


RDD操作
一、 RDD创建
1.从本地文件系统中加载数据创建RDD
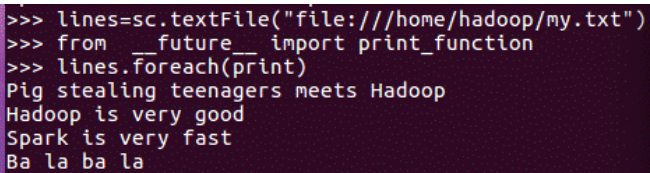
2.从HDFS加载数据创建RDD
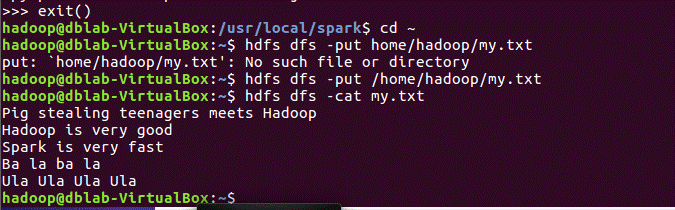
exit()退出上一步后启动hdfs上传文件且查看文件
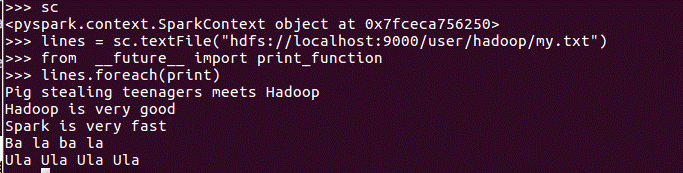
进入spark加载刚刚传入hdfs的文件
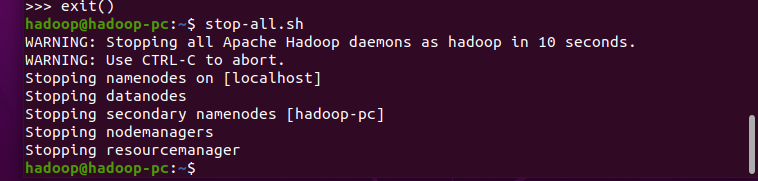
不使用HDFS了,记得停止hdfs
3.通过并行集合(列表)创建RDD
输入列表字符串numpy生成数组
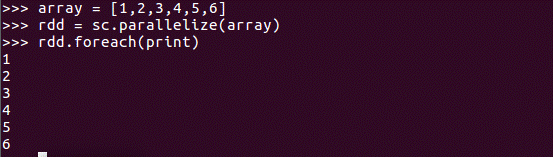
二、 RDD操作
1.转换操作
filter(func)

map(func)
下面rdd2实行rdd1加10操作

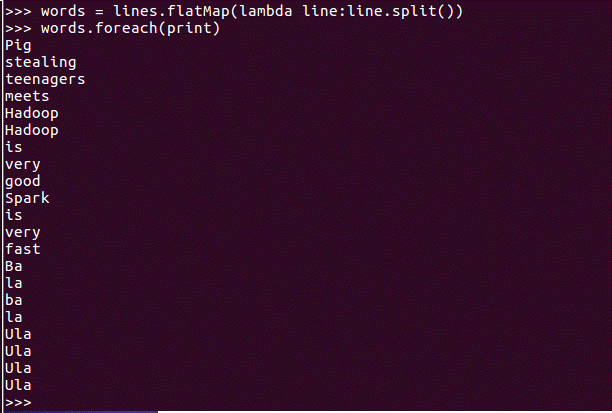
flatMap(func)
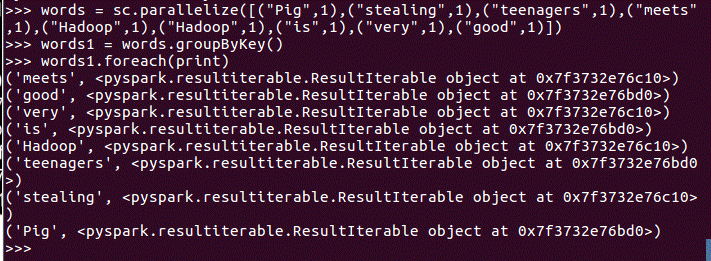
groupByKey()
这里用的是输入的键值对来实验groupByKey()等下面的函数操作
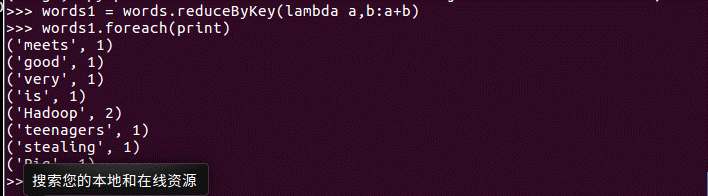
reduceByKey()
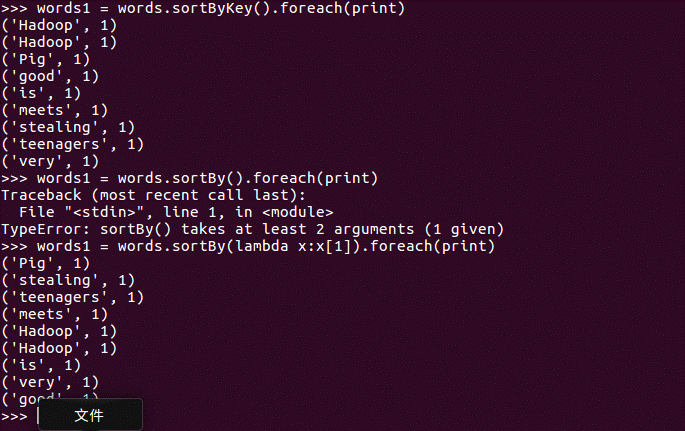
sortByKey()词频统计按单词排序
sortBy()词频统计按词频排序
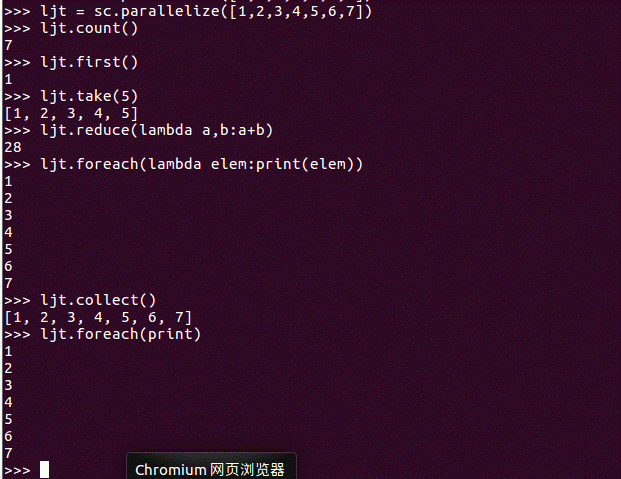
2.行动操作
与reduceByKey区别
reduce:将RDD中元素前两个传给输入函数,产生一个新的return值,新产生的return值与RDD中下一个元素(第三个元素)组成两个元素,再被传给输入函数,直到最后只有一个值为止。
redeceByKey:对元素为KV对的RDD中Key相同的元素的Value进行binary_function的reduce操作,因此,Key相同的多个元素的值被reduce为一个值,然后与原RDD中的Key组成一个新的KV对。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号