SQL之视图存储过程自定义函数索引
2019-09-29 16:54 老九君 阅读(559) 评论(0) 收藏 举报1.什么是视图
视图是一个虚拟表,其内容由查询定义。
同真实的表一样,视图包含一系列带有名称的列和行数据。
行和列数据来自定义视图的查询所引用的表,并且在引用视图时动态生成。
简单的来说视图是由select结果组成的表;
2.视图的特性
视图是对若干张基本表的引用,一张虚表,查询语句执行的结果,
不存储具体的数据(基本表数据发生了改变,视图也会跟着改变);
可以跟基本表一样,进行增删改查操作(增删改操作有条件限制);
3.视图的作用
安全性
创建一个视图,定义好该视图所操作的数据。之后将用户权限与视图绑定
这样的方式是使用到了一个特性:grant语句可以针对视图进行授予权限。
查询性能提高。
提高了数据的独立性
4.创建视图
CREATE [ALGORITHM]={UNDEFINED|MERGE|TEMPTABLE}] VIEW 视图名 [(属性清单)] AS SELECT 语句 [WITH [CASCADED|LOCAL] CHECK OPTION];
ALGORITHM参数
merge 处理方式替换式,可以进行更新真实表中的数据;
TEMPTABLE 具化式,由于数据存储在临时表中,所以不可以进行更新操作!
UNDEFINED 没有定义ALGORITHM参数
mysql更倾向于选择替换方式。是因为它更加有效。
WITH CHECK OPTION
更新数据时不能插入或更新不符合视图限制条件的记录。
LOCAL和CASCADED
为可选参数,决定了检查测试的范围,默认值为CASCADED。
5.修改视图
CREATE OR REPLACE VIEW 视图名 AS SELECT [...] FROM [...];
6.删除视图
drop view 视图名称;
7.视图机制
替换式 操作视图时,视图名直接被视图定义给替换掉
具化式 mysql先得到了视图执行的结果,该结果形成一个中间结果暂时存在内存中。
外面的select语句就调用了这些中间结果(临时表)
替换式与具化式区别
替换方式,将视图公式替换后,当成一个整体sql进行处理了。
具体化方式,先处理视图结果,后处理外面的查询需求。
8.视图不可更新部分
聚合函数;
DISTINCT 关键字;
GROUP BY子句;
HAVING 子句;
UNION 运算符;
FROM 子句中包含多个表;
SELECT 语句中引用了不可更新视图;
只要视图当中的数据不是来自于基表,就不能够直接修改
一、什么是存储过程
一组可编程的函数,是为了完成特定功能的SQL语句集
经编译创建并保存在数据库中,用户可通过指定存储过程的名字并给定参数(需要时)来调用执行。
存储过程就是具有名字的一段代码,用来完成一个特定的功能。
创建的存储过程保存在数据库的数据字典中
二、为什么要用存储过程
将重复性很高的一些操作,封装到一个存储过程中,简化了对这些SQL的调用
批量处理
统一接口,确保数据的安全
相对于oracle数据库来说,MySQL的存储过程相对功能较弱,使用较少。
三、存储过程的创建和调用
DELIMITER $$
它与存储过程语法无关
DELIMITER语句将标准分隔符 - 分号(;)更改为:$$
因为我们想将存储过程作为整体传递给服务器
而不是让mysql工具一次解释每个语句
告诉mysql解释器,该段命令是否已经结束了,mysql是否可以执行了。默认情况下,delimiter是分号;。在命令行客户端中,如果有一行命令以分号结束,那么回车后,mysql将会执行该命令。但有时候,不希望MySQL这么做。在为可能输入较多的语句,且语句中包含有分号。使用delimiter $$,这样只有当$$出现之后,mysql解释器才会执行这段语句。
创建存储过程
CREATE PROCEDURE 名称()
BEGIN
语句
END $$
调用存储过程
call 名称();
四、删除存储过程
drop procedure 名称
五、存储过程变量
在存储过程中声明一个变量
使用DECLARE语句
1.DECLARE 变量名 数据类型(大小) DEFAULT 默认值;
2.可以声明一个名为total_sale的变量,数据类型为INT,默认值为0
DECLARE total_sale INT DEFAULT 0;
3.声明共享相同数据类型的两个或多个变量
DECLARE x, y INT DEFAULT 0;
分配变量值
要为变量分配一个值,可以使用SET语句
SET total_count = 10;
使用SELECT INTO语句将查询的结果分配给一个变量
SELECT COUNT(*) INTO total_products FROM products
变量的范围
如果在存储过程中声明一个变量,那么当达到存储过程的END语句时,它将超出范围,因此在其它代码块中无法访问
六、存储过程参数
三种类型
IN 表示调用者向过程传入值(传入值可以是字面量或变量)
OUT 表示过程向调用者传出值
INOUT INOUT参数是IN和OUT参数的组合。
定义参数
create produce name(模式,参数名称 数据类型(大小))
七、存储过程语句
IF语句
IF expression THEN
statements;
END IF;
IF expression THEN
statements;
ELSE
else-statements;
END IF;
CASE语句
CASE case_expression
WHEN when_expression_1 THEN commands
WHEN when_expression_2 THEN commands
...
ELSE commands
END CASE;
循环
WHILE expression DO
statements
END WHILE
REPEAT
statements;
UNTIL expression
END REPEAT
八.查看存储过程
查看所有存储过程 SHOW PROCEDURE STATUS;
查看指定数据库中的存储过程 SHOW PROCEDURE STATUS WHERE db = 'My_test4';
查看指定存储过程源代码 SHOW CREATE PROCEDURE 存储过程名
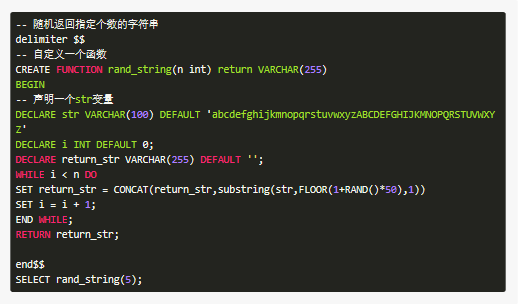
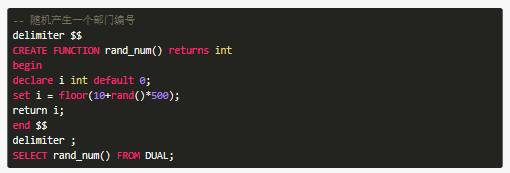
自定义函数
一、什么是索引
索引用于快速找出在某个列中有一特定值的行,
不使用索引,MySQL必须从第一条记录开始读完整个表,直到找出相关的行,
表越大,查询数据所花费的时间就越多,
如果表中查询的列有一个索引,MySQL能够快速到达一个位置去搜索数据文件,
而不必查看所有数据,那么将会节省很大一部分时间
二、索引的优势与劣势
优势
类似大学图书馆建书目索引,提高数据检索效率,降低数据库的IO成本。
通过索引对数据进行排序,降低数据排序的成本,降低了CPU的消耗。
劣势
实际上索引也是一张表,该表保存了主键与索引字段,并指向实体表的记录,所以索引列也是要占空间的。
虽然索引大大提高了查询速度,同时确会降低更新表的速度,如对表进行INSERT、UPDATE、DELETE。
三、索引的分类
单值索引,即一个索引只包含单个列,一个表可以有多个单列索引。
唯一索引,索引列的值必须唯一,但允许有空值。
复合索引,一个索引包含多个列。
INDEX MultiIdx(id,name,age)
全文索引,只有在MyISAM引擎上才能使用,只能在CHAR,VARCHAR,TEXT类型字段上使用全文索引
四、索引操作
创建索引
CREATE INDEX 索引名称 ON table (column[, column]...);
create INDEX salary_index ON emp(salary)
删除索引
DROP INDEX 索引名称 ON 表名
查看索引
show index from 表名;
Table 表名
Non_unique 如果索引不能包括重复词,则为0。如果可以,则为1。
Key_name 索引的名称
Seq_in_index 索引中的列序列号,从1开始。
Column_name 列名称。
Collation 列以什么方式存储在索引中。在MySQL中,有值‘A'(升序)或NULL(无分类)。
Cardinality 索引中唯一值的数目的估计值。
过运行ANALYZE TABLE或myisamchk -a可以更新。基数根据被存储为整数的统计数据来计数,所以即使对于小型表,该值也没有必要是精确的。基数越大,当进行联合时,MySQL使用该索引的机会就越大。
Sub_part 如果列只是被部分地编入索引,则为被编入索引的字符的数目。如果整列被编入索引,则为NULL。
Packed 指示关键字如何被压缩。如果没有被压缩,则为NULL。
Null 如果列含有NULL,则含有YES。如果没有,则该列含有NO。
Index_type 用过的索引方法(BTREE, FULLTEXT, HASH, RTREE)。
Comment 索引备注信息
自动创建索引
在表上定义了主键时, 会自动创建一个对应的唯一索引
在表上定义了一个外键时,会自动创建一个普通索引
五、EXPLAIN
用来查看索引是否正在被使用,并且输出其使用的索引的信息。
id:
SELECT识别符。这是SELECT的查询序列号,也就是一条语句中,该select是第几次出现。在次语句中,select就只有一个,所以是1.
select_type:
所使用的SELECT查询类型,SIMPLE表示为简单的SELECT,不实用UNION或子查询,就为简单的SELECT。
table:
数据表的名字。他们按被读取的先后顺序排列
type:
指定本数据表和其他数据表之间的关联关系,该表中所有符合检索值的记录都会被取出来和从上一个表中取出来的记录作联合。
key:
实际选用的索引
possible_keys:
MySQL在搜索数据记录时可以选用的各个索引,该表中就只有一个索引,year_publication
key_len:
显示了mysql使用索引的长度(也就是使用的索引个数),当 key 字段的值为 null时,索引的长度就是 null。注意,key_len的值可以告诉你在联合索引中mysql会真正使用了哪些索引。这里就使用了1个索引,所以为1,
ref:
给出关联关系中另一个数据表中数据列的名字。常量(const),这里使用的是1990,就是常量。
rows:
MySQL在执行这个查询时预计会从这个数据表里读出的数据行的个数。
extra:
提供了与关联操作有关的信息,没有则什么都不写。
六、索引结构
先会对数据进行排序
btree索引
B+树索引
B+树是一个平衡的多叉树,从根节点到每个叶子节点的高度差值不超过1,而且同层级的节点间有指针相互链接。
hash索引
哈希索引就是采用一定的哈希算法,把键值换算成新的哈希值,检索时不需要类似B+树那样从根节点到叶子节点逐级查找,只需一次哈希算法即可立刻定位到相应的位置,速度非常快。
hash 索引结构的特殊性,其检索效率非常高,索引的检索可以一次定位,不像B-Tree 索引需要从根节点到枝节点,最后才能访问到页节点这样多次的IO访问,所以 Hash 索引的查询效率要远高于 B-Tree 索引。
七、哪些情况需要创建索引
主键自动建立唯一索引
频繁作为查询条件的字段应该创建索引
查询中与其他表关联的字段,外键关系建立索引
频繁更新的字段不适合建立索引,因为每次更新不单单是更新了记录还会更新索引
WHERE条件里用不到的字段不创建索引
查询中排序的字段,排序的字段若通过索引去访问将大大提高排序速度
查询中统计或者分组字段
八、哪些情况不需要创建索引
表记录太少
经常增删改的表
如果某个数据列包含许多重复的内容,为它建立索引就没有太大的实际效果
老九学堂会员社群出品

 浙公网安备 33010602011771号
浙公网安备 33010602011771号