第一次个人编程作业
一、github项目链接:https://github.com/101347/031804121
二、计算模块接口的设计与实现过程
经过查阅,我最终选择余弦相似度的做法。
函数有:
1、string(file)
文件转字符串并清洗文字
2、get_vec(str1, str2)
获取向量
3、cosine_similarity(vec1, vec2)
计算余弦相似度
流程图:

算法说明:
余弦相似度用向量空间中两个向量夹角的余弦值作为衡量两个个体间差异的大小,因此余弦值越接近1,则两个个体越相似。
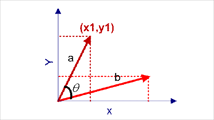
通过以下公式进行计算
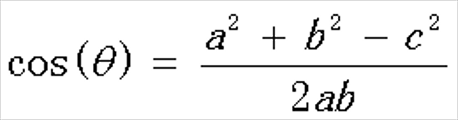
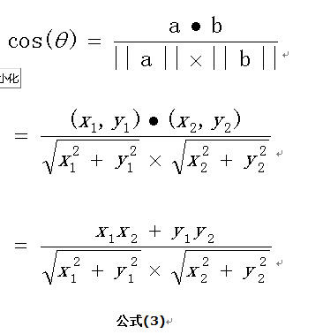
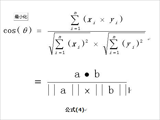
为了让余弦相似度算法更加准确,通过TF-IDF算法加入相关系数的乘法运算

DF系数越大,说明n越小,n越小说明使用的次数使用的地方越少。同时,因为IDF系数越大,跟A的余弦值越小,那么相似度就越小。所以,使用频繁的词,可能跟某个句子的相似度较大;而使用不频繁的词,相似度就可能较小。
三、计算模块接口部分的性能改进
性能耗时分析:



覆盖率:

四、计算模块部分单元测试展示
测试代码函数部分:
import re import numpy as np import jieba import jieba.analyse from collections import Counter # 文件转字符串 def string(file): with open(file, 'r', encoding='utf-8') as File: # 读取 lines = File.readlines() line = ''.join(lines) # 去特殊符号 punctuation = '!@#$%^&*(),,.?;:-”、。;《》' s = re.sub(r"[%s]+" % punctuation, "", line) return sdef get_vec(str1, str2):
# 获取词向量
str1_info = jieba.analyse.extract_tags(str1, withWeight=True)
str2_info = jieba.analyse.extract_tags(str2, withWeight=True)
# 为排除0的情况而转成counter
str1_dict = Counter({i[0]: i[1] for i in str1_info})
str2_dict = Counter({i[0]: i[1] for i in str2_info})
#
bags = set(str1_dict.keys()).union(set(str2_dict.keys()))
# 进行从小到大的重新排序
bags = sorted(list(bags))
vec_str1 = [str1_dict[i] for i in bags]
vec_str2 = [str2_dict[i] for i in bags]
# 将结构数据转化为ndarray,因asarray不会占用新内存而不选择array
vec_str1 = np.asarray(vec_str1, dtype=np.float)
vec_str2 = np.asarray(vec_str2, dtype=np.float)
return vec_str1, vec_str2def cosine_similarity(vec1, vec2):
# 计算余弦相似度
vec1, vec2 = np.asarray(vec1, dtype=np.float), np.asarray(vec2, dtype=np.float)
up = np.dot(vec1, vec2)
down = np.linalg.norm(vec1) * np.linalg.norm(vec2)
# 四舍五入保留2位小数
return round(up / down, 2)
def test(doc_name):
doc_file = "D:/sim_0.8/" + doc_name
str_test = string(doc_file)
similarity = cosine_similarity(*get_vec(doc, str_test))
print("%s 的相似度 = %.2f" % (doc_name, similarity))
测试函数包括string(file)(文件转字符串)、get_vec(str1, str2)(获取向量)、cosine_similarity(vec1, vec2)(计算余弦相似度)以及test(doc_name)(运行、输出)
测试代码思路主要为:
- 将目标文件转换成一个字符串
- 将字符串转换成向量矩阵
- 通过公式计算出余弦相似度
- 输出文件名+相似度
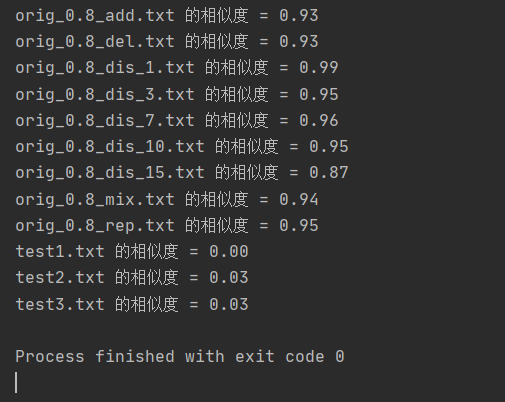
除了样例中的九个测试文本,我添加了《背影》作为test1.txt,而test2.txt和test3.txt是在test1.txt的基础上,在不同位置插入原文的片段。12个测试结果与预期相符
测试结果如下图:
五、计算模块部分异常处理说明
读取异常:
try:
doc = input("请输入原文文件:")
doc_test = input("请输入测试文件:")
output = input("请输入输出文件:")
str_doc = string(doc)
str_doc_test = string(doc_test)
similarity = cosine_similarity(*get_vec(str_doc, str_doc_test))
f = open(output, "w")
f.write(str(similarity) + "\n")
f.close()
except Exception as e:
print(e)
try:
doc = input("请输入原文文件:")
doc_test = input("请输入测试文件:")
output = input("请输入输出文件:")
str_doc = string(doc)
str_doc_test = string(doc_test)
similarity = cosine_similarity(*get_vec(str_doc, str_doc_test))
f = open(output, "w")
f.write(str(similarity) + "\n")
f.close()
except Exception as e:
print(e)六、PSP表格
| PSP2.1 | Personal Software Process Stages | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning | 计划 | 60 | 70 |
| Estimate | 估计这个任务需要多少时间 | 60 | 50 |
| Development | 开发 | 600 | 960 |
| Analysis | 需求分析 (包括学习新技术) | 150 | 180 |
| Design Spec | 生成设计文档 | 60 | 60 |
| Design Review | 设计复审 | 30 | 30 |
| Coding Standard | 代码规范 (为目前的开发制定合适的规范) | 30 | 20 |
| Design | 具体设计 | 70 | 80 |
| Coding | 具体编码 | 200 | 210 |
| Code Review | 代码复审 | 30 | 30 |
| Test | 测试(自我测试,修改代码,提交修改) | 60 | 80 |
| Reporting | 报告 | 80 | 90 |
| Test Repor | 测试报告 | 20 | 30 |
| Size Measurement | 计算工作量 | 10 | 15 |
| Postmortem & Process Improvement Plan | 事后总结, 并提出过程改进计划 | 20 | 30 |
| 合计 | 1480 | 1905 |
七、总结
这次的作业好难啊,花了很长时间,弄懂很多东西,但也有很多东西还不懂。总之,希望自己能好好地完成每次作业,获得更多知识吧。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号