

MySQL主从同步异常,怎么破?
一、问题背景
在前几天,由于工作需要,我在测试环境的MySQL数据库里删除了几条数据(根据id执行了delete语句),但是发现web页面数据并未删除。后跟运维同事确认,才发现测试环境的数据库作了主从架构而非单体,而我是在从库作了的删除操作...后面,另一个同事又在主库作了一样的删除操作,此时,查看从库状态发现,主从同步出现异常了...平常一直以谨慎著称的我,没想到还是栽在了连错数据库的失误上。虽然最终解决了这个问题,但我还是作出了对应的反思和总结,形成了一种经验,以此来提醒大家,以后避免出现这样的问题或是遇到这种问题要懂得如何解决。
二、基础知识
在进入主题前,还是先来给大家回顾一些有关MySQL的主从同步(复制)的基础知识。
1、什么是Binlog?
Binlog(Binary Log)是MySQL的二进制日志文件,以二进制形式记录所有对数据库的修改操作(如INSERT、UPDATE、DELETE、DDL语句等),但不记录不修改数据的查询(如SELECT)。它是MySQL的核心日志之一,主要用于数据恢复、主从复制和增量备份等场景。Binlog以事件(Event)为单位存储,每个事件描述一次具体的数据库操作。
2、Binlog的作用?
Binlog的主要作用包括:
- 数据恢复:通过重放Binlog事件,可将数据库恢复到特定时间点或故障前的状态。例如,结合全量备份和Binlog可实现时间点恢复(PITR)。
- 主从复制:主库将Binlog发送给从库,从库重放这些事件以实现数据同步。
- 增量备份:记录数据库的增量变更,减少全量备份的频率和存储开销。
- 审计:分析Binlog可追踪数据库操作历史,用于安全审计。
3、Binlog的记录模式都有哪些以及他们的优缺点?
MySQL支持三种Binlog格式:
- STATEMENT(语句模式)
优点:仅记录SQL语句,日志量小,节省磁盘IO。
缺点:某些函数(如NOW()、UUID())或非确定性操作可能导致主从数据不一致。
- ROW(行模式)
优点:记录每行数据的变更细节,确保主从数据一致性,适用于复杂操作(如触发器、存储过程)。
缺点:日志量大,尤其是批量操作(如ALTER TABLE)会显著增加日志体积。
- MIXED(混合模式)
优点:根据SQL语句自动选择STATEMENT或ROW模式,平衡日志量和一致性。
缺点:仍需人工监控特定场景下的日志增长问题。
企业场景选择建议:
- 若业务简单且无需特殊函数,优先使用STATEMENT;
- 若对一致性要求高(如金融系统),选择ROW模式;
- 混合场景可选用MIXED
4、Binlog文件内容的组成?
Binlog文件由以下部分组成:
- 文件结构:
索引文件(如hostname.index):记录所有Binlog文件名列表。
日志文件(如binlog.000001):包含多个事件,以Format_description事件开头,Rotate事件结尾。
- 事件结构:
事件头(Header):包含事件类型、时间戳、服务器ID等元数据。
事件体(Body):记录具体操作内容(如SQL语句或行变更数据)。
- 常见事件类型:
Query Event:记录DDL和DML语句。
Table Map Event:在ROW模式下记录表结构信息。
Write/Update/Delete Rows Event:记录行数据的增删改操作。
5、主从复制的分类?
MySQL主从复制根据数据同步机制和一致性保障的不同,主要分为以下三类:
(1)异步复制(Asynchronous Replication)
- 特点:
主库(Master)执行完事务后立即返回客户端,不等待从库(Slave)确认是否接收或处理binlog。
默认的复制模式,性能最高,但存在数据丢失风险(如主库崩溃时未同步的binlog可能丢失)。
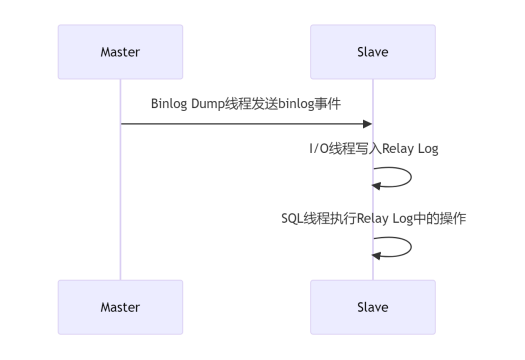
- 线程模型:
主库:通过Binlog Dump线程发送binlog事件。
从库:I/O线程接收binlog并写入中继日志(Relay Log),SQL线程重放日志。
- 适用场景:对一致性要求不高、追求高吞吐量的读写分离场景。
(2)半同步复制(Semi-Synchronous Replication)
- 特点:
主库提交事务前需等待至少一个从库确认接收binlog(写入Relay Log),否则超时后降级为异步复制。
平衡性能与一致性,减少数据丢失风险,但增加延迟(至少一个TCP/IP往返时间)。
- 配置要求:
需安装插件(如rpl_semi_sync_master.so和rpl_semi_sync_slave.so)。
MySQL 5.7+默认使用增强半同步(AFTER_SYNC),避免主库提交后崩溃导致数据不一致。
- 适用场景:金融、电商等对数据一致性要求较高的业务。
(3)组复制(Group Replication, MGR)
- 特点:
基于分布式一致性协议(Paxos变体),组内多数节点(N/2+1)达成一致后提交事务,实现强一致性。
支持多主写入(需避免并发冲突),但生产环境通常采用单主模式。
- 优势:
高可用性:自动故障检测与切换,节点故障不影响集群。
数据强一致:解决异步/半同步的潜在不一致问题。
- 限制:
仅支持InnoDB表且需主键,必须开启GTID和ROW格式binlog。
集群节点数建议为奇数(如3台以上)。
- 适用场景:高可用集群、多活架构等对一致性和容灾要求极高的场景
6、MySQL是如何基于Binlog完成主从同步(复制)的?它的基本流程?
MySQL基于Binlog的主从同步(复制)是一种异步机制,通过二进制日志(binlog)实现数据从主库(Master)到从库(Slave)的同步。以下是其核心流程和关键组件:
(1) 主库记录变更到binlog
数据变更触发:主库执行写操作(如INSERT、UPDATE、DELETE、DDL)时,除修改数据外,还会将操作记录到binlog中。
binlog格式:支持STATEMENT(记录SQL语句)、ROW(记录行变更数据)、MIXED(混合模式),通常推荐ROW模式以保证一致性。
线程参与:主库的Binlog Dump线程负责将binlog内容发送给从库。
(2)从库拉取并存储binlog
I/O线程:
从库的I/O线程连接主库,请求指定位置的binlog(通过CHANGE MASTER TO命令配置主库信息及起始位置)。
主库的Binlog Dump线程响应请求,将binlog事件发送给从库的I/O线程。
I/O线程将接收到的binlog写入从库的中继日志(Relay Log)。
(3)从库重放Relay Log
SQL线程:
从库的SQL线程读取Relay Log中的事件,解析并执行对应的SQL语句或行变更操作,将数据应用到从库。
并行复制优化:MySQL 5.7+支持多线程复制(设置slave_parallel_workers>0),提升同步效率。
(4)同步完成与持续监控
ACK确认:异步复制下,主库不等待从库确认;半同步复制(semi-sync)需至少一个从库接收binlog后主库才提交事务。
状态检查:通过SHOW SLAVE STATUS命令监控Slave_IO_Running和Slave_SQL_Running状态,确保线程正常运行
7、涉及Binlog的常用命令?
-- 检查是否启用binlog SHOW VARIABLES LIKE 'log_bin'; # 返回ON表示已开启 -- 查看binlog文件列表及大小 SHOW BINARY/MASTER LOGS; # 列出所有binlog文件及大小 -- 查看当前使用的binlog文件及位置 SHOW MASTER STATUS; # 显示最新binlog文件名和Position -- 通过SQL命令解析事件 SHOW BINLOG EVENTS IN 'mysql-bin.000001' FROM 100 LIMIT 10; # 查看指定文件的第100位开始10条事件 注意:无LIMIT可能消耗大量资源。 -- 使用mysqlbinlog工具解析(命令行执行) mysqlbinlog -vv --base64-output=DECODE-ROWS mysql-bin.000001 > binlog.txt # 解析ROW格式日志并输出到文件 -- 支持按时间或位置过滤: mysqlbinlog --start-datetime="2025-06-01" --stop-position=2000 mysql-bin.000001 -- 从库配置binlog同步起点 CHANGE MASTER TO MASTER_LOG_FILE='mysql-bin.000001', MASTER_LOG_POS=100; # 指定从哪个binlog位置开始同步 -- 查看从库同步状态 SHOW SLAVE STATUS\G # 检查IO/SQL线程是否正常
三、环境准备
在回顾完相关基础知识后,接下来就是环境搭建,以重现问题现场。虚拟机、MySQL等安装方法不再赘述,此处仅重点讲解MySQL的一主一从高可用架构如何搭建。注:我的Linux环境为CentOS 6.8,MySQL使用版本为8.0.13。
1、服务器规划
主库(Master):192.168.1.200
从库(Slave):192.168.1.201
前提条件:
- 两台服务器均已安装相同版本的MySQL(建议MySQL 8.0+)
- 确保两台服务器网络互通,3306端口开放
- 确保主库已有数据处于稳定状态(若主库有重要数据,建议先备份)
2、主库(192.168.1.200)配置
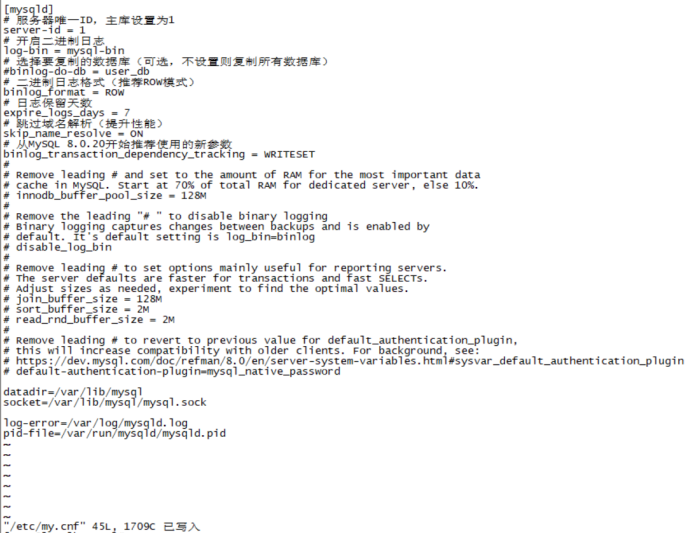
1. 修改MySQL配置文件 vim /etc/my.cnf 添加或修改以下配置: [mysqld] # 服务器唯一ID,主库设置为1 server-id = 1 # 开启二进制日志 log-bin = mysql-bin # 选择要复制的数据库(可选,不设置则复制所有数据库) binlog-do-db = your_database_name # 二进制日志格式(推荐ROW模式) binlog_format = ROW # 日志保留天数 expire_logs_days = 7 # 跳过域名解析(提升性能) skip_name_resolve = ON # 从MySQL 8.0.20开始推荐使用的新参数 binlog_transaction_dependency_tracking = WRITESET 保存后重启MySQL服务: service mysqld restart
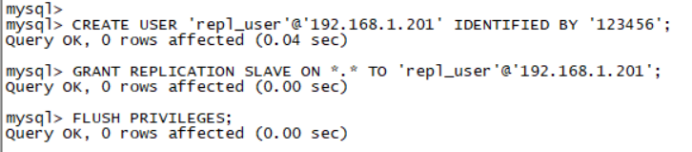
2. 创建复制专用用户 登录MySQL主库: mysql -u root -p 执行以下SQL创建复制用户并授权: -- 创建复制用户 CREATE USER 'repl_user'@'192.168.1.201' IDENTIFIED BY '123456'; -- 授予复制权限 GRANT REPLICATION SLAVE ON *.* TO 'repl_user'@'192.168.1.201'; -- 刷新权限 FLUSH PRIVILEGES;
3. 查看主库状态并记录关键信息
-- 记录输出结果中的File(如mysql-bin.000001)和Position(如154)值,从库配置时需要用到。
SHOW MASTER STATUS;
// 配置效果

2、从库(192.168.1.201)配置
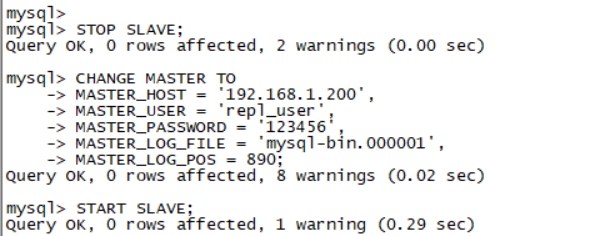
1. 修改MySQL配置文件 vim /etc/my.cnf 添加或修改以下配置: [mysqld] # 服务器唯一ID,必须与主库不同 server-id = 2 # 启用中继日志 relay-log = mysql-relay-bin # 将从库设置为只读模式(可选但推荐) read_only = ON # 如果从库可能成为其他从库的主库,则需开启 log-slave-updates = ON # 跳过域名解析 skip_name_resolve = ON 保存后重启MySQL服务: service mysqld restart 2. 配置主从复制关系 登录从库MySQL: mysql -u root -p 执行以下命令配置主库连接信息: -- 停止从库复制进程(如果是首次配置可忽略) STOP SLAVE; -- 配置主库信息 CHANGE MASTER TO MASTER_HOST = '192.168.1.200', MASTER_USER = 'repl_user', MASTER_PASSWORD = '123456', MASTER_LOG_FILE = 'mysql-bin.000001', -- 替换为主库SHOW MASTER STATUS的File值 MASTER_LOG_POS = 890; -- 替换为主库的Position值 -- 启动复制 START SLAVE;


3、验证主从复制状态
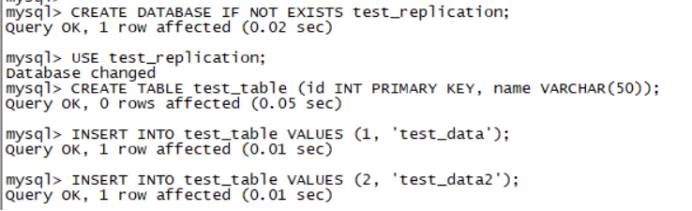
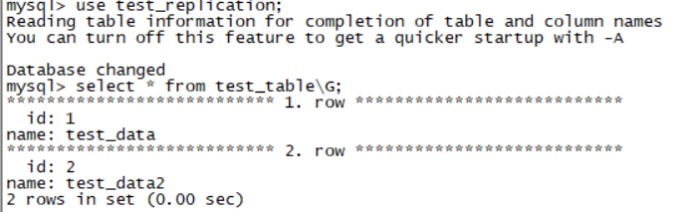
1. 检查从库复制状态 在从库上执行: SHOW SLAVE STATUS\G 重点关注以下两项: Slave_IO_Running: Yes Slave_SQL_Running: Yes 如果两者都为Yes,表示主从复制已正常启动。 2. 测试主从同步 在主库上执行: -- 创建测试数据库(如果未指定binlog-do-db) CREATE DATABASE IF NOT EXISTS test_replication; USE test_replication; CREATE TABLE test_table (id INT PRIMARY KEY, name VARCHAR(50)); INSERT INTO test_table VALUES (1, 'test_data'); 在从库上验证: SELECT * FROM test_replication.test_table; # 能看到主库插入的数据,则代表主从同步正常
四、问题复盘
接下来,就可以进行问题复现、分析和解决了。
1、问题复现
(1)先在从库执行删除操作


注:此时从库的复制状态查看还是正常的。
(2)接着在主库执行删除操作
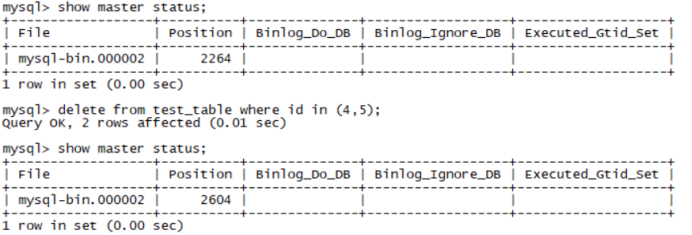
(3)再次查看从库状态,发现出现了错误
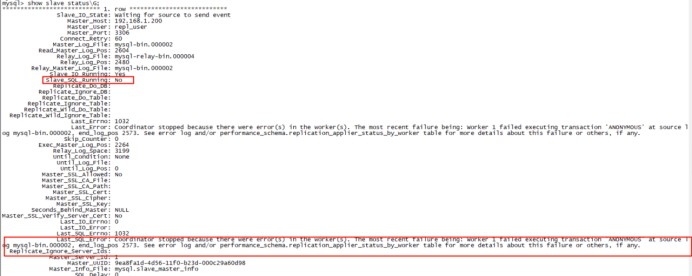
注:错误信息为
“Coordinator stopped because there were error(s) in the worker(s). The most recent failure being: Worker 1 failed executing transaction 'ANONYMOUS' at source log mysql-bin.000002, end_log_pos 2573. See error log and/or performance_schema.replication_applier_status_by_worker table for more details about this failure or others, if any”
2、原因分析
(1)先执行该语句查看工作线程详细的错误信息(这将显示每个工作线程的具体错误,通常会包含更详细的错误描述,如"Duplicate entry"(主键冲突)或"Can't find record"(记录不存在))
SELECT * FROM performance_schema.replication_applier_status_by_worker\G;

(2)然后根据错误日志中的binlog位置(mysql-bin.000002, pos 2573),解析主库的binlog查看具体操作
mysqlbinlog --no-defaults -v --base64-output=DECODE-ROWS /var/lib/mysql/mysql-bin.000002 | grep -A 20 "2573"
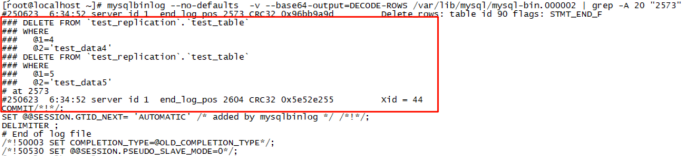
(3)由上述具体错误信息和对应binlog内容,可以确认错误原因:主库删除脚本对应的数据在从库找不到,所以导致从库在同步时发生异常。
3、解决方法
【方案一】最简单,允许少数据量不一致或可以确认无数据不一致(本次解决问题所采用的方案)
安全跳过错误事务(前提:因为主库也删除了该记录,所以从库也不需要这些记录,可以跳过,不会出现数据不一致) -- 在从库执行 STOP SLAVE; SET GLOBAL sql_slave_skip_counter = 1; -- 跳过1个事件(整个DELETE事务) START SLAVE; SHOW SLAVE STATUS\G -- 检查以下字段: -- Slave_IO_Running: Yes -- Slave_SQL_Running: Yes -- Last_Error: (应为空)

【方案二】明显两边数据不一致
(1)使用navicat等工具进行两边的数据库数据对比,然后手动执行数据同步功能,保证两边数据一致即可。
【方案三】数据量少的情况或严格要求数据强一致,可以采用“从库重建与重新同步”
(1)记录当下主库binlog文件名和位置;
(2)停止从库复制和彻底清除复制信息、删除所有数据库;
(3)使用mysqldump工具对主库进行全量备份;
(4)在从库对备份脚本进行恢复;
(5)重新设置从库主从复制信息(主库binlog文件名和位置);
(6)开启从库的复制并检查复制的状态是否正常。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号