《数据仓库工具箱-第一章》
第三版是2015年出版的,是行业内维度建模的权威书籍。
第一章
数据系统的分类
操作型系统:用于存数据,即数据库
DW/BI(数仓/商业智能)系统:用于分析数据,即数仓
维度建模
范式模型通常被称为ER模型,但实际上维度模型也属于ER模型,因为他们都包含可连接的关系表。区别其实就是规范化程度不同(前者满足3NF,以绝对消除冗余)。
范式建模(3NF模型)主要应用于操作型过程中。
原因:
1、保证原子性和一致性。范式建模用于操作型过程(即存储数据库中操作数据)的原因,是因为它仅需要修改单一位置。这种点对点的小范围修改更能保证原子性和一致性。
2、范式建模由于太过范式化,导致查询性能低下(多表联合)
星型模型

事实表关联维度模型,像星星一样
OLAP多维数据库
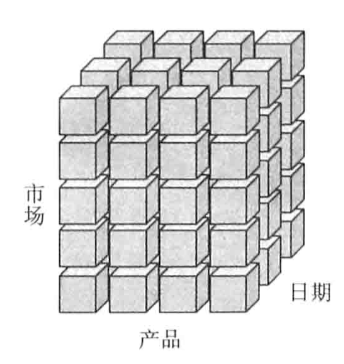
是数据库的具体实现,一个个cube组成,如上图。
星型模型 与 OLAP多维数据库区别和联系
星型模型是持久化存储数据的技术,OLAP多维数据库是有索引、内置函数的数据库实现。
前者是后者的数据存储基础,后者通过吸取、加载前者的数据,来构建后者自身。
前者存数据,后者高效的分析数据。
事实表
用于记录事件:

维度表
主要保存是描述性信息:WHO WHERE WHAT WHY WHEN HOW
维度表可不停机更新,对已有业务没有影响。
和事实表相比,维度表通常较小,存在些冗余也没太大问题。
事实表和维度表的区别
事实表中的字段通常是连续值、可变值,而维度表通常是非连续的离散值、常量。
一个核心观点是,粒度最小的、原子的业务数据具有最多的维度
这一反直觉的结论的原因是粒度越小,可以关联的维度信息就越多。
几种DB/BI架构
一、Kimball的DW/BI架构(四部分)
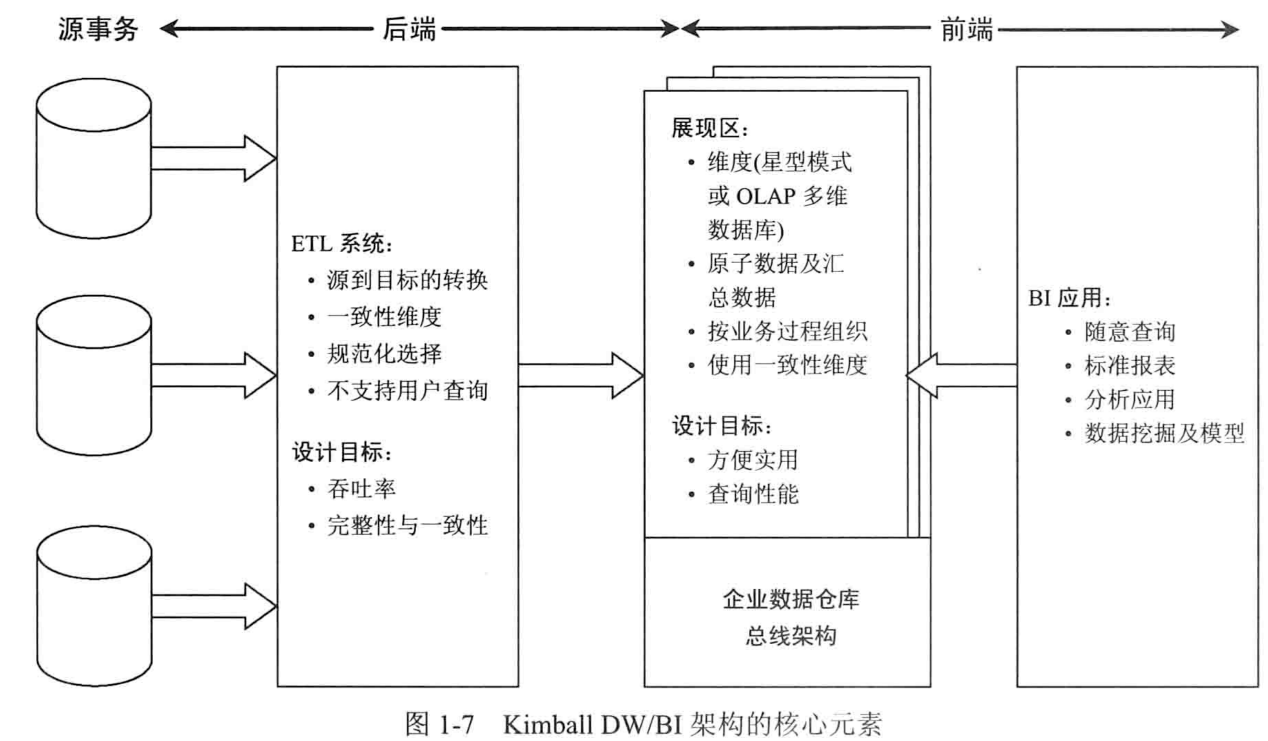
源系统
获取、存储业务事务。一般不存历史。
ETL(获取、转换、加载)
这一过程不再具体赘述。
但是必须知道,ETL的主要功能是划分出维度表和事实表。我行目前没有在ETL阶段进行此行为。
我行目前通过etl加载贴源数据到数据湖,然后再湖里由模型师进行业务判断从而对表进行拆分,然后输出给数据仓库中。
展现区(用于支持BI决策)
作者强调第一点:
维度模型必须包含原子数据,汇总数据仅为性能补充。
这样做的原因是,用户可能进行下钻、意外的查询。如果模型仅包含“当日总销售额”(汇总数据),用户将无法下钻查询“每个小时的销售额”。
【问题】那模型有何意义?直接接贴源表不就行了?
【我的想法】因为贴源表不符合 |事实表|维度表| 的拆分结构,为了向用户展示维度模型(好处不再赘述),一定要进行拆分。
作者强调第二点:
维度必须是一致性的、公共的。即,不同维度表中相同的字段名含义一致、不同维度表中相同的字段值的含义一致。
这样做是为了能够广泛关联起所有维度模型的维度信息,避免“烟囱式”开发、重复开发和口径翻译。
二、辐射状企业信息工厂Inmon架构(CIF)

CIF提供一个下游可以直接访问的EDW原始源,用户可以通过访问EDW来获得原始的原子数据。(但实际上下游访问的通常是数据集市中的汇总数据)
CIF和Kimball结构存在明显区别
Kimball围绕业务过程展开,即,在展现区,存的是“销售表”、“采购订单”等。数据都是原子级的。
而CIF围绕部门需求展开,存的都是定制化数据。数据集市都是“销售部门数据集市”、“财务部门数据集市”等。只包含部门关心的特定维度。数据都是汇总级的。
CIF的问题
语义鸿沟:数据集市中重命名的字段很难和EDW的原始字段联系起来;
聚合导致细节丢失:汇总数据导致原子性被抹掉;
追踪与溯源困难,想知道某个汇总字段如何来的,需要复杂的分析、溯源。
三、混合辐射状架构与Kimball架构
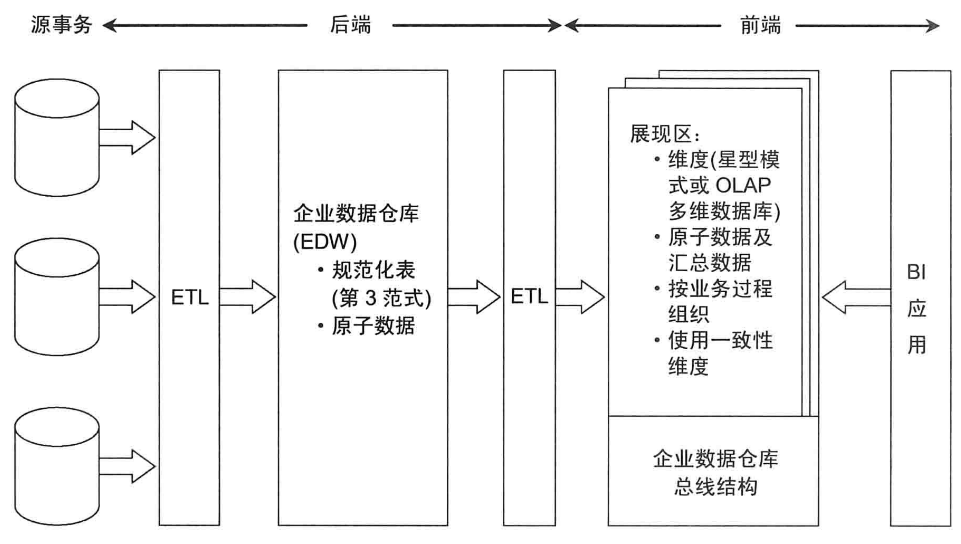
在混合型架构中,EDW对下游不公开。EDW的数据是原子的(辅以汇合数据)。这种方法是以过程为中心的。
离线加载
离线加载的目的是解决EDW原子数仓的低效问题。离线加载就是把EDW的原子数据转换、加载到展现区的维度模型中,而非直接提供给下游。(e.g.下游报表的数据从维度模型中取,而非从EDW中直接取,由于维度模型是以单个业务为中心进行构建的,因此减少了表关联操作,效率提高很多。)
维度建模漫话
维度建模能提高效率的原因
答:不是因为所谓的提前聚合汇总,并没有这个操作,反而数据还都是原子化的。主要原因是维度模型都是围绕某个具体的业务建设的,这样的维度模型大大减少了表数量,使得关联操作时,只需要关联少数维度表即可,因此提高了效率
维度建模的原子粒度
"由于不可能预测业务用户提出的所有问题,因此必须向业务用户提供对细节数据的查询访问,这样业务用户才能基于其业务问题开展上卷操作"
这句话指出了我们对下游提供的,必须是原子粒度的数据(可以引入汇总数据提升效率),否则会导致下游用户的查询受限。这一点是应对不确定的需求的基础,十分重要,是本书的核心观点。
维度建模的抓手
要以业务为中心建立维度模型,而不是以部门为中心(即特供给某个部门自己的需求)
维度建模一致性、集成性
一致性极其重要。一致性包括字段值语义一致性和字段名称语义一致性。一致性是避免重复获取相同数据、造成数据冲突的基础,也是维度模型集成的基础(即模型之间相互关联)。这一点,在最初建立数仓的时候就要考虑到。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号