spaCy 第一篇:核心类型
spaCy 是一个号称工业级的自然语言处理工具包,最核心的数据结构是Doc和Vocab。Doc对象包含Token的序列和Token的注释(Annotation),Vocab对象是spaCy使用的词汇表(vocabulary),用于存储语言中共享的数据,spaCy通过集中存储字符串,单词向量和词汇属性(lexical attribute)等,避免存储数据的多个副本。
spaCy模块有4个非常重要的类:
- Doc:访问语言注释的容器
- Span:Doc对象的一个切片
- Token:单独的Token,例如,单词,符号,空格等
- Vocab:存储词汇表和语言共享的数据
一,Vocab类
Vocab对象用于存储词汇表和语言共享的数据,可以在不同的Doc对象之间共享数据,词汇表使用Lexeme对象和StringStore对象来表示。
>>> import spacy >>> nlp=spacy.load("en_core_web_lg") >>> apple=nlp.vocab[u'apple']
apple是一个Lexeme对象,vocab还包含一个strings属性,用于表示把单词映射到64位的哈希值,这使得每一个单词在spaCy中只存储一份。
1,Lexeme类型
Lexeme对象是词汇表Vocab中的一个词条(entry),可以通过该similarity()函数计算两个词条的相似性:
apple = nlp.vocab[u"apple"] orange = nlp.vocab[u"orange"] apple_orange = apple.similarity(orange)
Lexeme对象的属性,通常属性是成对存在的,不带下划线的是属性的ID形式,带下划线的是属性的文本形式:
- text:文本内容(Verbatim text content)
- orth、orth_:文本ID和文本内容
- lower、lower_:文本的小写
- is_alpha、is_ascii、is_digit、is_lower、is_upper、is_title、is_punct、is_space:指示文本的类型,返回值是boolean类型
- like_url、like_num、like_email:指示文本是否是url、数字和email,返回值是boolean类型
- sentiment:标量值,用于指示词汇的积极性
- cluster:布朗Cluster ID
2,StringStore类型
StringStore类是一个string-to-int的对象,通过64位的哈希值来查找词汇,或者把词汇映射到64位的哈希值:
>>> from spacy.strings import StringStore >>> stringstore = StringStore([u"apple", u"orange"]) >>> apple_hash = stringstore[u"apple"] >>> apple_hash 8566208034543834098
Vocab的strings属性是一个StringStore对象,用于存储共享的词汇数据:
apple_id=nlp.vocab.strings[u'apple'] >>> apple_id 8566208034543834098
3,Vocab类
在初始化Vocab类时,传递参数strings是list或者StringStore对象,得到Vocab对象:
from spacy.vocab import Vocab vocab = Vocab(strings=[u"apple", u"orange"]) >>> vocab.strings[u"apple"] 8566208034543834098
二,Token类
Token是一个单词、标点符号、空格等,在自然语言处理中,把一个单词,一个标点符号,一个空格等叫做一个token。
>>> import spacy >>> nlp=spacy.load("en_core_web_sm") >>> doc=nlp("I like apples and oranges") >>> token_apple =doc[2] >>> token_orange=doc[4]
1,Token对象的函数
计算不同token之间的语义相似性
token_apple.similarity(token_orange)
对一段文本,获得相邻的token,默认情况下,得到的是下一个相邻的token:
>>> token_apple.nbor() and
从一段文本种,获得相连的token:
token_apple.conjuncts
(oranges,)
2,Token对象的属性
Token对象,除了具有Lexeme对象属性之外,还具有Token对象特有的属性:
- doc:父doc
- sent:token所在的Span对象
- text:文本
- orth、orth_:文本ID和文本
- i:token在父doc中的索引
- ent_type、ent_type_:命名实体类型
- lemma、lemma_:token的基本形式(base form)
- norm、norm_:token的标准化形式
- pos、pos_:token的词性(Coarse-grained POS)
- tag、tag_:token的词性(Fine-grained POS)
- lower、lower_:token的小写形式
- is_alpha、is_ascii、is_digit、is_lower、is_upper、is_title、is_punct、is_space
- like_url、like_num、like_email
- sentiment
三,Doc类
对一个文本数据进行分词之后,Doc对象是token的序列,Span对象是Doc对象的一个切片:
>>> import spacy >>> nlp=spacy.load("en_core_web_sm") >>> doc=nlp("I like apples and oranges")
>>> span=doc[0:3]
1,获得文本的命名实体
doc.ents
2,获得文本的名词块
doc.noun_chunks
3,获得文本的句子
doc.sents
4,查看doc的文本
doc.text
四,Span类
Span对象是Doc对象的一个切片,Span对象的属性:
- start:span的第一个token在doc中的索引
- end:span的最后一个token在doc中的索引
- text:span的文本
- orth、orth_:span的文本
- lemma_:span的lemma
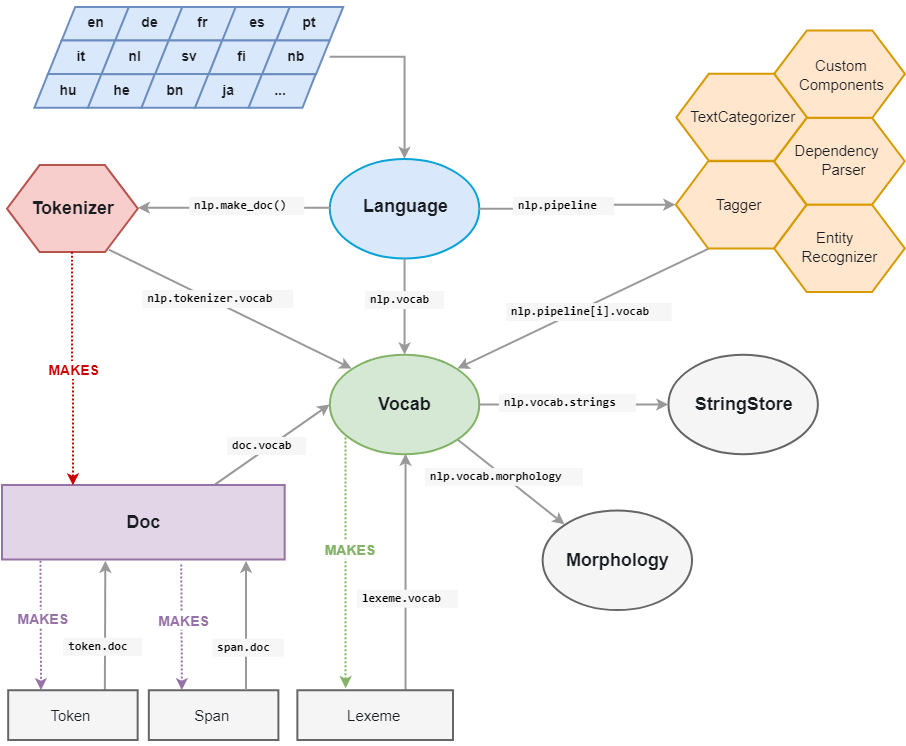
六,spaCy的架构
Doc对象是由Tokenizer构造,然后由管道(pipeline)的组件进行适当的修改。 Language对象协调这些组件,它接受原始文本并通过管道发送,返回带注释(Annotation)的文档。 文本注释(Text Annotation)被设计为单一来源:Doc对象拥有数据,Span是Doc对象的视图。
参考文档:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号