
mamba-硬件感知算法
扫描操作

提出原因
由于A B C这些矩阵现在是动态的了,因此无法使用卷积表示来计算它们(卷积核是固定的),因此,我们只能使用循环表示,如此也就而失去了卷积提供的并行训练能力。
-
计算顺序性:循环计算不能并行,效率低。每一步 ht 依赖 ht-1,无法像卷积那样并行
-
内存占用大:中间状态太多,存储压力大.要把所有中间状态 h_{1…L} 存下来做反向传播,显存 O(BLDN)
目标:把 顺序性 变成 可并行,把 O(BLDN) 变成 O(BLD) 甚至更低。
同时,我们也需要重新审视SSM的计算问题。我们用三种经典的技术来解决这个问题:核融合、并行扫描和重新计算。
通过这三个技术,让选择性状态空间模型既能动态适应输入,又能在 GPU 上高效运行,内存使用和 Transformer 差不多,但计算更快
并行扫描

虽然循环计算本质上是顺序的,但可以用并行扫描算法(如 Blelloch 算法)来并行化计算,提高效率。
Mamba通过并行扫描(parallel scan)算法使得最终并行化成为可能,其假设我们执行操作的顺序与关联属性无关。因此,我们可以分段计算序列并迭代地组合它们,即动态矩阵B和C以及并行扫描算法一起创建选择性扫描算法(selective scan algorithm)
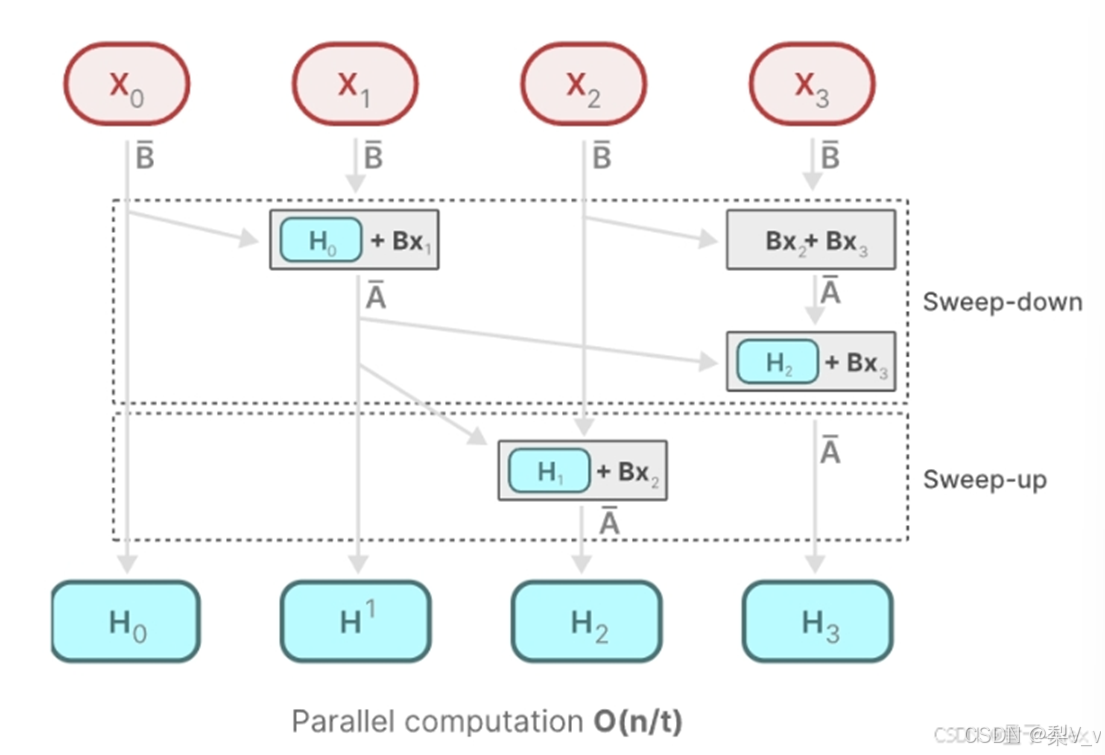
在并行计算中,时间复杂度 O(n/t) 中的 t ,通常代表用于执行任务的处理器或计算单元的数量
核融合
最新 GPU 的一个缺点是其小型但高效的 SRAM 与大型但效率稍低的 DRAM 之间的传输 (IO) 速度有限。在 SRAM 和 DRAM 之间频繁复制信息成为瓶颈。(transformer的方法)


主要思想是利用现代加速器(GPU)的特性,仅在内存层次结构的更高效层级上实现状态ℎ。具体来说,大多数运算(矩阵乘法除外)都受内存带宽限制。这包括我们的扫描运算,我们使用核融合来减少内存 IO 数量,与标准实现相比,显著提高了速度。(把多个计算步骤合并成一个 GPU 核函数,减少内存读写。)
具体来说,我们不会在 GPU HBM(高带宽存储器)中准备大小为 (B, L, D, N) 的扫描输入 (𝑨八, 𝑩八),而是将 SSM 参数 (Δ, 𝑨, 𝑩, 𝑪) 直接从慢速 HBM(主存) 加载到快速 SRAM(缓存),在 SRAM 中执行离散化和递归,然后将大小为 (B, L, D) 的最终输出写回 HBM。
为了避免顺序递归,我们观察到,尽管它不是线性的,仍然可以使用高效的并行扫描算法进行并行化。
最后,我们还必须避免保存反向传播所必需的中间状态。我们谨慎地运用了经典的重新计算技术来降低内存需求:中间状态不存储,而是在输入从 HBM 加载到 SRAM 时在反向传播中重新计算。因此,融合的选择性扫描层与使用 FlashAttention 优化的 Transformer 实现具有相同的内存需求。
重计算
这和 Transformer 中的 FlashAttention 技术类似,能显著降低内存使用
Flash Attention技术
利用内存的不同层级结构处理SSM的状态,减少高带宽但慢速的HBM内存反复读写这个瓶颈
具体而言,就是限制需要从 DRAM 到 SRAM 的次数(通过内核融合kernel fusion来实现),避免一有个结果便从SRAM写入到DRAM,而是待SRAM中有一批结果再集中写入DRAM中,从而降低来回读写的次数

 浙公网安备 33010602011771号
浙公网安备 33010602011771号