pandas 数据分组——聚合agg、转换 transform和应用apply
通过groupby分组数据之后,可以对每个分组的数据进行聚合运算、转换操作,或应用函数。
一,聚合操作
对拆分之后的数据进行聚合,对于DataFrame进行聚合操作,主要使用aggregate()函数,可以简写为agg():
DataFrameGroupBy.aggregate(func=None, *args, **kwargs)
参数注释:
- func:用于对分组中的数据进行聚合,有效值是函数、函数名称(func name)、函数名称的列表或dict。如果是dict,那么字典的Key是轴标签,通常是列名,字典的Value是函数,函数名称,或函数名称的列表。也可以传递元组列表,举个例子,[(axis label1, func1), (axis label2, func3),....]
- *args:传递给func的位置参数
- **kwargs:传递给func的关键字参数
1,例子1
为了演示,使用以下代码创建一个DataFrame对象df:
df = pd.DataFrame( { "A": [1, 1, 2, 2], "B": [1, 2, 3, 4], "C": [0.362838, 0.227877, 1.267767, -0.562860], } )
例子1,按照A列进行分组,求出其余列的最小值:
df.groupby('A').agg('min') B C A 1 1 0.227877 2 3 -0.562860
例子2,按照A列进行分组,求出其余列的最大值和最小值:
df.groupby('A').agg(['min', 'max']) B C min max min max A 1 1 2 0.227877 0.362838 2 3 4 -0.562860 1.267767
例子3,按照A列进行分组,求出B列的最大值和最小值:
df.groupby('A').B.agg(['min', 'max']) min max A 1 1 2 2 3 4
例子4,传递字典结构,
df.groupby('A').agg({'B': ['min', 'max'], 'C': 'sum'}) B C min max sum A 1 1 2 0.590715 2 3 4 0.704907
2,例子2
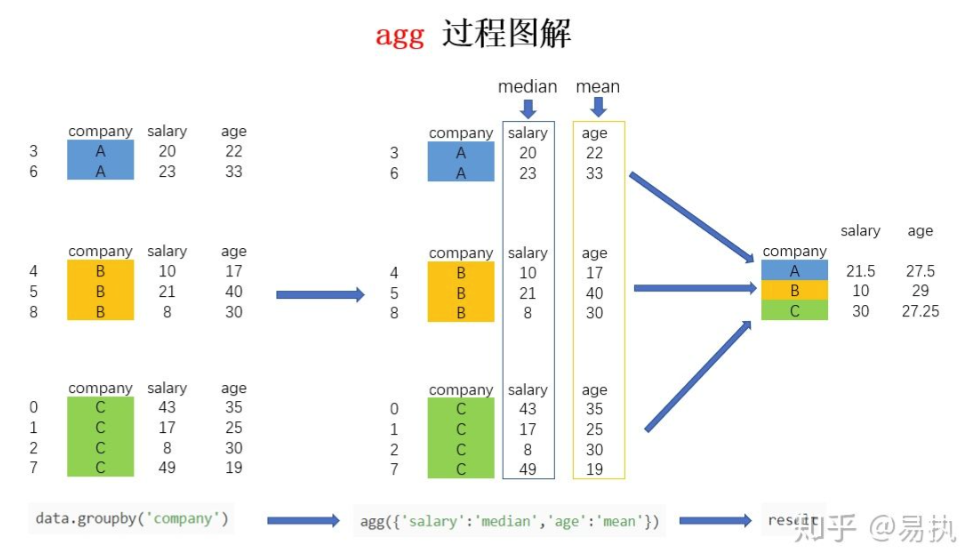
如果我想求不同公司员工的平均年龄和平均薪水,可以按照下方的代码进行:
In [12]: data.groupby("company").agg('mean') Out[12]: salary age company A 21.50 27.50 B 13.00 29.00 C 29.25 27.25
如果想对针对不同的列求不同的值,比如要计算不同公司员工的平均年龄以及薪水的中位数,可以利用字典进行聚合操作的指定:
In [17]: data.groupby('company').agg({'salary':'median','age':'mean'}) Out[17]: salary age company A 21.5 27.50 B 10.0 29.00 C 30.0 27.25
agg聚合过程可以图解如下(第二个例子为例):
二,转换操作
对拆分之后的数据进行转换,调用函数在每一个group上产生一个DataFrame,这个DataFrame和原始的对象有相同的索引,并且填充转换之后的值。
DataFrameGroupBy.transform(func, *args, **kwargs)
参数注释:参考agg的参数注释。
在上面的agg中,我们学会了如何求不同公司员工的平均薪水,如果现在需要在原数据集中新增一列avg_salary,代表员工所在的公司的平均薪水(相同公司的员工具有一样的平均薪水),该怎么实现呢?如果按照正常的步骤来计算,需要先求得不同公司的平均薪水,然后按照员工和公司的对应关系填充到对应的位置,不用transform的话,实现代码如下:
In [21]: avg_salary_dict = data.groupby('company')['salary'].mean().to_dict() In [22]: data['avg_salary'] = data['company'].map(avg_salary_dict) In [23]: data Out[23]: company salary age avg_salary 0 C 43 35 29.25 1 C 17 25 29.25 2 C 8 30 29.25 3 A 20 22 21.50 4 B 10 17 13.00 5 B 21 40 13.00 6 A 23 33 21.50 7 C 49 19 29.25 8 B 8 30 13.00
如果使用transform的话,仅需要一行代码:
In [24]: data['avg_salary'] = data.groupby('company')['salary'].transform('mean') In [25]: data Out[25]: company salary age avg_salary 0 C 43 35 29.25 1 C 17 25 29.25 2 C 8 30 29.25 3 A 20 22 21.50 4 B 10 17 13.00 5 B 21 40 13.00 6 A 23 33 21.50 7 C 49 19 29.25 8 B 8 30 13.00
还是以图解的方式来看看进行groupby后transform的实现过程(为了更直观展示,图中加入了company列,实际按照上面的代码只有salary列)
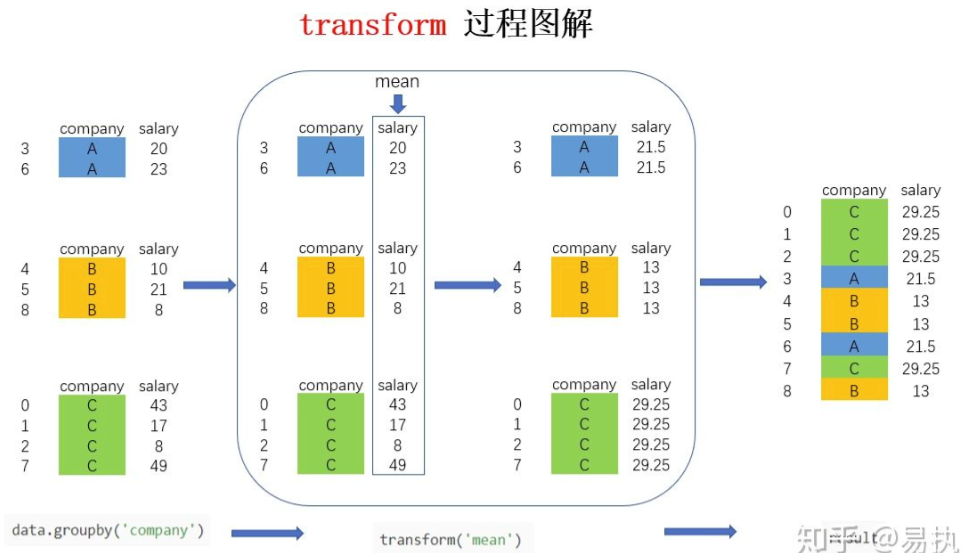
图中的大方框是transform和agg所不一样的地方,对agg而言,会计算得到A,B,C公司对应的均值并直接返回,但对transform而言,则会对每一条数据求得相应的结果,同一组内的样本会有相同的值,组内求完均值后会按照原索引的顺序返回结果,如果有不理解的可以拿这张图和agg那张对比一下。
三,应用函数
apply函数把函数应用于每个分组中:
GroupBy.apply(func, *args, **kwargs)
例子1:按照A列进行分组,对每个分组的每列都执行:分组中列的最大值-最小值:
df = pd.DataFrame({'A': 'a a b'.split(),
'B': [1,2,3],
'C': [4,6,5]})
g = df.groupby('A')
g[['B', 'C']].apply(lambda x: x.astype(float).max() - x.min())
B C
A
a 1.0 2.0
b 0.0 0.0
例子2:用分组的均值去填充分组内每列的缺失值
fill_mean=lambda g: g.fillna(g.mean()) df.groupby(group_key).apply(fill_mean)
四,重置索引
对分组之后的数据,可以使用reset_index()函数,把函数和值重置为DataFrame类型。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号