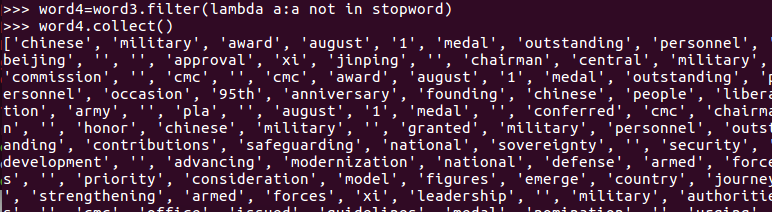


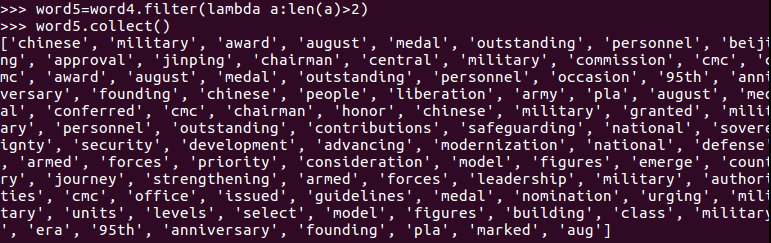
长度小于2的词filter()
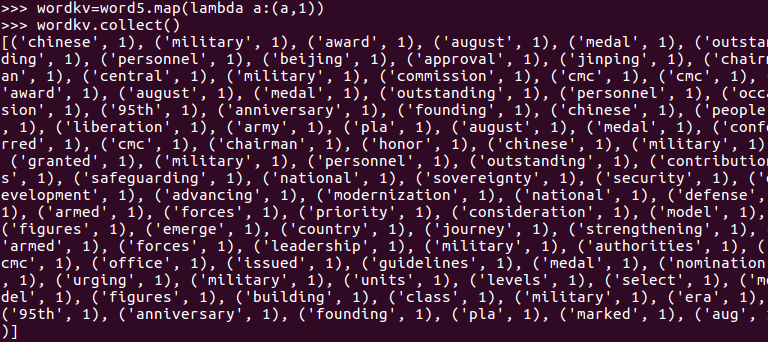
5.统计词频
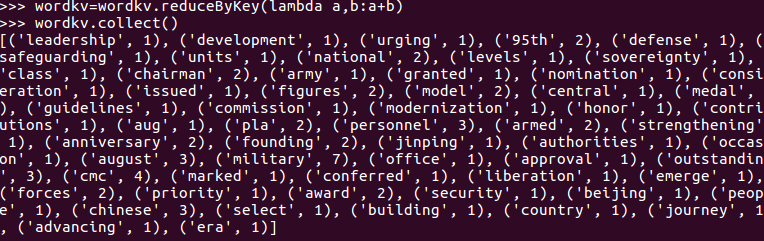
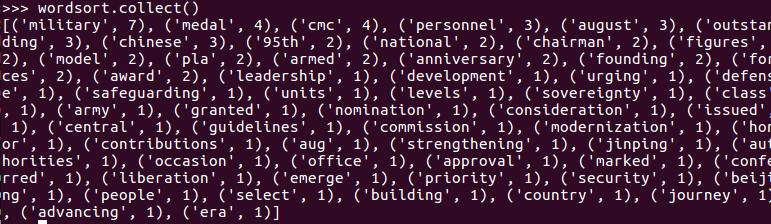
6.按词频排序

7.输出到文件

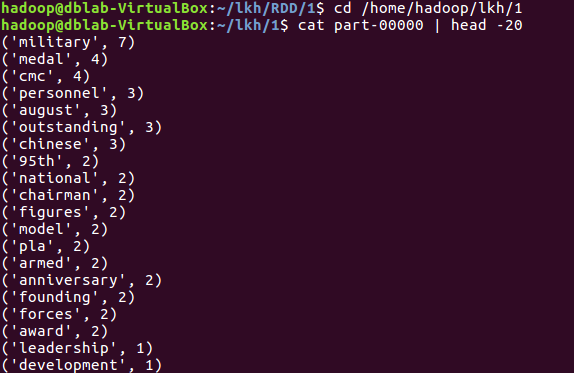
8.查看结果
B. 一句话实现:文件入文件出
C. 和作业2的“二、Python编程练习:英文文本的词频统计 ”进行比较,理解并用自己话表达Spark编程的特点。
Spark中,RDD允许用户显式地将工作集缓存在内存中,后续能够重复使用工作集,这提升了速度。
并且Spark提供的主要抽象是弹性分布式数据集(RDD),通常RDD很大,会被分成很多个分区,分别保存在不同的节点上。
二、求Top值
网盘下载payment.txt文件,通过RDD操作实现选出最大支付额的用户。

1.丢弃不合规范的行:
空行
少数据项
缺失数据
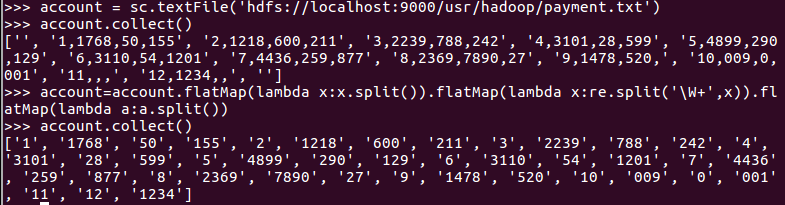
2.按支付金额排序




3.取出Top3


 浙公网安备 33010602011771号
浙公网安备 33010602011771号