

正则模块 正则表达式
帅爆太阳的男人
1,正则表达式:一种匹配字符串的规则(就是做数据的匹配)
- 正则表达式的应用场景:
- 1.1>正则表达式可以指定一个规则
- 1.1.1>来确认某一个字符串是否符合规则
- 1.1.2>从大段的字符串中找到符合规则的内容
- 1.2>程序领域
- 1.2.1>登录注册页的表单验证,web开发,要求简单语法
- 1.2.2>爬虫(爬虫把这个网页下载下来,从里面提取一些信息,找到我要的所有信息,做数据分析)
- 1.2.3>自动化开发,日志分析
- 1.1>正则表达式可以指定一个规则
2,正则的语法
- 2.1>学习的工具:http://tool.chinaz.com/regex/
- 2.2>字符组,用中括号表示 [ ]:表示在一个位置上出现的内容(一个[ ]只表示在一个位置出现的内容)[^]表示非字符组,表示在一个字符的位置上出现那些内容
- 2.2.1>
- [0-9]表示在你输入的每一个位置的内容值识别是0-9的其中一个数字
- [123]表示在你输入的每一个位置出现的内容识别1,2,3其中的数字
- [0-9][1-5]表示一对儿输入的内第一个的数字符合0-9(包括边界的0和9),第二个数字符合1-5(包括边界的1和5)
- [A-Z]表示匹配的大写字母(包括边界的A和Z)
- [a-z]表示匹配小写字母(包括边界)
- [A-Z][a-z]表示每两个字符的第一个字符字母是大第二个字符小写(总是成一对儿出现输入的每个字符只要符合这个规则即可,没有明确的位置限定)
- [0-9][A-Z][a-z]表示每 三个字符,第一个字符是0-9的数字,第二个字符是A-Z的大写字母的任意一个,第三个字符是a-z里边的一个(同样没有位置的限定,只要符合这样格式的得三个位置就可以)
- [0-9A-Za-z]表示输入的每一个位置可以是数字,可以使大写字母,可以是小写字母(只表示输入的每一个字符的内容)
- [A-z]表示输入的每一个字符的内容可以是大写字母,也可以是小写字母(尽量不要用,不规范)
- ###...像A-z这样的取值顺序是根据计算机ASCII码去判断的...###
2,元字符(就是用另外一种方式将字符组表达出来,有时候觉得元字符更所的想变量)
- \d ==[0-9]表示匹配每输入位置的内容匹配的是数字................digit
- \w ==[0-9A-Za-z]表示匹配每一个位置可以是数字,字母,下划线...............word
- \s ==[\n,\t,空格]表示匹配每一个位置可以是换行,制表符(Tab),可以是空格.................space
- \n == 匹配回车
- \t == 匹配制表符
- \D == 匹配非数字以外其他的东西都可以(输入的每一个字符只要不是数字都可以)
- \W == 匹配非数字,字母,下划线的东西(输入的每一个字符只要不是数字,字母,下划线就可以被识别)
- \S == 匹配非空白(输入的每一个不是空格据可以被识别)
- \b == 表示判断一个单词的结尾
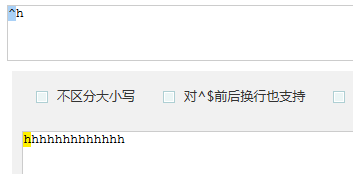
- ^ == 匹配字符串的开始,比如:
- ^hello判断输入的字符串是不是以hello开始(这时是以一个hello为单元去判断)
- ^h则判断输入的字符串是不是以h开头,这时只要是输入的一个字符串只要一h开头,
- 后边再有几个h也不会被识别了,只识别开头的第一个,因此有且只有一个匹配结果

- $ == 匹配字符串的结尾,比如:
- hello$判断输入字符串是不是以hello结尾(这时是以hello为单元去判断)
- h$则判断输入的字符串是不是以好h结尾(这时输入的是以h为单元去判断的)
- 前边有几个hello和h都不会被识别,因此$有且只有1个匹配结果.
- a|b == 匹配字符a或者字符(在输入的每一个字符匹配是a或者b都可以进行匹配成功,匹配的是么一个字符)
- 正则表达式()表示分组 比如:(A-Z)|(a-z)这时把A-Z或是者a-z当成是一个单元去匹配A-Z或者a-z,(这时的A-Z和a-z就不是一个范围,而是固定的字符),当 | 左右边出现多个的时候就把"|"左边整体作为一个单元,右边同时也作为一个整体,去匹配,两边出现任何一个就会匹配成功
- [^abc]表示匹配不是abc的字符都可以被匹配(在[^aSFA]中的字符组的前边加^会表示非,除了中括号里的字符都可以匹配)
- [abc^]此时和[abc]的匹配机制是一样的匹配输入的字符是a或b或c,^这个东西只要不放在字符组的开头,就和不加^一样
3,量词:表示一个或者多个字符组或者元字符出现的次数.
- 3.1> *表示重复0次或多次.列如:[abc]*是表示abc这几个字符可以最多匹配几次,它会每一个都去匹配不论成功与否,都会作为一次匹配结果的计数(他在最后没有私服的时候还会比一次,比完之后才知道没有字符了)

- 3.2> + 重复一次或更多次.列如:[abc]*则表示输入的字符当abc单个出现的时候匹配一次,当abc连着出现或者bac也可以当做匹配一次里边的顺序可以打乱
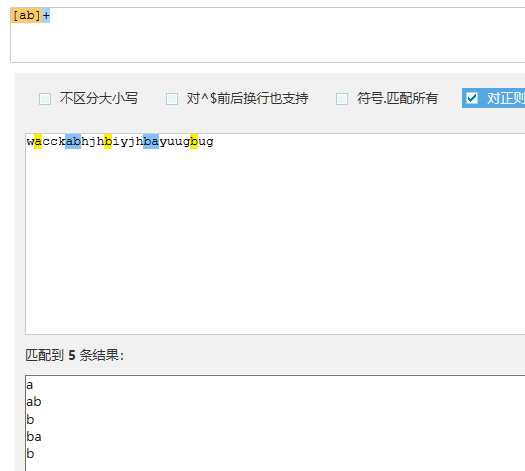
3.3> ? 表示重复0次或一次

- 3.4>{n}表示重复几次,把前边的作为一个单元匹配在输入的字符中出现几次(此时把5个3单做一个单元来匹配)
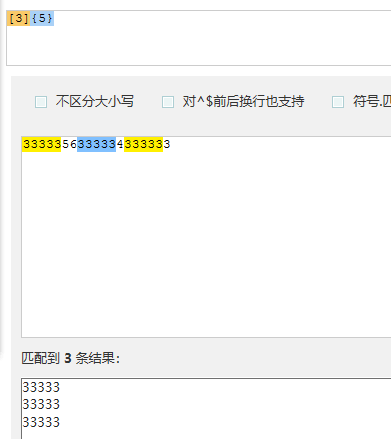
3.5>{n,}表示重复n次或更多次,把前边作为一个单元在输入的字符中出现几次(此时表示输入的字符中大于5个的3都作为一个单元去匹配)

3.6> {n,m}表示从n重复到m次)(此时表示3这个字符连着出现2次或者3次匹配得次数)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号