Databricks 第1篇:初识Databricks,创建工作区、集群和Notebook
Azure Databricks是一个可扩展的数据分析平台,基于Apache Spark。Azure Databricks 工作区(Workspace)是一个交互式的环境,工作区把对象(notebook、library、dashboards、experiments)组织成文件夹,用于数据集成和数据分析。
一,Azure Databricks的基本概念
1,工作区是一个交互式的环境
工作区是一个交互式的环境,可以管理Databricks的集群、Notebook、Job等对象。
2,集群是运行Notebook和job的资源
在使用工作区中,要进行数据集成和数据分析,必须创建集群(Cluster),Cluser代表运行notebook和job的计算资源,并用于存储相应的配置信息。
Cluster有两种类型:通用(All-purpose)和job,all-purpose集群是交互式的,用于通用的数据集成和数据分析任务,而job类型的集群用于定时运行job。
Job用于立即或按照计划来运行notebook或library。job类型的集群在job开始时创建,在job完成时结束。
根据cluster的类型,把Azure Databricks的工作负载(workload)分为两个类型:data engineering (job) 和 data analytics (all-purpose)。
- 数据工程:(自动)工作负载在Job群集上运行,Azure Databricks作业计划程序为每个工作负载创建了一个工作群集。
- 数据分析:(交互式)工作负载在all-purpose集群上运行,交互式工作负载通常在Azure Databricks笔记本中运行命令,但是在现有的通用集群上运行作业也被视为交互式工作负载。
3,Notebook是一个基于Web的记事本
Notebook是一个包含可执行命令的记事本,用户可以在Notebook中编写Python命令,编辑命令,并执行命令,获得输出的结果,并可以对结果进行可视化处理,Notebook的功能和UI类似于Jupyter Notebook。
二,创建Workspace
通过Azure UI来创建工作区,从Azure Services中找到Azure Databricks。

创建工作区,选择订阅用于管理资源和成本,需要设置订阅(Subscription)和资源组(Resource group),选择定价策略(Pricing Tier)。

选择“Review + Create”,点击Create 按钮来创建工作区。等到工作区部署完成之后,打开Azure Databricks Service,点击“Launch Workspace”登录到工作区门户。

三,创建Spark Cluster
Spark Cluster可以看作是Databricks的计算资源,因此必须创建集群。
1,登录到工作区门户
登录(Launch)到新建的工作区门户中,从“Common Tasks”列表中点击“New Cluster”。
2,配置集群
Cluster Mode:集群的模式共有三种,High concurrency(高并发)、Standard(标准)和Single Node(单节点)。标准模式是推荐模式,通常用于单用户的集群。
Pool:Pool是一组空闲的随时可用的实例,可减少集群启动和自动缩放的时间。当连接到Pool的集群需要一个实例时,它首先尝试分配Pool的中一个实例,如果该Pool没有空闲的实例,那么该Pool将通过从实例提供者分配有ige新的实例来扩展,以满足集群的需求。集群释放实例后,它将返回到Pool中,并可以提供给其他集群使用。只有连接到Pool的集群才能使用该Pool的空闲实例。实例在Pool中处于空闲状态时是免费的。
Databricks Runtime:运行时版本配置,选择用于创建集群的image,运行时是在集群上运行的一组核心组件。
Enable autoscaling:勾选自动缩放,根据工作负载的不同,集群在最大节点数量和最小节点数量之间自动缩放。
Terminate after xx minutes of inactivity:当集群不活动时,延迟一定时间后,结束集群。
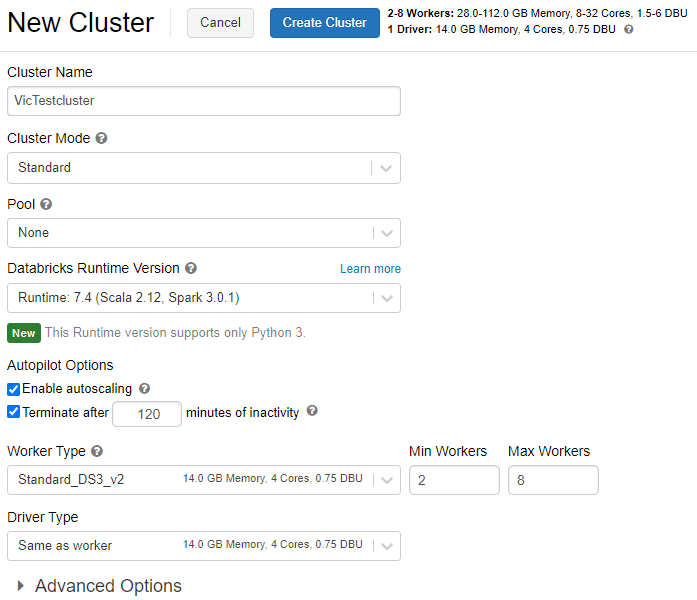
配置完成之后,点击顶部的“Create Clustere” 按钮创建集群。
四,创建Notebook
Notebook是一个包含可执行命令的记事本,用户可以在Notebook中编写Python命令,编辑命令,并执行命令,获得输出的结果,并可以对结果进行可视化处理。
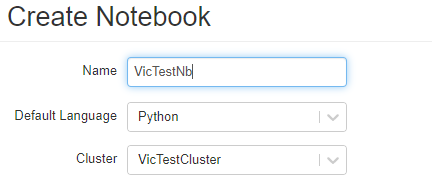
从Common Tasks中选择“New Notebook”,输入Notebook的Name,选择编程语言Python、选择集群,点击对话框底部的“Create”按钮创建Notebook。
在新建的Notebook中输入命令,打印"hello world",点击"Shift+Enter",执行命令

参考文档:
Quickstart: Run a Spark job on Azure Databricks Workspace using the Azure portal

 浙公网安备 33010602011771号
浙公网安备 33010602011771号