

【C++】C++11 核心特性深度解析(二) - 实践
一、类型分类与值类别
1.1 左值 / 右值 / 将亡值——三张“身份证”
把表达式按“身份 + 可移动性”拆成五类,日常编码只需掌握核心三兄弟:
| 类别 | 英文 | 典型例子 | 核心特征 |
|---|---|---|---|
| 左值 | lvalue | obj, *ptr, a[i], ++x | 有持久身份,可取地址,不能绑定到 T&& |
| 将亡值 | xvalue | std::move(obj), 返回 T&& 的函数调用 | 有身份但即将被“掏空”,是“可移动的左值” |
| 纯右值 | prvalue | 42, T(), a+b | 没有身份,占临时对象,生命周期到完整表达式结束 |
记忆公式:
“左值能取地址,将亡值能移动,纯右值是临时。”
1.2 泛左值与纯右值——给五类表达式“归大类”
标准把五类再归成两大族:
glvalue(generalized lvalue) = 左值 + 将亡值
共同点:有身份(identity),代表内存位置。prvalue(pure rvalue) = 纯右值
代表“初始化器”或“计算结果”,不固定内存位置。
示意图:
glvalue ┬─ lvalue
└─ xvalue (将亡值)
prvalue
引入 glvalue 的目的:让“可移动对象”同时保有身份,为移动语义铺路。
1.3 值类别判断口诀
面对任意表达式,按顺序问两句:
能不能取地址
&expr?
→ 能 → 左值
→ 不能 → 继续 2.有没有名字(变量名)且类型是对象引用 / 返回
T&&?
→ 有 → 将亡值
→ 无 → 纯右值
int a = 1;
int& f();
int&& g();
&a; // 1. 能取地址 → 左值
&(a + 1); // 1. 不能取地址 → 2. 无名字 → 纯右值
&f(); // 1. 能取地址 → 左值
&g(); // 1. 不能取地址 → 2. 返回 T&& 且有名字 → 将亡值二、引用折叠规则
2.1 折叠表与推导示例
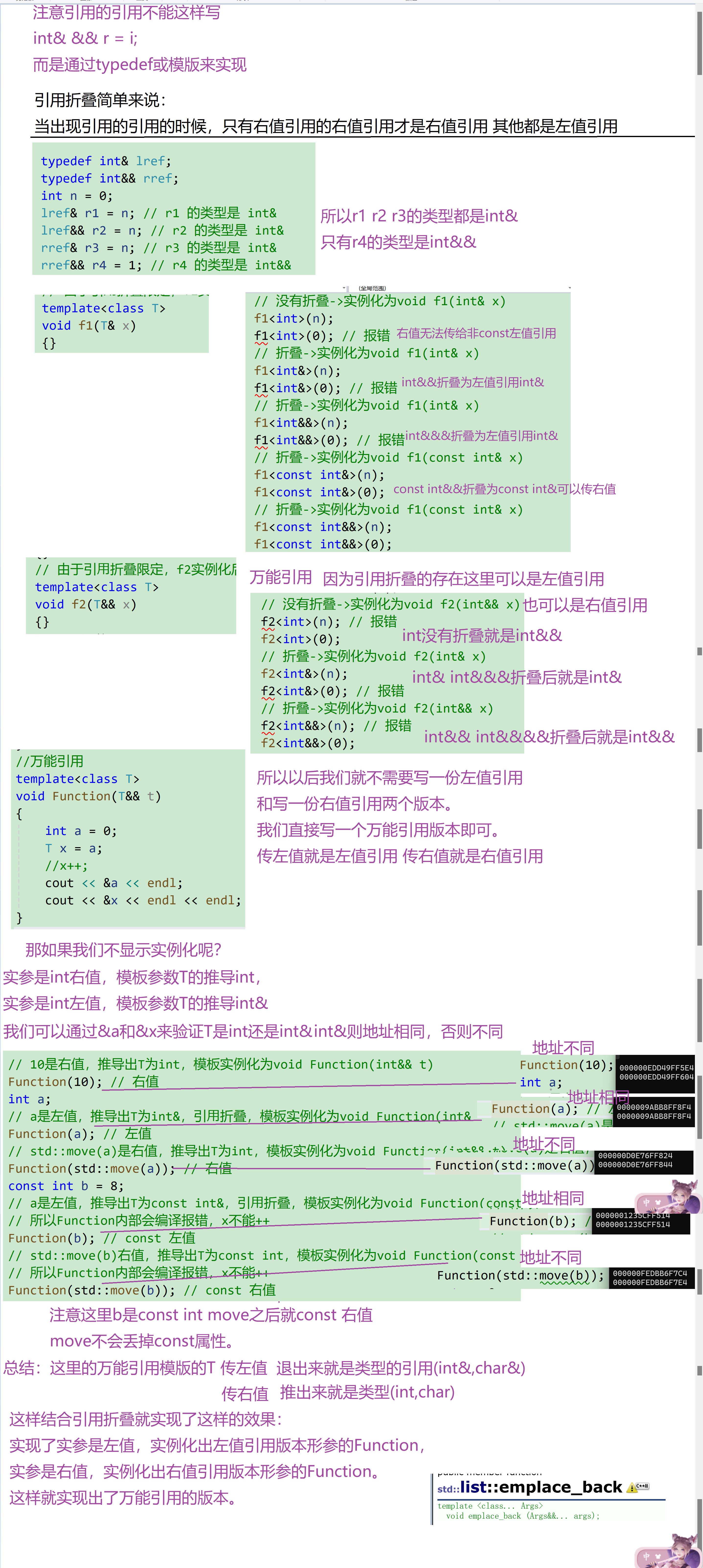
- C++中不能直接定义引用的引用如 int& && r = i; ,这样写会直接报错,通过模板或 typedef中的类型操作可以构成引用的引用。
- 通过模板或 typedef 中的类型操作可以构成引用的引用时,这时C++11给出了⼀个引用折叠的规则:右值引用的右值引用折叠成右值引用,所有其他组合均折叠成左值引用。
- 下面的程序中很好的展示了模板和typedef时构成引用的引用时的引用折叠规则,大家需要⼀个⼀个仔细理解⼀下。
- 像f2这样的函数模板中,T&& x参数看起来是右值引用参数,但是由于引用折叠的规则,他传递左值时就是左值引用,传递右值时就是右值引用,有些地方也把这种函数模板的参数叫做万能引用。
- Function(T&& t)函数模板程序中,假设实参是int右值,模板参数T的推导int,实参是int左值,模板参数T的推导int&,再结合引用折叠规则,就实现了实参是左值,实例化出左值引用版本形参的Function,实参是右值,实例化出右值引用版本形参的Function。
// 由于引⽤折叠限定,f1实例化以后总是⼀个左值引⽤
template
void f1(T& x)
{}
// 由于引⽤折叠限定,f2实例化后可以是左值引⽤,也可以是右值引⽤
template
void f2(T&& x)
{}
int main()
{
typedef int& lref;
typedef int&& rref;
int n = 0;
lref& r1 = n; // r1 的类型是 int&
lref&& r2 = n; // r2 的类型是 int&
rref& r3 = n; // r3 的类型是 int&
rref&& r4 = 1; // r4 的类型是 int&&
//总结 右值引用的右值引用 才为右值引用
// 没有折叠->实例化为void f1(int& x)
f1(n);
//f1(0); // 报错
// 折叠->实例化为void f1(int& x)
f1(n);
//f1(0); // 报错
// 折叠->实例化为void f1(int& x)
f1(n);
//f1(0); // 报错
// 折叠->实例化为void f1(const int& x)
f1(n);
f1(0);
// 折叠->实例化为void f1(const int& x)
f1(n);
f1(0);
// 没有折叠->实例化为void f2(int&& x)
//f2(n); // 报错
f2(0);
// 折叠->实例化为void f2(int& x)
f2(n);
//f2(0); // 报错
// 折叠->实例化为void f2(int&& x)
//f2(n); // 报错
f2(0);
return 0;
} 
2.2 转发引用(Universal Reference)
Tip:转发引用也称为万能引用
只有同时满足两条才算转发引用:
函数模板 && 形参
T 由推导而来(不能是已经确定的类型)
反例对比:
template
void bar(T&& t); // ✅ 转发引用
template
class X {
void baz(T&& t); // ❌ T 在类实例化时固定,是普通右值引用
};
void f(const int&& t); // ❌ 无模板推导 转发(万能)引用代码示例
//万能引用 传左值 推导+引用折叠->>左值引用 传右值 推导+引用折叠 ->> 右值引用
template
void Function(T&& t)
{
int a = 0;
T x = a;
//x++;
cout << &a << endl;
cout << &x << endl << endl;
}
int main()
{
// 10是右值,推导出T为int,模板实例化为void Function(int&& t)
Function(10); // 右值
int a;
// a是左值,推导出T为int&,引⽤折叠,模板实例化为void Function(int& t)
Function(a); // 左值
// std::move(a)是右值,推导出T为int,模板实例化为void Function(int&& t)
Function(std::move(a)); // 右值
const int b = 8;
// b是左值,推导出T为const int&,引⽤折叠,模板实例化为void Function(const int& t)
// 所以Function内部会编译报错,x不能++
Function(b); // const 左值
// std::move(b)右值,推导出T为const int,模板实例化为void Function(const int&&t)
// 所以Function内部会编译报错,x不能++
Function(std::move(b)); // const 右值
return 0;
} 2.3 完美转发 std::forward 实现剖析

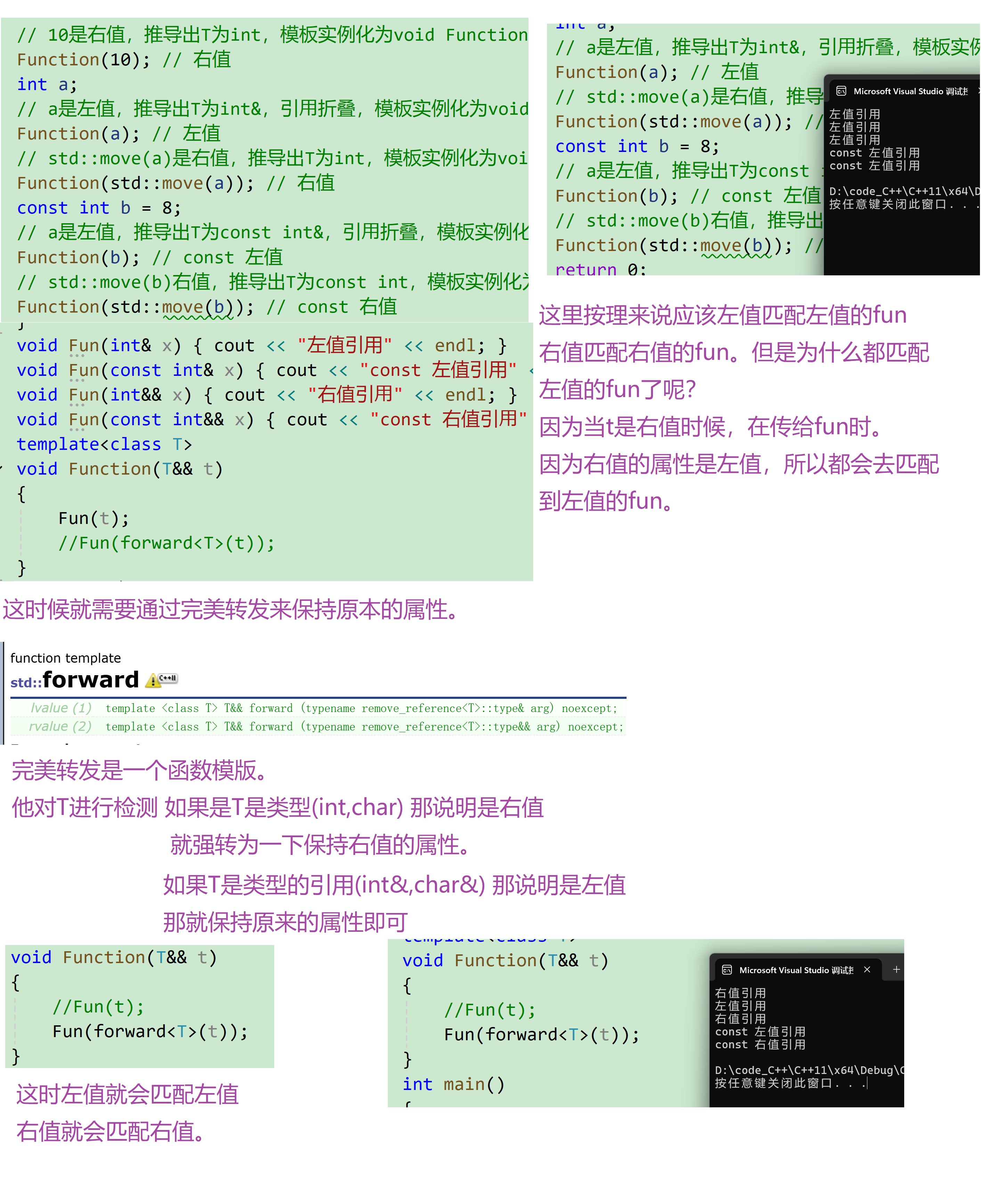
- Function(T&& t)函数模板程序中,传左值实例化以后是左值引的Function函数,传右值实例化以后是右值引用的Function函数。
- 但是结合我们前面讲的,变量表达式都是左值属性,也就意味着⼀个右值被右值引用绑定后,右值引用变量表达式的属性是左值,也就是说Function函数中t的属性是左值,那么我们把t传递给下⼀层函数Fun,那么匹配的都是左值引用版本的Fun函数。这⾥我们想要保持t对象的属性,就需要使用完美转发实现。
- 完美转发forward本质是⼀个函数模板,他主要还是通过引用折叠的方式实现,下面实例中传递给Function的实参是右值,T被推导为int,没有折叠,forward内部t被强转为右值引用返回;传递给Function的实参是左值,T被推导为int&,引用折叠为左值引用,forward内部t被强转为左值引用返回。
void Fun(int& x) { cout << "左值引用" << endl; }
void Fun(const int& x) { cout << "const 左值引用" << endl; }
void Fun(int&& x) { cout << "右值引用" << endl; }
void Fun(const int&& x) { cout << "const 右值引用" << endl; }
template
void Function(T&& t)
{
/*右值引⽤变量表达式的属性是左值,也就是说Function函数中t的属性是左值,那么我们把t传
递给下⼀层函数Fun,那么匹配的都是左值引⽤版本的Fun函数。这⾥我们想要保持t对象的属性,
就需要使⽤完美转发实现。*/
//Fun(t); // 本身属性左值 这样传下去 调用的全是左值引用
Fun(forward(t));
}
int main()
{
// 10是右值,推导出T为int,模板实例化为void Function(int&& t)
Function(10); // 右值
int a;
// a是左值,推导出T为int&,引⽤折叠,模板实例化为void Function(int& t)
Function(a); // 左值
// std::move(a)是右值,推导出T为int,模板实例化为void Function(int&& t)
Function(std::move(a)); // 右值
const int b = 8;
// b是左值,推导出T为const int&,引⽤折叠,模板实例化为void Function(const int& t)
Function(b); // const 左值
// std::move(b)右值,推导出T为const int,模板实例化为void Function(const int&& t)
Function(std::move(b)); // const 右值
return 0;
} 

三、可变参数模板
3.1 语法与包(Parameter Pack)基础
C++11支持可变参数模板,也就是说支持可变数量参数的函数模板和类模板,可变数目的参数被称为参数包,存在两种参数包:模板参数包,表示零或多个模板参数;函数参数包:表示零或多个函数参数。
template <class… Args> void Func(Args… args) {} 传值参数包
template <class… Args> void Func(Args&… args) {} 左值引用参数包
template <class… Args> void Func(Args&&… args) {} 万能引用参数包
我们用省略号来指出⼀个模板参数或函数参数的表示⼀个包,在模板参数列表中,class…或typename…指出接下来的参数表示零或多个类型列表;在函数参数列表中,类型名后面跟…指出接下来表示零或多个形参对象列表;函数参数包可以用左值引用或右值引用表示,跟前面普通模板⼀样,每个参数实例化时遵循引用折叠规则。
可变参数模板的原理跟模板类似,本质还是去实例化对应类型和个数的多个函数。
这里我们可以使用sizeof…运算符去计算参数包中参数的个数。
template
void Print(Args&&... args)
{
cout << sizeof...(args) << endl;
}
int main()
{
double x = 2.2;
Print(); // 包⾥有0个参数
Print(1); // 包⾥有1个参数
Print(1, string("xxxxx")); // 包⾥有2个参数
Print(1.1, string("xxxxx"), x); // 包⾥有3个参数
return 0;
}
// 原理1:编译本质这⾥会结合引⽤折叠规则实例化出以下四个函数
void Print();
void Print(int&& arg1);
void Print(int&& arg1, string&& arg2);
void Print(double&& arg1, string&& arg2, double& arg3);
// 原理2:更本质去看没有可变参数模板,我们实现出这样的多个函数模板才能⽀持
// 这⾥的功能,有了可变参数模板,我们进⼀步被解放,他是类型泛化基础
// 上叠加数量变化,让我们泛型编程更灵活。
void Print();
template
void Print(T1&& arg1);
template
void Print(T1&& arg1, T2&& arg2);
template
void Print(T1&& arg1, T2&& arg2, T3&& arg3); 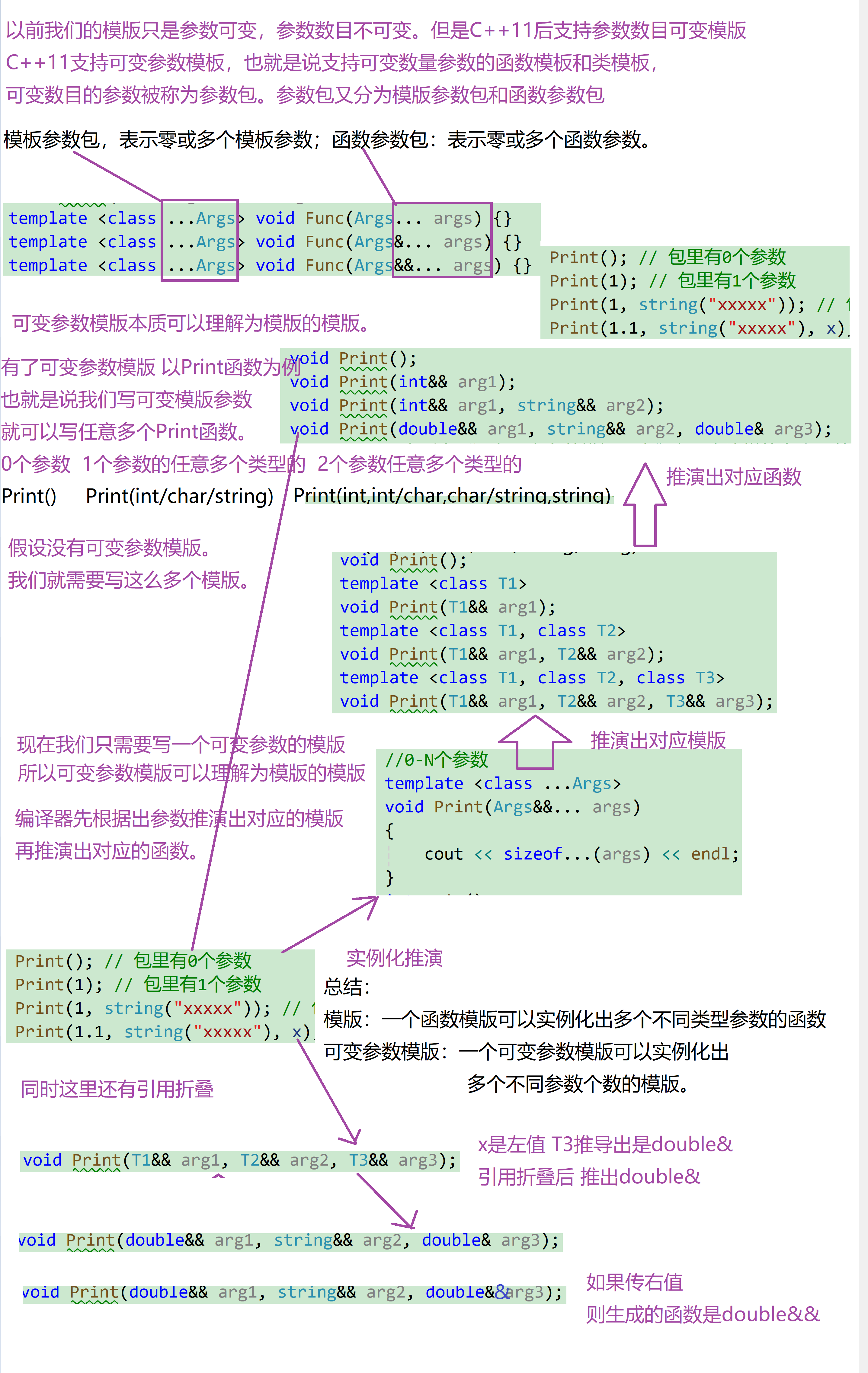
3.2 包展开(Pack Expansion)模式
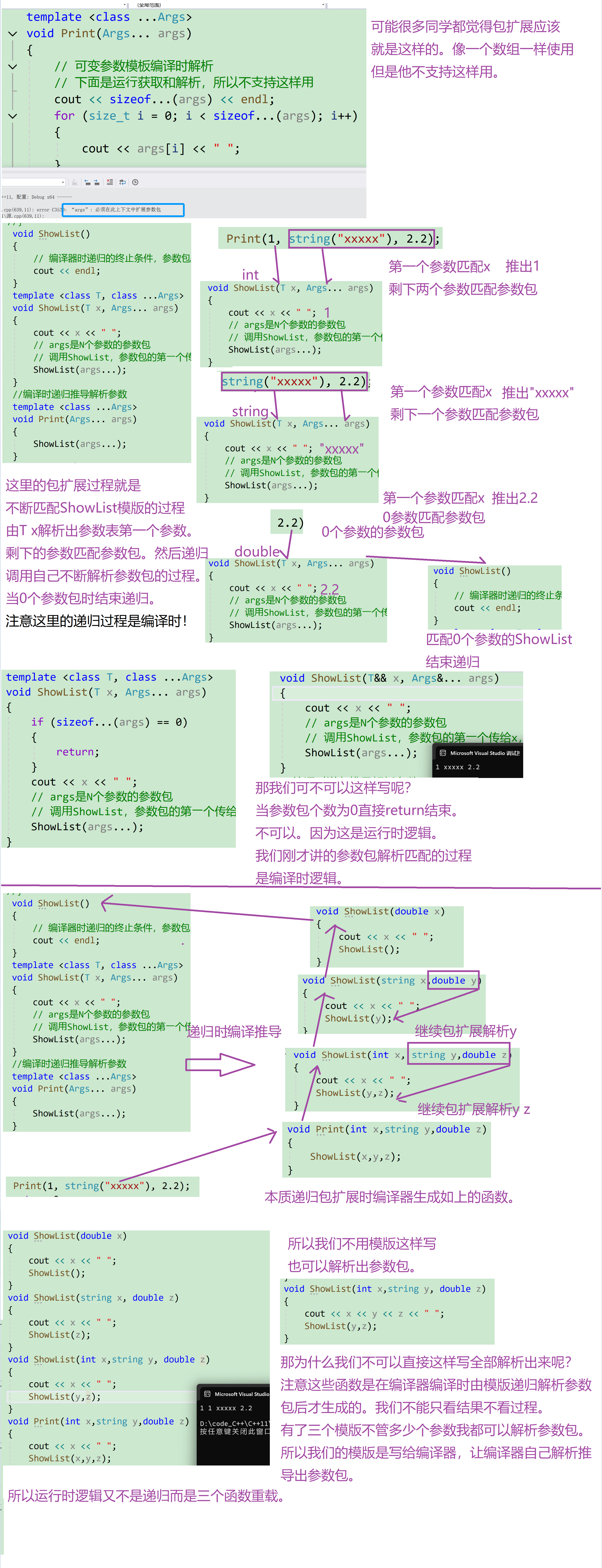
包扩展就是把参数包拆解的过程。
注意包扩展的过程是在编译时,不是运行时。
- 对于⼀个参数包,我们除了能计算他的参数个数,我们能做的唯一的事情就是扩展它,当扩展⼀个包时,我们还要提供用于每个扩展元素的模式,扩展⼀个包就是将它分解为构成的元素,对每个元素应用模式,获得扩展后的列表。我们通过在模式的右边放⼀个省略号(…)来触发扩展操作。
- C++还支持更复杂的包扩展,直接将参数包依次展开依次作为实参给一个函数去处理。
//可变模板参数
//参数类型可变
//参数个数可变
//打印参数包内容
template
void Print(Args... args)
{
// 可变参数模板编译时解析
// 下⾯是运⾏获取和解析,所以不⽀持这样⽤
cout << sizeof...(args) << endl;
for (size_t i = 0; i < sizeof...(args); i++)
{
cout << args[i] << " ";
}
}
void ShowList()
{
// 编译器时递归的终⽌条件,参数包是0个时,直接匹配这个函数
cout << endl;
}
template
void ShowList(T x, Args... args)
{
cout << x << " ";
// args是N个参数的参数包
// 调⽤ShowList,参数包的第⼀个传给x,剩下N-1传给第⼆个参数包
ShowList(args...);
}
// 编译时递归推导解析参数
template
void Print(Args... args)
{
ShowList(args...);
}
/*int main()
{
Print();
Print(1);
Print(1, string("xxxxx"));
Print(1, string("xxxxx"), 2.2);
return 0;
}*/
//template
//void ShowList(T x, Args... args)
//{
// cout << x << " ";
// Print(args...);
//}
// Print(1, string("xxxxx"), 2.2);调⽤时
// 本质编译器将可变参数模板通过模式的包扩展,编译器推导的以下三个重载函数函数
//void ShowList(double x)
//{
// cout << x << " ";
// ShowList();
//}
//
//void ShowList(string x, double z)
//{
// cout << x << " ";
// ShowList(z);
//}
//
//void ShowList(int x, string y, double z)
//{
// cout << x << " ";
// ShowList(y, z);
//}
//void Print(int x, string y, double z)
//{
// ShowList(x, y, z);
//}
template
const T& GetArg(const T& x)
{
cout << x << " ";
return x;
}
template
void Arguments(Args... args)
{}
template
void Print(Args... args)
{
// 让 GetArg 返回有值的对象(哪怕只用来占位),这样才能组成参数包给Arguments
Arguments(GetArg(args)...);
}
// 本质可以理解为编译器编译时,包的扩展模式
// 将上⾯的函数模板扩展实例化为下⾯的函数
// 是不是很抽象,C++11以后,只能说委员会的⼤佬设计语法思维跳跃得太厉害
//void Print(int x, string y, double z)
//{
// Arguments(GetArg(x), GetArg(y), GetArg(z));
//}
int main()
{
Print(1, string("xxxxx"), 2.2);
return 0;
} 
包扩展还有另一种方式。
3.3empalce系列接口

- template <class… Args> void emplace_back (Args&&… args);
- template <class… Args> iterator emplace (const_iterator position,Args&&… args);
- C++11以后STL容器新增了empalce系列的接口,empalce系列的接口均为模板可变参数,功能上兼容push和insert系列,但是empalce还支持新玩法,假设容器为container,empalce还支持直接插入构造T对象的参数,这样有些场景会更高效⼀些,可以直接在容器空间上构造T对象。
- emplace_back总体而言是更高效,推荐以后使用emplace系列替代insert和push系列
- 第二个程序中我们模拟实现了list的emplace和emplace_back接口,这里把参数包不断往下传递,最终在结点的构造中直接去匹配容器存储的数据类型T的构造,所以达到了前面说的empalce支持直接插入构造T对象的参数,这样有些场景会更高效⼀些,可以直接在容器空间上构造T对象。
- 传递参数包过程中,如果是 Args&&… args 的参数包,要用完美转发参数包,方式如下std::forward(args)… ,否则编译时包扩展后右值引用变量表达式就变成了左值。
std::listlt1;
//效率用法都是一样的
lt1.push_back(1);
lt1.emplace_back(2);
//效率用法都是一样的
std::listlt2;
xc::string s1("1111111111");
lt2.push_back(s1);
lt2.emplace_back(s1);
cout << "***************************************************************" << endl;
//效率用法都是一样的
xc::string s2("22222222222");
lt2.push_back(move(s2));
xc::string s3("2222222222");
lt2.emplace_back(move(s3));
cout << "***************************************************************" << endl;
// 优化区别
lt2.push_back("111111111111111111111111"); //构造+移动构造 析构匿名 类模板 类型 确定为 string&&
lt2.emplace_back("111111111111111111111111"); // 直接构造 函数模板 类型确定为 const char *
//push_back 要先造一个临时 string再搬进容器;
//emplace_back 把参数直接丢进容器内存,让容器里那个 string 就地用 const char* 构造,省掉临时对象及其后续移动 / 析构。
cout << "***************************************************************" << endl; 这里出现的优化区别是参数优先匹配级导致的,“谁更直接、谁更特殊、谁就少转换” —— 编译器按标准重载决议三部曲挑最匹配的那个。

回到 list 的尾插
实参:const char* 字面量 "111..."
候选函数:
// A. 普通成员函数(已实例化)
void push_back(const std::string&); // 需用户定义转换 ③
void push_back(std::string&&); // 需用户定义转换 ③
// B. 成员函数模板(需推导)
template
void emplace_back(Args&&... args); // 精确匹配 ① 路径对比
| 函数 | 转换链 | 重载等级 | 是否特殊 |
|---|---|---|---|
push_back | const char* → std::string(临时) | ③ 用户定义转换 | 否 |
emplace_back | Args = const char* 直接绑定 | ① 精确匹配 | 是(模板) |
→ 精确匹配优于用户定义转换,因此emplace_back 胜出,不会产生 std::string 临时对象。
多参数的pair也是一样的道理
std::list> lt3;
//传左值效率用法一样
pairkv1("xxxxxx", 1);
lt3.push_back(kv1);
lt3.emplace_back(kv1);
cout << "***************************************************************" << endl;
//传右值效率用法一样
pairkv2("yyyyyyy", 2);
lt3.push_back(move(kv2));
pairkv3("yyyyyyy", 2);
lt3.emplace_back(move(kv3));
cout << "***************************************************************" << endl;
// 直接传参数构造 更高效率
lt3.push_back({ "xxxxxxxxxx",1 });
//lt3.emplace_back({ "xxxxxxxxxx",1 }); //报错 花括号 识别为 initializer_list 不支持不同参数类型
lt3.emplace_back("xxxxxxxxxx", 1); //万能引用参数包直接识别构造 
//lt3.push_back("xxxxxxxxxx", 1); //报错 push_back 单参数函数
lt3.push_back({ "xxxxxxxxxx",1 });
//lt3.emplace_back({ "xxxxxxxxxx",1 }); //报错 花括号 识别为 initializer_list 不支持不同参数类型
lt3.emplace_back("xxxxxxxxxx", 1); //万能引用参数包直接识别构造lt3.push_back("xxxxxxxxxx", 1);
报错位置:语法检查阶段
push_back只有 单参数 重载你塞了 两个实参 → 直接语法错误,连重载决议都进不去
报错:
no matching function for call to 'push_back'
lt3.push_back({ "xxxxxxxxxx", 1 });
能过(C++11/14/17 默认模式)
花括号列表
{}被当成 单个子表达式编译器尝试 复制列表初始化 把该子表达式变成
value_type
(对map就是std::pair<const std::string, int>)pair有 非 explicit 模板构造函数
template
pair(U1&& a, U2&& b); 于是推导成功,生成一个临时 pair,再移动进链表
结果:隐式转换 + 一次移动构造
⚠️ C++20 若开启严格列表初始化检查会失败,但主流编译器默认仍放过
lt3.emplace_back({ "xxxxxxxxxx", 1 });
报错:花括号跨模板推导失败
emplace_back是 函数模板
template
void emplace_back(Args&&... args); 把 整个花括号列表当成一个实参 传进去 → 编译器需要推导
Args
但花括号列表 没有类型,也无法推导出Args = {const char*, int}
→ 模板推导失败
报错:
no matching function for call to 'emplace_back'
根源:花括号列表不能跨函数模板边界做类型推导(标准硬规则)
lt3.emplace_back("xxxxxxxxxx", 1);
最优:零临时、零歧义
两个实参 本身有类型 (
const char*,int)模板推导得到
Args = [const char*, int]内部直接 placement new:
new (node) std::pair("xxxxxxxxxx", 1); 无临时
pair,无移动构造,无花括号歧义
想要增加emplace系列直接这样写就可以,注意完美转发保持属性。
void emplace_back(Args&&... args)
{
insert(end(), std::forward(args)...);
}
template
iterator insert(iterator pos, Args&&... args)
{
Node* cur = pos._node;
Node* newnode = new Node(std::forward(args)...);
Node* prev = cur->_prev;
// prev newnode cur
prev->_next = newnode;
newnode->_prev = prev;
newnode->_next = cur;
cur->_prev = newnode;
return iterator(newnode);
}
template
list_node(X&&... data)
:data(forward(data)...)
, next(nullptr)
, prev(nullptr)
{} 原理就是编译器根据可变模版参数生成对应参数的函数。
 同时说明我们拿到参数包一定要包扩展吗?
同时说明我们拿到参数包一定要包扩展吗?
不是,这里我们直接把参数包往下传就可以了。
当传到data这里时直接匹配对应的对应构造即可。需要包扩展。只有当用到参数包时再包扩展。
后言
这就是C++11(二)。大家自己好好消化!感谢各位的耐心垂阅!咱们下期见!拜拜~

 浙公网安备 33010602011771号
浙公网安备 33010602011771号