Sentinel流控规则简介
1、基本介绍
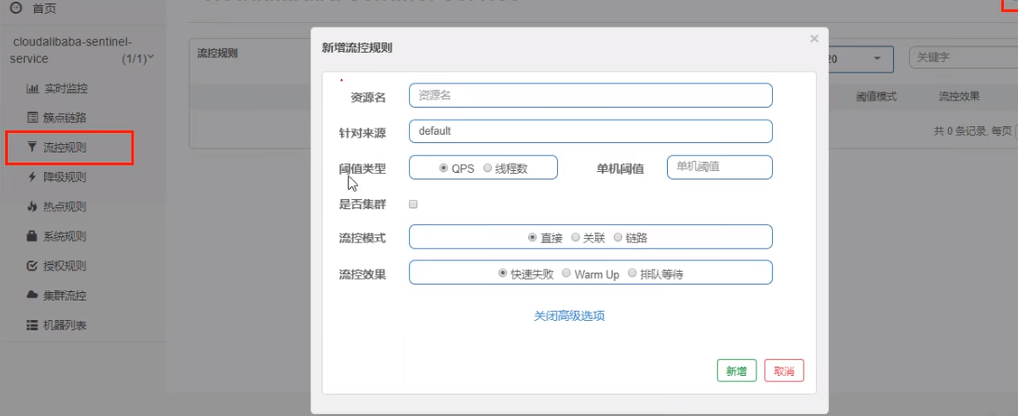
进一步解释说明:
- 资源名:唯一名称,默认请求路径。
- 针对来源:Sentinel可以针对调用者进行限流,填写微服务名,默认default(不区分来源)。
- 阈值类型/单机阈值:
(1)QPS(每秒钟的请求数量)︰当调用该API的QPS达到阈值的时候,进行限流。
(2)线程数:当调用该API的线程数达到阈值的时候,进行限流。
- 是否集群:不需要集群。
- 流控模式:
(1)直接:API达到限流条件时,直接限流。
(2)关联:当关联的资源达到阈值时,就限流自己。
(3)链路:只记录指定链路上的流量(指定资源从入口资源进来的流量,如果达到阈值,就进行限流)【API级别的针对来源】。
- 流控效果:
(1)快速失败:直接失败,抛异常。
(2)Warm up:根据Code Factor(冷加载因子,默认3)的值,从阈值/codeFactor,经过预热时长,才达到设置的QPS阈值。
(3)排队等待:匀速排队,让请求以匀速的速度通过,阈值类型必须设置为QPS,否则无效。
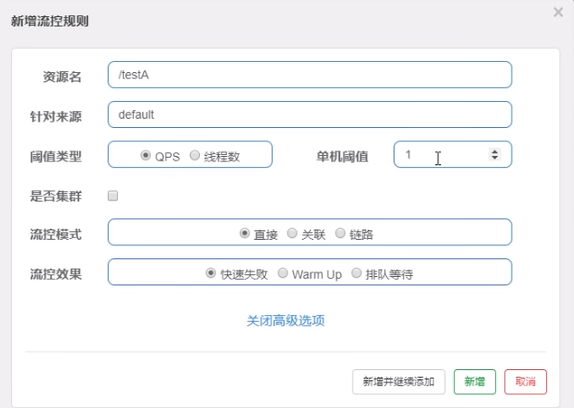
2、Sentinel流控-QPS直接失败
直接 -> 快速失败(系统默认)
配置及说明
表示1秒钟内查询1次就是OK,若超过次数1,就直接->快速失败,报默认错误
测试
快速多次点击访问http://localhost:8401/testA
结果
返回页面 Blocked by Sentinel (flow limiting)
源码
com.alibaba.csp.sentinel.slots.block.flow.controller.DefaultController
思考
直接调用默认报错信息,技术方面OK,但是,是否应该有我们自己的后续处理?类似有个fallback的兜底方法?
3、Sentinel流控-线程数直接失败
线程数:当调用该API的线程数达到阈值的时候,进行限流。
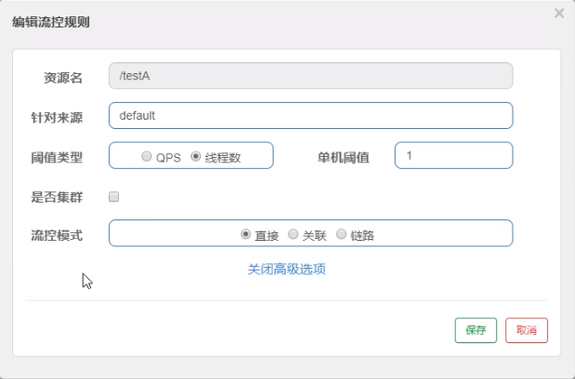
4、Sentinel流控-关联
是什么?
-
当自己关联的资源达到阈值时,就限流自己
-
当与A关联的资源B达到阀值后,就限流A自己(B惹事,A挂了)
设置testA
当关联资源/testB的QPS阀值超过1时,就限流/testA的Rest访问地址,当关联资源到阈值后限制配置好的资源名。
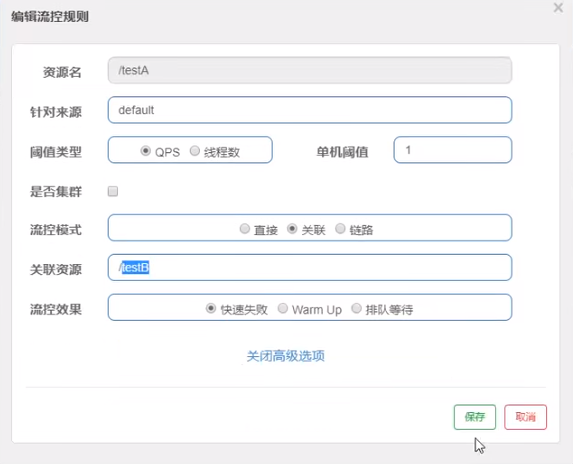
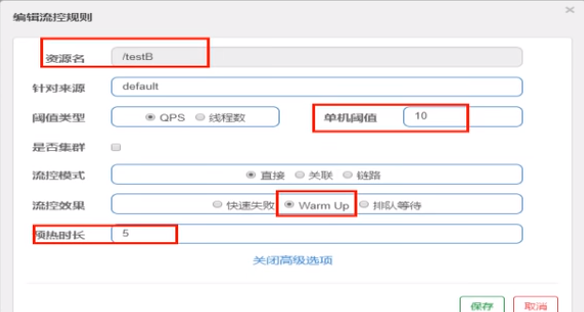
5、Sentinel流控-预热
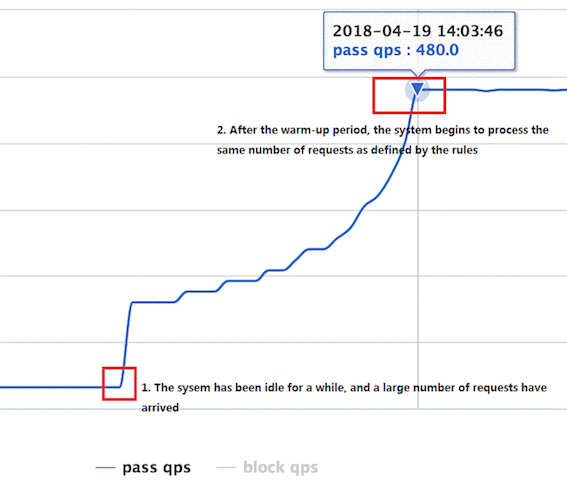
默认coldFactor为3,即请求QPS 从 threshold / 3开始,经预热时长逐渐升至设定的QPS阈值。
WarmUp配置
案例,阀值为10+预热时长设置5秒。
系统初始化的阀值为10/ 3约等于3,即阀值刚开始为3;然后过了5秒后阀值才慢慢升高恢复到10
测试
多次快速点击http://localhost:8401/testB - 刚开始不行,后续慢慢OK
应用场景
如:秒杀系统在开启的瞬间,会有很多流量上来,很有可能把系统打死,预热方式就是把为了保护系统,可慢慢的把流量放进来,慢慢的把阀值增长到设置的阀值。
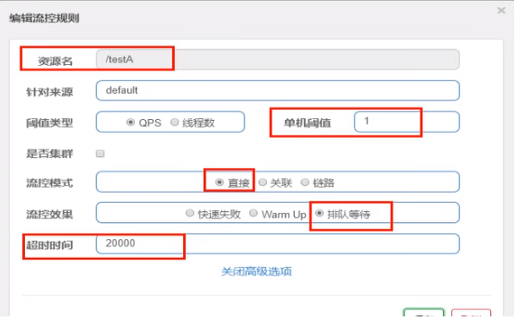
6、Sentinel流控-排队等待
匀速排队,让请求以均匀的速度通过,阀值类型必须设成QPS,否则无效。
设置:/testA每秒1次请求,超过的话就排队等待,等待的超时时间为20000毫秒。
匀速排队
匀速排队(RuleConstant.CONTROL_BEHAVIOR_RATE_LIMITER)方式会严格控制请求通过的间隔时间,也即是让请求以均匀的速度通过,对应的是漏桶算法。详细文档可以参考 流量控制 - 匀速器模式,具体的例子可以参见 PaceFlowDemo。
该方式的作用如下图所示:
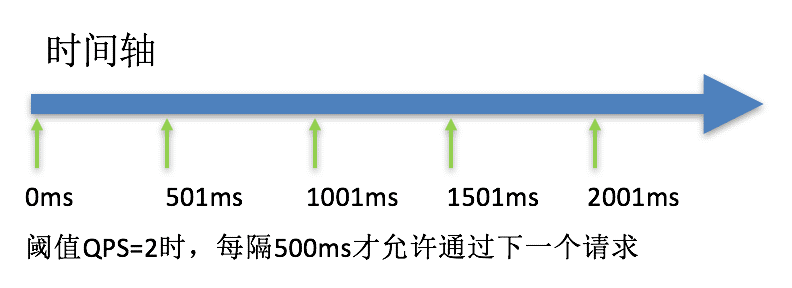
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
这种方式主要用于处理间隔性突发的流量,例如消息队列。想象一下这样的场景,在某一秒有大量的请求到来,而接下来的几秒则处于空闲状态,我们希望系统能够在接下来的空闲期间逐渐处理这些请求,而不是在第一秒直接拒绝多余的请求。
注意:匀速排队模式暂时不支持 QPS > 1000 的场景。
测试
添加日志记录代码到FlowLimitController的testA方法
@RestController
@Slf4j
public class FlowLimitController {
@GetMapping("/testA")
public String testA()
{
log.info(Thread.currentThread().getName()+"\t"+"...testA");//<----
return "------testA";
}
...
}
Postman模拟并发密集访问testA。具体操作参考117_Sentinel流控-关联
7、Sentinel降级简介
熔断降级概述
除了流量控制以外,对调用链路中不稳定的资源进行熔断降级也是保障高可用的重要措施之一。一个服务常常会调用别的模块,可能是另外的一个远程服务、数据库,或者第三方 API 等。例如,支付的时候,可能需要远程调用银联提供的 API;查询某个商品的价格,可能需要进行数据库查询。然而,这个被依赖服务的稳定性是不能保证的。如果依赖的服务出现了不稳定的情况,请求的响应时间变长,那么调用服务的方法的响应时间也会变长,线程会产生堆积,最终可能耗尽业务自身的线程池,服务本身也变得不可用。
现代微服务架构都是分布式的,由非常多的服务组成。不同服务之间相互调用,组成复杂的调用链路。以上的问题在链路调用中会产生放大的效果。复杂链路上的某一环不稳定,就可能会层层级联,最终导致整个链路都不可用。因此我们需要对不稳定的弱依赖服务调用进行熔断降级,暂时切断不稳定调用,避免局部不稳定因素导致整体的雪崩。熔断降级作为保护自身的手段,通常在客户端(调用端)进行配置。

- RT(平均响应时间,秒级)
- 平均响应时间 超出阈值 且 在时间窗口内通过的请求>=5,两个条件同时满足后触发降级。
- 窗口期过后关闭断路器。
- RT最大4900(更大的需要通过-Dcsp.sentinel.statistic.max.rt=XXXX才能生效)。
- 异常比列(秒级)
- QPS >= 5且异常比例(秒级统计)超过阈值时,触发降级;时间窗口结束后,关闭降级 。
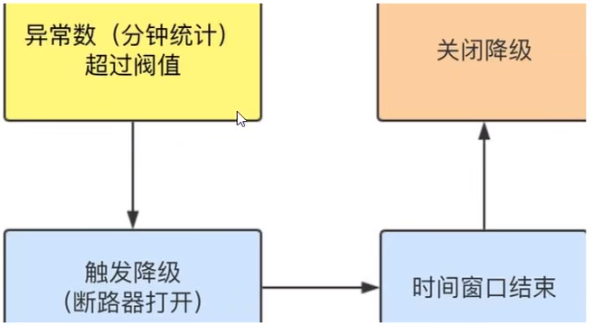
- 异常数(分钟级)
- 异常数(分钟统计)超过阈值时,触发降级;时间窗口结束后,关闭降级
Sentinel熔断降级会在调用链路中某个资源出现不稳定状态时(例如调用超时或异常比例升高),对这个资源的调用进行限制,让请求快速失败,避免影响到其它的资源而导致级联错误。
当资源被降级后,在接下来的降级时间窗口之内,对该资源的调用都自动熔断(默认行为是抛出 DegradeException)。
Sentinei的断路器是没有类似Hystrix半开状态的。(Sentinei 1.8.0 已有半开状态)
半开的状态系统自动去检测是否请求有异常,没有异常就关闭断路器恢复使用,有异常则继续打开断路器不可用。
8、Sentinel降级-RT
是什么?
平均响应时间(DEGRADE_GRADE_RT):当1s内持续进入5个请求,对应时刻的平均响应时间(秒级)均超过阈值( count,以ms为单位),那么在接下的时间窗口(DegradeRule中的timeWindow,以s为单位)之内,对这个方法的调用都会自动地熔断(抛出DegradeException )。注意Sentinel 默认统计的RT上限是4900 ms,超出此阈值的都会算作4900ms,若需要变更此上限可以通过启动配置项-Dcsp.sentinel.statistic.max.rt=xxx来配置。
注意:Sentinel 1.7.0才有平均响应时间(DEGRADE_GRADE_RT),Sentinel 1.8.0的没有这项,取而代之的是慢调用比例 (SLOW_REQUEST_RATIO)。
慢调用比例 (SLOW_REQUEST_RATIO):选择以慢调用比例作为阈值,需要设置允许的慢调用 RT(即最大的响应时间),请求的响应时间大于该值则统计为慢调用。当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且慢调用的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求响应时间小于设置的慢调用 RT 则结束熔断,若大于设置的慢调用 RT 则会再次被熔断。
接下来讲解Sentinel 1.7.0的。
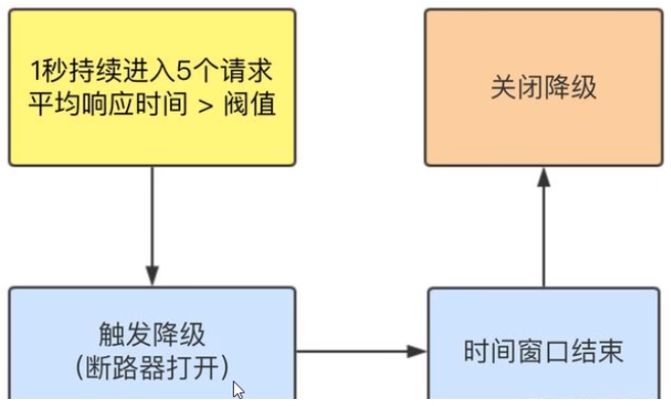
测试
代码
@RestController
@Slf4j
public class FlowLimitController {
...
@GetMapping("/testD")
public String testD() {
try {
TimeUnit.SECONDS.sleep(1);
} catch (InterruptedException e) {
e.printStackTrace();
}
log.info("testD 测试RT");
}
}
配置
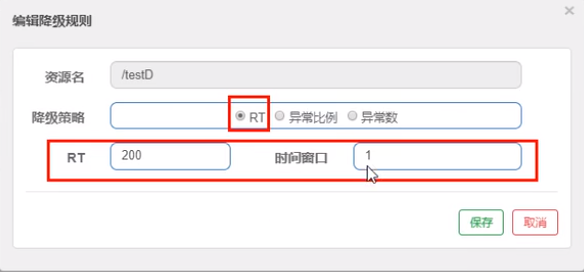
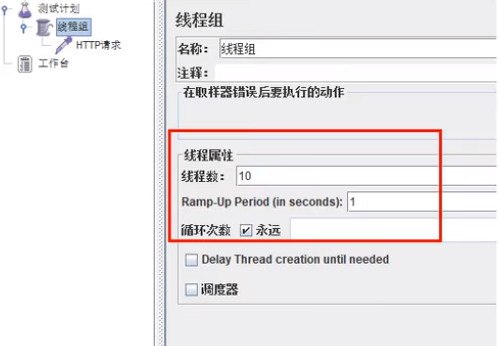
jmeter压测
结论
按照上述配置,永远一秒钟打进来10个线程(大于5个了)调用testD,我们希望200毫秒处理完本次任务,如果超过200毫秒还没处理完,在未来1秒钟的时间窗口内,断路器打开(保险丝跳闸)微服务不可用,保险丝跳闸断电了后续我停止jmeter,没有这么大的访问量了,断路器关闭(保险丝恢复),微服务恢复OK。
9、Sentinel降级-异常比例
是什么?
异常比例(DEGRADE_GRADE_EXCEPTION_RATIO):当资源的每秒请求量 >= 5,并且每秒异常总数占通过量的比值超过阈值( DegradeRule中的 count)之后,资源进入降级状态,即在接下的时间窗口( DegradeRule中的timeWindow,以s为单位)之内,对这个方法的调用都会自动地返回。异常比率的阈值范围是[0.0, 1.0],代表0% -100%
注意:与Sentinel 1.8.0相比,有些不同(Sentinel 1.8.0才有的半开状态),Sentinel 1.8.0的如下:
异常比例 (ERROR_RATIO):当单位统计时长(statIntervalMs)内请求数目大于设置的最小请求数目,并且异常的比例大于阈值,则接下来的熔断时长内请求会自动被熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。异常比率的阈值范围是 [0.0, 1.0],代表 0% - 100%。
接下来讲解Sentinel 1.7.0的。
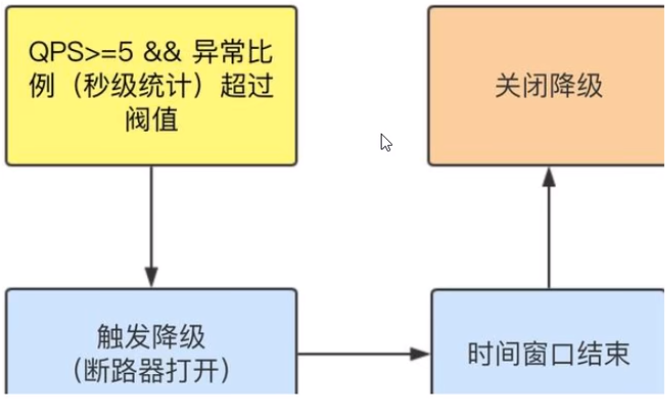
测试
代码
@RestController
@Slf4j
public class FlowLimitController {
...
@GetMapping("/testD")
public String testD() {
log.info("testD 异常比例");
int age = 10/0;
return "------testD";
}
}
配置

jmeter
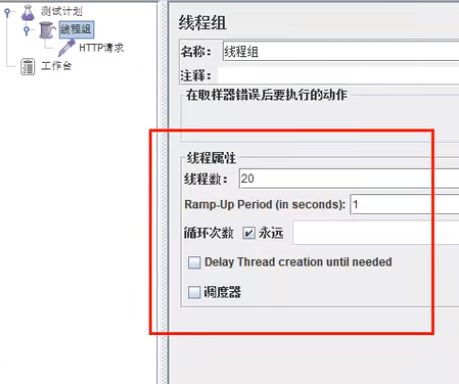
结论
按照上述配置,单独访问一次,必然来一次报错一次(int age = 10/0),调一次错一次。
开启jmeter后,直接高并发发送请求,多次调用达到我们的配置条件了。断路器开启(保险丝跳闸),微服务不可用了,不再报错error而是服务降级了。
10、Sentinel降级-异常数
是什么?
异常数( DEGRADE_GRADF_EXCEPTION_COUNT ):当资源近1分钟的异常数目超过阈值之后会进行熔断。注意由于统计时间窗口是分钟级别的,若timeWindow小于60s,则结束熔断状态后码可能再进入熔断状态。
注意:与Sentinel 1.8.0相比,有些不同(Sentinel 1.8.0才有的半开状态),Sentinel 1.8.0的如下:
异常数 (ERROR_COUNT):当单位统计时长内的异常数目超过阈值之后会自动进行熔断。经过熔断时长后熔断器会进入探测恢复状态(HALF-OPEN 状态),若接下来的一个请求成功完成(没有错误)则结束熔断,否则会再次被熔断。
接下来讲解Sentinel 1.7.0的。
异常数是按照分钟统计的,时间窗口一定要大于等于60秒。
测试
代码
@RestController
@Slf4j
public class FlowLimitController{
...
@GetMapping("/testE")
public String testE()
{
log.info("testE 测试异常数");
int age = 10/0;
return "------testE 测试异常数";
}
}
配置
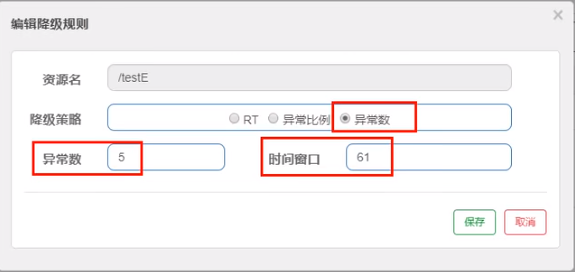
访问http://localhost:8401/testE,第一次访问绝对报错,因为除数不能为零,我们看到error窗口,但是达到5次报错后,进入熔断后降级。
原文链接:https://blog.csdn.net/u011863024/article/details/114298288

 浙公网安备 33010602011771号
浙公网安备 33010602011771号