ADF 第二篇:使用UI创建数据工厂
Azure Data Factory 系列博客:
- ADF 第一篇:Azure Data Factory介绍
- ADF 第二篇:使用UI创建数据工厂
- ADF 第三篇:Integration runtime和 Linked Service
- ADF 第四篇:管道的执行和触发器
- ADF 第五篇:转换数据
- ADF 第六篇:Copy Data Activity详解
- ADF 第七篇:控制流概述
- ADF 第八篇:传递参数(Pipeline的Parameter和Variable,Activity的output)和应用表达式
用户可以通过UI来创建ADF,在UI中创建ADF时,用户不需要下载单独的IDE,而仅仅通过 Microsoft Edge 或者 Google Chrome浏览器。用户登录Azure Portal,选择 “Data factories” 服务,通过 Data factories 服务中创建ADF。

一,创建Data Factory实例
打开 Data factories之后,点击“+ Add”,创建自己的数据工厂实例:
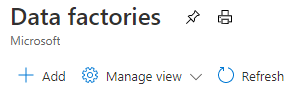
step1,填写Basics信息
在 “Create Data Factory” 面板中开始创建数据工厂实例,首先填写“Basics”信息:Subscription(订阅)、资源组(Resource group)、区域(Region)、名称(Name)和版本(Version),版本选择V2。
step2:配置git
在V2版本中,用户在创建数据工厂时,还可以配置“Git configuration”,用于版本控制,可以勾选“Configure Git later”,在创建数据工厂实例之后,择机配置git。

step3:检查和创建
检查(Review+Create)无误后,点击“Create” 按钮创建Data factory 实例。等实例创建完成,点击Next Step “Go to resource” 导航到数据工厂页面。
二,作者和监视器
在Data factory的overview页面上,点击"Authoer & Monitor"按钮,这会导航到 Azure Data Factory的用户界面(UI)页面中。

ADF的UI界面如下图所示,界面中显示了常用的几个功能:Create Pipeline、Create Data Flow等。

由于我们是第一次创建Data Factory,在创建Pipeline之前,我们还需要创建连接(connection)和数据集(dataset)。
三,创建连接服务
点击UI界面左侧的“Manage”选项卡,首先创建连接,连接有两种类型:Linked services 和 Integration runtimes,本文创建Liked Services,由于Linked Services 依赖于Integration runtimes,因此,我们首先创建Integration runtimes。
1,创建Integration runtimes(IR)
如何创建Integration runtimes,请阅读:《ADF 第三篇:Integration runtime和 Linked Service》
2,创建Linked Services
在Connections中选中“Linked Services”,点击“+New”,创建一个新的Linked Services:
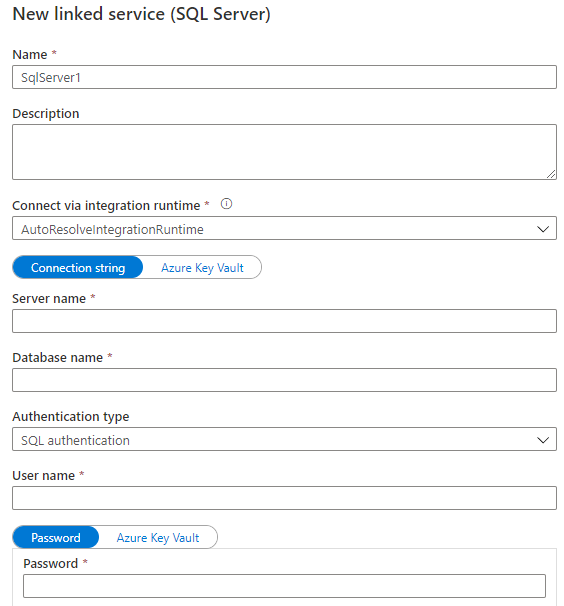
不同的数据源,有不同的Linked Service,要根据实际的数据源,选择合适的数据源的类型,下图创建的Linked Service的类型是SQL Server,输入 Name、Connect via integration runtime、Server name、Database name、Authentication type 、 User name和 Password。
注意,Connect via integration runtime 就是上一节创建的Integration runtimes。
Azure Key Vault是一个存储空间,用户把密码存储到Azure Key Vault中,输入Key Vault的名称和密码就能提取它存储的信息。
四,创建Dataset
dataset 代表数据存储的结构(schema),它既可以代表数据源,从数据源中读取数据;也可以代表数据目标,把数据存储到该数据目标中。
创建一个dataset实例,只是存储了数据存储的结构等元数据信息,而不会真正存储实际的数据。数据真正存储在dataset指向的底层存储对象中,举个例子,dataset执行SQL Server实例中的一个表,那么数据实际存储在这个表中,而dataset存储的数据是表的结构和导航到表的Linked Service。同一个dataset,既可以作为获取数据的数据源,也可以作为存储数据的数据目标。
点击“铅笔”对应的“Author”选项卡,进入到Fact Resources界面,点击“+”,选择 Dataset,进入到创建Dataset的界面
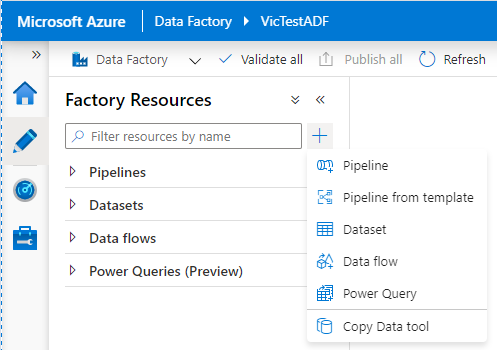
设置Dataset的属性,设置Dataset的Name,通过Linked service来获取源数据的连接,通过Table name来指定表,建议把Import schema设置为From conneciton/store。

五,创建Pipeline
创建管道,管道相当于一个容器,可以把一个或多个Activity拖放到管道中。
如果向管道中放置Activity?用户不需要编写任何代码,只需要从“Activities”列表中选择需要的Activity,拖放到Pipeline中,常用的Activity 通常位于“General”子目录中。
本文演示Copy data Activity的用法,从“Move & transform”子目录,选择Copy data:

Copy Activity的作用是把数据从一个dataset转移到另一个dataset中。
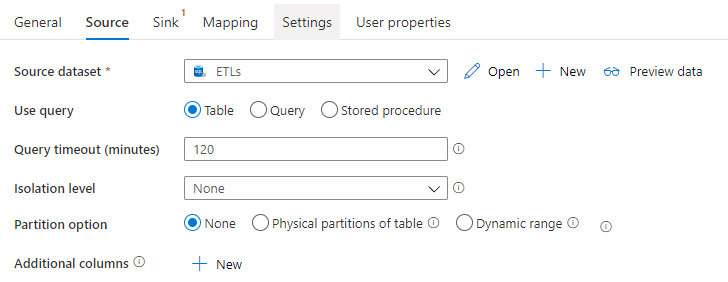
1,设置Copy Activity的Source属性
Source 属性表示数据源,Copy Activity 从Source dataset中获取数据:
2,Copy Activity的Sink属性
Sink属性用于设置数据目标,Sink dataset用于存储数据:

3,Copy Activity的其他属性
Mapping属性选项卡用于设置Source dataset和Sink dataset之间的列映射,并可以设置列类型的转换。
4,调试Pipeline
点击“Debug”对当前Pipeline进行调试
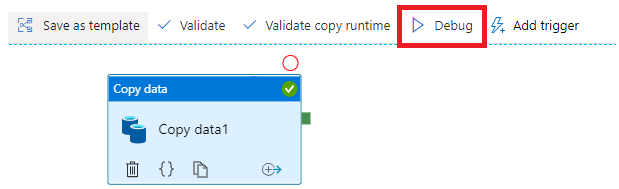
到此,一个简单的ADF就创建完成。
参考文档:
Quickstart: Create a data factory by using the Azure Data Factory UI

 浙公网安备 33010602011771号
浙公网安备 33010602011771号