移动语义和完美转发浅析
移动语义和完美转发浅析
移动语义基础
为什么要引入移动语义?
vector<int> v1{1, 2, 3, 4, 5};
vector<int> v2;
v2 = v1;
在移动语义出现前,我们拷贝一个 vector 对象,逻辑上可以分为两步:
- 在堆上分配一块空间
- 将 v1 的元素逐个拷贝到 v2 中
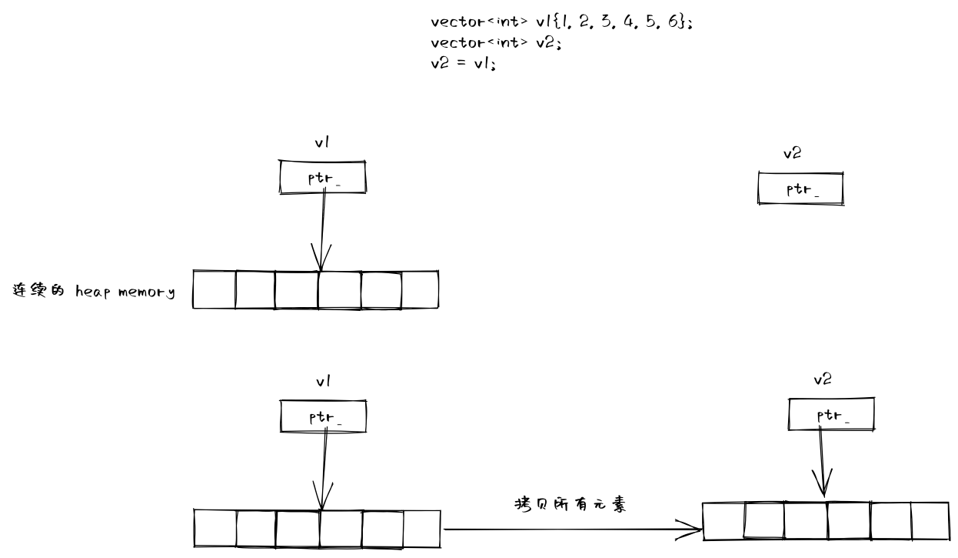
这种行为是完全正确,没有问题的,但如果 v1 是作为函数的返回值呢?
vector<int> createVector() {
vector<int> v1{1, 2, 3, 4, 5};
return v1;
}
vector<int> v2;
v2 = createVector();
在这种情况下,这种拷贝是否多余?函数返回后,v1 就要被析构掉了,它堆上的空间却没法为 v2 所复用,显然这里是有优化空间的。
有移动语义后,这种场景下,移动操作的做法是通过指针操作直接将 v1 的堆上空间移交给 v2,从而实现 v1 堆上空间的复用。
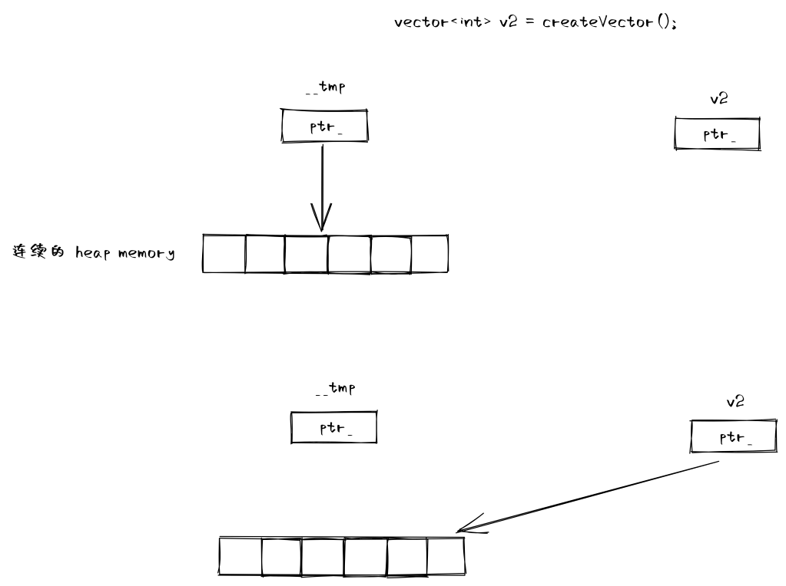
综上所述,移动语义允许我们以一种更轻量级的(相较于拷贝)形式实现对象资源的复用。
什么是移动语义?
从上面的例子可以看出,事实上移动操作移动的并不是对象,移动结束后,v1 仍然存在于 createVector() 的栈上,它并没有被 “移动” 到调用者的栈上去(可以和 NRVO 优化做比较),被移动的是堆上的空间,也就是 v1 所持有的资源。因此,移动语义移动的是对象所持有的资源,而不是对象本身。
如果你有看过 unique_ptr 和 auto_ptr 的实现,就会发现用拷贝去模拟资源的移交是非常困难的,auto_ptr 正是标准库在这方面的失败尝试,而 unique_ptr 改为用移动操作去模拟资源移交,实现的就比较正确和优雅。
什么样的对象是可以被移动的?
了解了移动语义的基本概念,那么摆在我们面前的一个问题就是:什么样的对象是可以被移动的?总的来说,一个对象要被移动,要满足如下要求:
- 该对象将要被销毁;
- 该对象没有任何用户;
- 可以自由接管该对象所持有的资源
为了表达这种概念,C++ 修改了左值和右值的定义,在 C 语言中,左值和右值即字面意思,左值是表达式左边的值,而右值是表达式右边的值。而 C++ 为了支撑移动语义,对值的类型做了新的划分。
区分左值和右值
C++ 中值有两个独立的属性:
- 有身份(has identity)
- 或者说,有地址,有指向它的指针
- 有身份的值统称为 glvalue ("generalized" lvalue)
- 可以被移动(can be moved from)
- 可以移动的值统称为 rvalue
glvalue 和 rvalue 就是我们一般说的左值和右值。
根据是否有这两种属性,我们可以对 C++ 中的值做如下划分(i 表示有身份,m 表示可以被移动,大写字母表示没有这种属性,第四种类型 IM 在 C++中没有被使用):
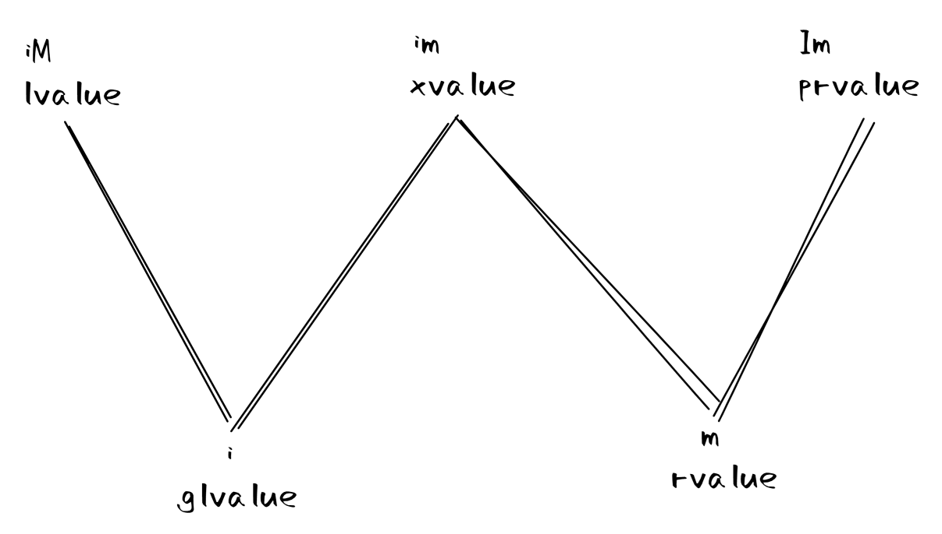
- lvalue( iM )
- 有身份,且不能被移动
- 包括
- 变量、函数或数据成员的名字
- 返回左值引用的表达式,比如
++x、x = 1 - 字符串字面量,如
"hello world"
- prvalue("pure" rvalue, Im)
- 一般译作纯右值
- 没有身份,可以被移动,也就是所谓的“临时对象”
- 包括
- 返回非引用类型的表达式,比如
x++、x + 1 - 除字符串字面量之外的字面量,比如
42、true
- 返回非引用类型的表达式,比如
- 有趣的是 this 指针是 prvalue,你会发现没法对 this 指针求地址
- xvalue(an "eXpiring" value, im)
- 一般译作将亡值
- 有身份,且可以被移动
- 包括
- 右值引用类型的返回值,比如
std::move(x)
- 右值引用类型的返回值,比如
虽然说,C++ 对值做了很细粒度的划分,但事实上,大多数时候只需要区分一个值是左值还是右值即可,因此,这里给出一个实践上可以用来区分左右值的法则:
- 如果你可以对某个表达式取地址,那么它是左值
- 如果一个表达式的类型是左值引用( T& 或 const T& 等),那么它是左值
- 否则,这个表达式是右值
- 函数的返回值(非引用类型的或右值引用类型的)
- 通过隐式类型转换创建的值
- 除字符串以外的字面量(比如 10 和 5.3)
我们来看一些例子,看看如何实践上述的法则以区分左值右值:
Widget&& var1 = someWidget;
auto&& var2 = var1;
可以对 var1 取地址,所以 var1 是左值,这点其实比较反直觉,虽然 var1 是右值引用,但其实它是左值。
std::vector<int> v;
auto&& val = v[0];
由于v[0]是左值引用,因此它是左值。
template<typename T>
void f(T&& param);
f(10);
非字符串字面量 10 是右值。
右值引用
伴随着新的右值定义,C++11 也引入了一种新的引用类型——右值引用,比如 int &&,右值引用的特点是它只能绑定到右值上,因此 C++11 中也就有了三种引用类型:
- 右值引用只能绑定到右值上,比如
int && - 非 const 的左值引用只能绑定到左值上,比如
int & - const 的左值引用可以绑定到左值或右值上,比如
const int &
新的特殊成员函数
为了支持移动语义,C++11 引用两个新的特殊成员函数,它们是移动构造函数和移动赋值运算符,想要支持移动操作的类必须定义它们。
class Widget {
private:
int i{0};
string s{};
unique_ptr<int> pi{};
public:
// Move constructor
Widget(Widget &&w) = default;
// Move assignment operator
Widget &operator=(Widget &&w) = default;
};
移动构造函数
移动构造函数的任务
- 完成资源移动
- 资源的所有权移交给新创建的对象
- 确保移动操作完成后,销毁源对象是无害的
- 不再指向被移动的资源
- 确保移动操作完成后,源对象依然是有效的
- 可以赋予它一个新值
- 对留下的值没有任何要求
也就是说移动操作完成后,可以销毁移后源对象,也可以赋予它一个新值,但不能使用移后源对象的值。
移动操作和异常安全
- 移动操作一般不分配新资源,因此不会抛出异常
- 如果移动操作不抛异常,必须注明
noexcept
如果你的移动操作不注明 noexcept ,标准库就不敢调用你的移动构造函数,这是由于标准库的某些接口会做出异常安全的保障,比如 vector 的 push_back 接口做出的保证为:
If an exception is thrown (which can be due to Allocator::allocate() or element copy/move constructor/assignment), this function has no effect (strong exception guarantee).
也就是说有异常抛出时(可能是由于内存分配或元素拷贝/移动),这个调用不产生任何效果。
push_back 可能会导致 vector 扩容,也就是说会申请一块新的内存空间,将现有的元素拷贝/移动到这块新的空间里。
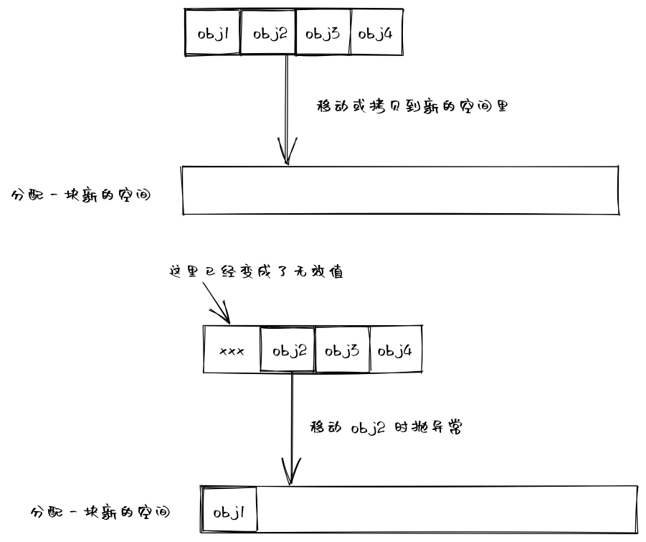
如果我们的移动构造函数会抛异常,假设扩容的过程中,只有部分元素被移动到了新的空间里,这时候有异常抛出,不仅扩容操作没完成,而且原有空间里的部分元素还被已执行的移动操作破坏掉了,不符合 push_back 做出的异常保障。因此,这种情况下,vector 只会使用拷贝操作来完成扩容操作。
移动操作和函数匹配
- 移动右值,拷贝左值
- 移动构造函数只能用于实参是右值的情况下,其他情况下,都会发生拷贝
- 但如果没有移动构造函数,则右值也被拷贝
- 拷贝构造函数的参数是 const 的左值引用,既能接受左值也能接受右值
移动赋值运算符
定义移动赋值运算符最简单的方法就是定义一个“拷贝并交换”的拷贝赋值运算符(如果你在疑惑该怎样自定义 swap 操作,请看 Effective C++ Item 25):
ClassA& ClassA::operator=(ClassA rhs)
{
swap(*this, rhs);
return *this;
}
“拷贝并交换”赋值运算符的参数不再是引用,而是传值
- rhs 将是右侧运算对象的一个副本;
- 将
*this与这个副本交换,也就是将右侧运算对象的值赋给了左侧运算对象; - 函数返回时,rhs 被销毁,析构函数销毁 rhs 现在指向的内存,即左侧运算对象原来的内存。
“拷贝并交换”的优势是正确处理了自赋值而且是异常安全的。
赋值运算符的异常安全问题主要来自于拷贝时可能申请内存,如果 new 抛异常了,要确保左侧运算对象原本的数据结构还没有被破坏(显然, rhs 做拷贝的时候,左侧运算对象原有数据结构还没有做任何修改)。
如果你定义了移动构造函数,那么这个拷贝赋值运算符同时也是移动赋值运算符:
- 如果实参是右值,就会用移动构造函数来初始化 rhs;
- 相反,如果实参是左值,就会用拷贝构造函数来初始化 rhs
何时该定义移动构造/赋值
the rule of zero
C.20: If you can avoid defining default operations, do
也就是说,如果默认行为够用,就不要再去定义自己的特殊成员函数。
struct Named_map {
public:
// ... no default operations declared ...
private:
string name;
map<int, int> rep;
};
Named_map nm; // default construct
Named_map nm2 {nm}; // copy construct
map 和 string 定义了所有的特殊成员函数,编译器生成的默认实现就已经够用了。
the rule of five
C.21: If you define or =delete any copy, move, or destructor function, define or =delete them all
如果定义拷贝、移动或析构中的任意一个,或将任意一个声明为 =delete 的;那么就需要将它们都定义出来或全部声明为 =delete 的。
实践 the rule of five 时,最简单的判断方法就是看析构函数,如果你析构函数里要做事,不管是释放资源还是关闭数据库连接,那么你就应该把析构函数的这些好兄弟都定义出来。
定义这些特殊成员时,如果你想要默认实现,就将它声明为 =default;如果你想要禁用某个特殊成员,就将它声明为 =delete(这两种情况都被编译器认为是用户定义的)。
the rule of five 背后的逻辑是这些特殊成员函数的语义是息息相关的:
- 规则 1:如果某个类有自定义拷贝构造函数、拷贝赋值运算符或者析构函数,编译器就不会为它合成移动构造函数和移动赋值运算符了
- 根据函数匹配规则,这种情况下会调用拷贝操作来处理右值
- 规则 2:如果某个类定义了移动构造函数,没有定义拷贝构造函数,那么后者被编译器定义为删除的(对于赋值运算符也是一样的)
如果定义了这些操作中的某一个,就应该把其他的操作都定义出来,以避免所有(潜在的)可移动的场景都变成昂贵的拷贝(对应规则 1)或者使得类型变成仅能移动的(对应规则 2)。
struct M2 { // bad: incomplete set of copy/move/destructor operations
public:
// ...
// ... no copy or move operations ...
~M2() { delete[] rep; }
private:
pair<int, int>* rep; // zero-terminated set of pairs
};
void use()
{
M2 x;
M2 y;
// ...
x = y; // the default assignment
// ...
}
这段代码没能遵循 the rule of five,造成的后果是 rep 被 double free。
std::move 和 std::forward
本章的内容涉及通用引用,可以看我的博客通用引用,里面有这方面的介绍。
虽然这两个函数的名字很有迷惑性,但事实上,从它们所做的事情上来看:move 不移动;forward 不转发,它们只是执行了类型转换操作罢了:
- std::move 无条件地将实参转换为右值;
- std::forward 在部分条件下将实参转换为右值
熟悉 C++ 类型转换的朋友应该知道 static_cast 事实上在运行时什么也不做,因此这俩函数也并不会在运行时做什么事情。
std::move
一个简化的 move 实现是这样的:
template <typename T> typename remove_reference<T>::type &&move(T &¶m) {
using ReturnType = typename remove_reference<T>::type &&;
return static_cast<ReturnType>(param);
}
T&& 是通用引用,因此这个函数几乎可以接收任何类型的参数。
通过 remove_reference 去掉 T 的引用性质(并不会去掉 cv 限定符),然后给它加上 &&,形成 ReturnType 类型,由于右值引用类型的返回值是右值,因此结果是实参被无条件地转换为右值。
为什么要使用 std::move?
既然 std::move 只是无条件地做 static_cast,那为什么不直接做类型转换,而要调用 std::move 呢?
std::move 允许我们截断左值,也就是说不再使用该左值,可以自由移动它所拥有的资源;这是非常特殊的类型操作,通过使用 std::move 方便我们确定在哪里对左值做了截断,语义上更加清晰。
使用 std::move 并不代表移动操作一定会发生
- 可能这个类型根本没有定义移动操作
- std::move 并不会去除实参的 const 性质,因此把 const 的对象传给它,得到的返回值类型也是 const 的,对它的操作会变为拷贝操作
- 因为移动操作往往会修改源对象,所以我们不希望在 const 对象上触发移动操作
std::forward 和完美转发
某些函数需要将其一个或多个实参连同类型不变地转发给其他函数,转发后需要保持被转发实参的所有性质,包括
- 实参是否是 const 的;
- 实参是左值还是右值
这种场景我们往往称之为完美转发,C++11 可以通过 std::forward 来实现。
比如工厂函数需要将初始化参数传递给构造函数。一个常见的例子就是 make_unique C++14 才支持,如果我们想自己写一个 make_unique 应该怎么写呢?
template <typename T, typename... Ts>
std::unique_ptr<T> make_unique(Ts &&... params) {
return std::unique_ptr<T>(new T(std::forward<Ts>(params)...));
}
std::forward 的实现
template< class T >
T&& forward( typename std::remove_reference<T>::type& t ) noexcept {
return static_cast<T&&>(param);
}
template< class T >
T&& forward( typename std::remove_reference<T>::type&& t ) noexcept {
return static_cast<T&&>(param);
}
std::forward 的模板参数是没法推导的,称为无法推导的上下文(nondeduced context)。
理解这个实现的重点在于它的返回值类型是 T&&,我们看一个例子:
void g(int &&i, int& j);
template <typename F, typename T1, typename T2>
void flip3(F f, T1 &&t1, T2 &&t2)
{
f(std::forward<T2>(t2), std::forward<T1>(t1));
}
flip3(g, i, 42);
flip3 接受一个可调用对象,以及两个额外实参,将参数逆序传递给可调用对象。
- 如果实参是 int 变量 i
- T1 的类型为
int&,std::forward 的返回类型为int& &&,根据引用折叠,结果是int& - t1 的类型为
int& - 参数的类型和返回值的类型相同,所以转换不会做任何事
- T1 的类型为
- 而如果实参是 42
- T2 的类型为
int,std::forward 的返回类型是int && - t2 的类型为
int && - 从函数返回的右值引用是右值,所以 t2 会被转换为右值
- T2 的类型为
就此,我们也理解了为什么说 forward 是有条件地将实参转换为右值。
怎么判断该用 move 还是 forward?
- 对右值引用 move
- 右值引用只能绑定到右值上,所以可以无条件地将它转换为右值
- 对通用引用 forward
- 通用引用既能绑定到左值上,也能绑定到右值上,在后一种情况下,我们希望能将它转换为右值
在右值引用上调用 std::forward 表现出的行为是正确的,但由于 std::forward 没法自动做类型推导,写出来的代码会比较繁琐;但如果在通用引用上调用 std::move,可能会导致左值被错误地修改,导致异常的行为。
什么时候用 move 和 forward?
你可能需要在函数中多次使用某个右值引用或通用引用,那么只有在最后一次使用它的时候,才可以对它调 std::move 或 std::forward,因为将它转为右值后,它的内容就不能再被使用了。
void sink(X&& x); // sink takes ownership of x
void user()
{
X x;
// error: cannot bind an lvalue to a rvalue reference
sink(x);
// OK: sink takes the contents of x, x must now be assumed to be empty
sink(std::move(x));
// ...
// probably a mistake
use(x);
}
名字查找和 move、forward
std::move 和 std::forward 的形参都是通用引用,它们几乎可以匹配任何类型的参数。
因此如果我们定义了自己的 move 或 forward 函数,如果它接受单一形参,不管类型如何,都将与标准库的版本冲突。
同时,move 和 forward 执行的是非常特殊的类型操作,用户特意去修改函数原有行为的概率非常小,因此最好使用带限定语的版本 std::move 和 std::forward 来明确指出使用标准库的版本。
移动和返回值优化
RVO
如果 return 语句的操作数是 prvalue ,且它和返回值的类型相同。
T f() {
return T();
}
f(); // only one call to default constructor of T
此时,编译器可以实施 copy elision(拷贝省略、拷贝消除),将对象直接构造到调用者的栈上去。
return 语句所在的地方,T 的析构函数必须是可访问的且没有被删除,尽管此处并没有 T 对象被析构掉。
C++17 强制编译器做 RVO,RVO 不再是一项可选的编译器优化,而是 C++ 对 prvalue 的新规定,即返回和使用 prvalue 时不再去实体化一个临时对象
NRVO
X bar()
{
X xx;
// process xx ...
return xx;
}
对于上面的函数 bar,如果直接用参数 __result 代替命名的返回值 xx,即改写为:
void
bar( X &__result )
{
// default constructor invocation
// Pseudo C++ Code
__result.X::X();
// ... process in __result directly
return;
}
也就是说返回值会被直接构造在调用者的栈上,少了一次拷贝操作,这种优化被称为 Named Return Value Optimization(NRVO)。
移动和 NRVO
C++11 开始,NRVO 仍可以发生,但在没有 NRVO 的情况下,编译器将试图把本地对象移动出去,而不是拷贝出去。
这一移动行为不需要程序员手工用 std::move 进行干预,使用 std::move 对于移动行为没有帮助,反而会影响返回值优化,因为这种情况下,你返回的并不是局部对象,而是局部对象的引用。
参考资料
本文来自博客园,作者:路过的摸鱼侠,转载请注明原文链接:https://www.cnblogs.com/ljx-null/p/16512384.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号