

深入解析:ShardingSphere数据库中间件:入门与使用
在数据库中间件的世界里,ShardingSphere 是一款备受瞩目的工具。它能帮助我们更高效地管理数据库,尤其是在处理大规模数据时,其优势更为明显。接下来,我们就一起深入了解 ShardingSphere 的架构、基本使用、分片规则配置,以及如何解决使用过程中可能遇到的问题。
目录
ShardingSphere的架构
ShardingSphere 是一个开源的分布式数据库中间件生态系统,它主要包含三个独立的产品:Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(规划中)。这些产品相互协作,共同构成了 ShardingSphere 的强大架构。
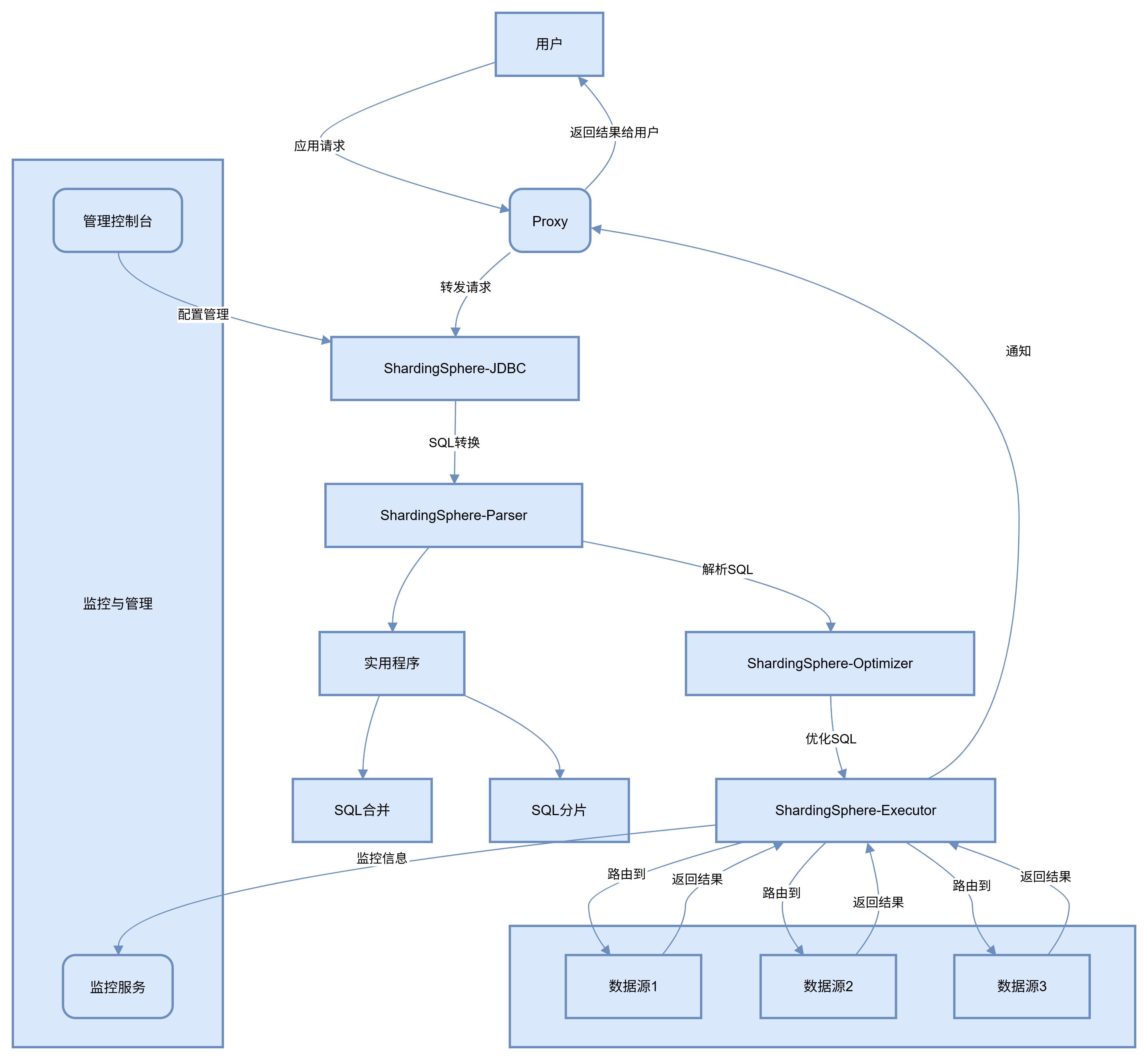
Sharding-JDBC:这是一个轻量级的 Java 框架,它以 jar 包的形式提供服务,无需额外部署和依赖。它可以理解为是一个增强版的 JDBC 驱动,应用程序通过它可以像操作普通数据库一样操作分布式数据库。简单来说,它就像是一个智能的翻译官,把应用程序的 SQL 请求翻译成适合分布式数据库的执行方式。例如,在一个电商系统中,商品数据按照商品类型进行分片存储在不同的数据库中,Sharding-JDBC 可以根据商品类型自动将查询请求路由到对应的数据库中。
Sharding-Proxy:这是一个独立的数据库代理服务,它对外提供 MySQL、PostgreSQL 等标准的数据库协议。应用程序可以像连接普通数据库一样连接 Sharding-Proxy,而 Sharding-Proxy 负责将 SQL 请求路由到后端的分布式数据库中。它就像是一个交通枢纽,统一管理着应用程序和分布式数据库之间的通信。比如,在一个大型的企业级应用中,不同部门的应用程序都可以通过 Sharding-Proxy 来访问分布式数据库,而不需要关心数据库的具体分片情况。
Sharding-Sidecar:虽然目前还处于规划中,但它的设计理念是作为一个轻量级的代理,以 Sidecar 模式部署在应用程序的旁边。它可以为应用程序提供透明的数据库访问服务,就像是应用程序的贴身保镖,默默地处理数据库访问的细节。
ShardingSphere的基本使用
下面我们通过 Java 代码片段来展示 ShardingSphere 的基本使用。
引入依赖
首先,我们需要在项目中引入 ShardingSphere 的依赖。如果你使用的是 Maven 项目,可以在 pom.xml 中添加以下依赖:
<dependency>
<groupId>org.apache.shardingsphere</groupId>
<artifactId>sharding-jdbc-core</artifactId>
<version>5.1.1</version>
</dependency>配置数据源
接下来,我们需要配置数据源。以下是一个简单的示例:
import javax.sql.DataSource;
import java.sql.SQLException;
import java.util.HashMap;
import java.util.Map;
import java.util.Properties;
import org.apache.shardingsphere.driver.api.ShardingSphereDataSourceFactory;
import org.apache.shardingsphere.infra.config.algorithm.ShardingSphereAlgorithmConfiguration;
import org.apache.shardingsphere.sharding.api.config.ShardingRuleConfiguration;
import org.apache.shardingsphere.sharding.api.config.rule.ShardingTableRuleConfiguration;
import org.apache.shardingsphere.sharding.api.config.strategy.sharding.StandardShardingStrategyConfiguration;
import com.zaxxer.hikari.HikariDataSource;
public class ShardingSphereExample {
public static void main(String[] args) throws SQLException {
// 配置数据源
Map<String, DataSource> dataSourceMap = new HashMap<>();
// 配置第一个数据源
HikariDataSource dataSource1 = new HikariDataSource();
dataSource1.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource1.setJdbcUrl("jdbc:mysql://localhost:3306/db1");
dataSource1.setUsername("root");
dataSource1.setPassword("password");
dataSourceMap.put("ds0", dataSource1);
// 配置第二个数据源
HikariDataSource dataSource2 = new HikariDataSource();
dataSource2.setDriverClassName("com.mysql.cj.jdbc.Driver");
dataSource2.setJdbcUrl("jdbc:mysql://localhost:3306/db2");
dataSource2.setUsername("root");
dataSource2.setPassword("password");
dataSourceMap.put("ds1", dataSource2);
// 配置分片规则
ShardingRuleConfiguration shardingRuleConfig = new ShardingRuleConfiguration();
// 配置表规则
ShardingTableRuleConfiguration tableRuleConfig = new ShardingTableRuleConfiguration("t_order", "ds${0..1}.t_order${0..1}");
shardingRuleConfig.getTables().add(tableRuleConfig);
// 配置分片策略
shardingRuleConfig.setDefaultDatabaseShardingStrategy(new StandardShardingStrategyConfiguration("user_id", "databaseShardingAlgorithm"));
shardingRuleConfig.setDefaultTableShardingStrategy(new StandardShardingStrategyConfiguration("order_id", "tableShardingAlgorithm"));
// 配置分片算法
Map<String, ShardingSphereAlgorithmConfiguration> shardingAlgorithms = new HashMap<>();
Properties databaseShardingAlgorithmProps = new Properties();
databaseShardingAlgorithmProps.setProperty("algorithm-expression", "ds${user_id % 2}");
shardingAlgorithms.put("databaseShardingAlgorithm", new ShardingSphereAlgorithmConfiguration("INLINE", databaseShardingAlgorithmProps));
Properties tableShardingAlgorithmProps = new Properties();
tableShardingAlgorithmProps.setProperty("algorithm-expression", "t_order${order_id % 2}");
shardingAlgorithms.put("tableShardingAlgorithm", new ShardingSphereAlgorithmConfiguration("INLINE", tableShardingAlgorithmProps));
shardingRuleConfig.setShardingAlgorithms(shardingAlgorithms);
// 创建 ShardingSphere 数据源
Properties props = new Properties();
DataSource dataSource = ShardingSphereDataSourceFactory.createDataSource(dataSourceMap, shardingRuleConfig, props);
}
}在上述代码中,我们首先创建了两个数据源 ds0 和 ds1,分别对应两个不同的数据库。然后,我们配置了分片规则,包括表规则和分片策略。最后,我们使用 ShardingSphereDataSourceFactory 创建了一个 ShardingSphere 数据源。
分片规则配置
分片规则配置是 ShardingSphere 的核心功能之一,它决定了数据如何分布在不同的数据库和表中。下面我们详细介绍一些常见的分片规则配置。
数据库分片规则
数据库分片规则决定了数据如何分布在不同的数据库中。常见的数据库分片策略有以下几种:
哈希分片:根据某个字段的哈希值将数据分布到不同的数据库中。例如,根据用户 ID 的哈希值将用户数据分布到不同的数据库中。在上述代码中,我们使用了
INLINE算法实现了哈希分片,根据user_id的取模结果将数据分布到ds0或ds1中。范围分片:根据某个字段的范围将数据分布到不同的数据库中。例如,根据订单日期将订单数据分布到不同的数据库中,每个数据库存储一个时间段内的订单数据。
表分片规则
表分片规则决定了数据如何分布在不同的表中。常见的表分片策略也有哈希分片和范围分片等。在上述代码中,我们根据 order_id 的取模结果将数据分布到 t_order0 或 t_order1 中。
解决ShardingSphere配置错误、数据不一致问题
在使用 ShardingSphere 的过程中,可能会遇到配置错误和数据不一致的问题。下面我们介绍一些常见问题的解决方法。
配置错误
配置错误通常是由于配置文件或代码中的参数设置不正确导致的。常见的配置错误包括数据源配置错误、分片规则配置错误等。解决配置错误的方法如下:
检查配置文件:仔细检查配置文件中的参数是否正确,例如数据库连接信息、分片规则等。
查看日志文件:ShardingSphere 会记录详细的日志信息,通过查看日志文件可以找到配置错误的具体原因。
数据不一致问题
数据不一致问题通常是由于数据写入或读取过程中出现错误导致的。常见的数据不一致问题包括数据丢失、数据重复等。解决数据不一致问题的方法如下:
检查分片规则:确保分片规则的配置正确,避免数据写入到错误的数据库或表中。
使用事务:在进行数据写入操作时,使用事务可以保证数据的一致性。例如,在进行订单创建操作时,将订单数据和订单详情数据的插入操作放在同一个事务中,确保数据的完整性。
总结
通过以上内容,我们学习了 ShardingSphere 的架构、基本使用、分片规则配置,以及如何解决使用过程中可能遇到的问题。掌握了这些内容后,我们就可以使用 ShardingSphere 进行简单的分片配置,更高效地管理数据库。下一节我们将深入学习数据库中间件的其他高级使用技巧,进一步完善对本章数据库中间件实战主题的认知。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号