
1.奖励函数的简要分析
Isaac gym的内置奖励函数
在Isaac gym中使用强化学习训练机械狗时,通常会使用一部分内置的奖励函数,在初始训练机器人行走的阶段,经常会复用内置开源的一些奖励函数,本文将是对内置的一些奖励函数的总结分析。
奖励函数大致可以分为两大类:
1.惩罚型的奖励函数
1.1.保持稳定性惩罚奖励函数
这类奖励函数主要的目的是为了为此机器人基本的稳定,或者运行正常等,避免机器人为获取较高的奖励值而学习到极端的动作。
1._reward_lin_vel_z
目标: 惩罚基座在垂直方向(Z轴)上的运动,使其保持平稳

最优取值: 0
通常给一个适中的负权重(如 -2.0)
2._reward_ang_vel_xy
惩罚基座在翻滚(Roll)和俯仰(Pitch)方向上的角速度,防止其晃动或摔倒。
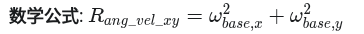
通常给一个较小的负权重(如 -0.05),因为角速度的数值本身可能很大
3._reward_orientation
惩罚基座偏离水平姿态,即保持背部朝天

通常给一个显著的负权重(如 -5.0)
4._reward_base_height
基座高度偏离目标高度
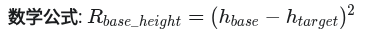
这个奖励的权重需要和地形的崎岖程度相匹配。
1.2安全约束型奖励函数
5._reward_collision
惩罚除了脚以外的身体部位(如小腿、大腿)发生碰撞

- 用于惩罚机器人与环境的不必要碰撞,通过检测特定身体部位的接触力来鼓励机器人避免与环境发生意外接触
- 监测 self.penalised_contact_indices 指定的身体部位(如躯干、手臂等非足部区域)的接触力,当接触力大于阈值(0.1 N)时,判定为碰撞并触发惩罚。
6._reward_dof_pos_limits
7._reward_dof_vel_limits
8._reward_torque_limits
9._reward_feet_contact_forces
1.3.风格化的惩罚性奖励函数(鼓励平滑,高效)
10._reward_torques
惩罚大的关节力矩,鼓励节能:

- 权重过高,会导致机器狗“懒惰”,动作绵软无力,无法完成动态任务。
- 权重过低,动作可能非常暴力、高能耗,对硬件不友好。
其权重是一个关键的平衡点,需要在性能和能耗之间做权衡。通常是一个很小的负值(如 -0.00001)
11._reward_dof_vel
惩罚过快的关节运动:
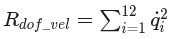
与 _reward_dof_acc 配合使用,调整动作的平滑度。
12._reward_dof_acc
惩罚剧烈的关节加速度,使力矩变化更平滑:

- 权重过高,机器狗的反应会变慢,因为它无法快速改变关节速度。
- 权重过低,动作可能非常“抖动”和“震颤”,力矩输出不平滑。
- 权重通常非常小(如 -2.5e-7)。
13._reward_action_rate
惩罚相邻时间步之间动作指令的剧烈变化:

高权重会使策略网络输出更平滑的动作序列,对于从仿真到真实的迁移(Sim-to-Real)有好处。
2. 任务型奖励函数(正回报奖励)
该奖励函数是鼓励机器人完成某些指定任务的关键部分,也是扩展定制化任务的部分。
14._reward_tracking_lin_vel
奖励机器狗跟随给定的线速度指令(X和Y轴):
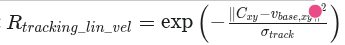
- 最优取值: 1 (当机器狗的线速度与指令完全一致时)。这是一个正向奖励
- tracking_sigma (公式中的σtrackσtrack控制了奖励的“容忍度”。
- sigma越大,即使有一定误差也能获得较高奖励;sigma越小,则要求非常精确的跟踪
15._reward_tracking_ang_vel
奖励机器狗跟随给定的偏航(Yaw)角速度指令:
![4ff6ef9c-315c-4a46-bcaa-be199065414a]()
- 最优取值: 1
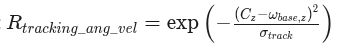
16._reward_feet_air_time
奖励足端在空中的停留时间

- 最优取值: 正值,具体大小取决于步态和速度
17._reward_stand_still
在没有移动指令时,惩罚关节的移动,鼓励其稳定站立:
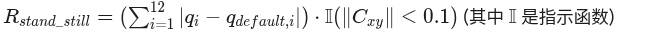
最优取值: 0
- 对于解决“原地抖动”问题非常有效。
- 如果机器狗在被命令站立时仍然晃动或漂移,可以增高此项的负权重。
总结,在初始导入自定义的机器人模型时,首先要确保惩罚性的奖励函数经过多轮训练后都趋近于0 ,如果差距过大,则需要更具机器人的实际效果来调节机器人的奖励函数系数。其次才是通过设计正向鼓励的奖励函数,引导机器人完成指定动作。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号