

(第六篇)Spring AI 基础入门之素材持久化:向量数据库集成入门

引言:AI 时代的数据存储新范式
在大模型爆发的今天,我们处理的数据形态正在发生根本性变化。传统的结构化数据(如订单、用户信息)已无法满足 AI 应用的需求,非结构化数据(文本、图像、音频)的高效存储与检索成为核心挑战。而向量数据库,正是解决这一问题的关键技术 —— 它能将非结构化数据转换为高维向量,通过向量相似度计算实现 "语义级" 的智能检索。
Spring AI 作为 Spring 生态拥抱 AI 的重要组件,通过统一的向量存储接口(VectorStore)简化了向量数据库的集成复杂度。本文将聚焦向量数据库的选型与实战,用最直白的方式带你掌握 "3 步实现向量存储与检索" 的核心技能,尤其适合 Spring 开发者快速上手。
一、向量数据库选型:Chroma vs Milvus 深度对比
在开始实战前,我们需要先选对工具。目前主流的向量数据库中,Chroma 和 Milvus 是两个极具代表性的选择,但它们的定位和适用场景差异显著。
1.1 轻量派代表:Chroma 的核心特性
Chroma 是一款主打 "开发者友好" 的向量数据库,其设计理念是 "让向量存储像使用 Redis 一样简单"。
核心优势:
- 零配置启动:无需复杂的集群设置,单文件即可运行,适合本地开发和小规模应用
- 内存优先设计:默认使用内存存储(支持持久化到磁盘),读写速度极快
- 原生 Python/Java 支持:提供简洁的 API,Spring AI 已内置适配
- 体积小巧:Docker 镜像仅数百 MB,对硬件资源要求低
适用场景:
- 快速原型开发、POC 验证
- 中小规模向量数据(百万级以下)
- 对部署复杂度敏感的场景
1.2 企业级标杆:Milvus 的技术优势
Milvus 是专为大规模向量检索设计的企业级数据库,由 LF AI & Data 基金会托管,在金融、电商等核心业务中广泛应用。
核心优势:
- 分布式架构:支持水平扩展,轻松应对亿级向量存储
- 多索引算法:内置 IVF、HNSW 等多种索引,平衡检索速度与精度
- 高可用设计:支持数据分片、副本备份,满足生产级可靠性要求
- 丰富的生态工具:提供可视化管理界面(Attu)、数据迁移工具等
适用场景:
- 生产环境的大规模向量检索(亿级以上)
- 对高可用、高并发有严格要求的业务
- 需要与多数据源协同的复杂系统
1.3 选型决策指南(附对比表)
| 维度 | Chroma | Milvus |
|---|---|---|
| 部署复杂度 | 极低(单节点 5 分钟启动) | 中高(需配置集群组件) |
| 向量规模支持 | 百万级 | 亿级以上 |
| 资源占用 | 低(最低 512MB 内存) | 中高(建议 8GB + 内存) |
| 社区活跃度 | 快速增长(适合尝鲜) | 成熟稳定(生产首选) |
| 学习成本 | 低(API 简洁直观) | 中(需理解索引、集群概念) |
决策建议:
- 如果你是初学者、需要快速验证想法,选 Chroma;
- 如果你在构建生产级应用、数据量会持续增长,选 Milvus。
本文后续实战将以 Chroma 为例(降低入门门槛),但核心逻辑同样适用于 Milvus(Spring AI 接口统一)。
二、Spring AI VectorStore 接口:向量操作的统一抽象
Spring AI 的设计哲学是 "屏蔽底层差异,提供统一接口",向量存储也不例外。VectorStore接口定义了向量数据增删改查的标准方法,无论你用 Chroma 还是 Milvus,代码逻辑都能保持一致。
2.1 接口核心方法解析
先看VectorStore的核心方法定义(简化版):
public interface VectorStore {
// 新增/更新向量数据(存在则更新,不存在则新增)
void add(List documents);
// 根据ID删除向量
boolean delete(List documentIds);
// 相似性检索(返回最相似的topK条数据)
List similaritySearch(String query, int topK);
// 带元数据过滤的相似性检索
List similaritySearch(
String query,
int topK,
Map filter
);
} 关键概念说明:
Document:Spring AI 中表示 "带向量的数据载体",包含 3 部分:id:唯一标识content:原始文本内容metadata:附加信息(如来源、时间戳等,用于过滤)embedding:文本对应的向量(通常由嵌入模型自动生成)
2.2 方法实战场景
add 方法:批量存储文本片段当我们有一批文档(如新闻片段、产品描述)需要存入向量库时,只需将文本包装成
Document列表,调用add即可。Spring AI 会自动通过嵌入模型(如 OpenAI Embedding、本地模型)将文本转换为向量。similaritySearch 方法:实现 "语义检索"比如用户输入 "推荐一款轻便的笔记本",系统会将这句话转换为向量,然后通过该方法找到向量空间中最相似的产品描述,实现 "理解语义" 的检索效果。
带过滤的检索:缩小检索范围假设我们存储了不同类别的文档,可通过
filter参数限定检索范围(如filter = Map.of("category", "tech")),只检索科技类文档,提升效率。
2.3 接口适配原理
Spring AI 通过 "自动配置 + SPI" 机制实现多向量数据库的适配:
- 引入对应数据库的依赖(如
spring-ai-chroma)后,Spring 会自动注册该数据库的VectorStore实现类;- 开发者只需注入
VectorStore接口,无需关心具体实现,轻松切换数据库(符合 "面向接口编程" 思想)。
三、环境准备:Docker 快速部署 Chroma
接下来我们部署 Chroma 数据库,用 Docker 实现 "一键启动",避免复杂的环境配置。
3.1 安装 Docker 与 Compose
如果还没安装 Docker,先按以下步骤操作(以 Linux 为例):
# 安装Docker
sudo apt-get update
sudo apt-get install docker-ce docker-ce-cli containerd.io
# 安装Docker Compose
sudo apt-get install docker-compose-plugin
# 验证安装
docker --version
docker compose version3.2 编写 Compose 配置文件
创建docker-compose.yml文件,内容如下:
version: '3.8'
services:
chroma:
image: ghcr.io/chroma-core/chroma:latest
container_name: chroma-vector-db
ports:
- "8000:8000" # 暴露API端口
volumes:
- chroma-data:/chroma/.chroma # 持久化数据到本地卷
environment:
- IS_PERSISTENT=TRUE # 开启持久化(默认内存模式,重启数据丢失)
- PERSIST_DIRECTORY=/chroma/.chroma # 数据存储路径
restart: unless-stopped # 异常退出时自动重启
volumes:
chroma-data: # 定义数据卷,确保数据不丢失配置说明:
IS_PERSISTENT=TRUE:启用持久化,避免容器重启后数据丢失;- 数据卷
chroma-data会将数据存储在 Docker 的持久化目录(通常是/var/lib/docker/volumes/);- 端口映射
8000:8000:Chroma 默认 API 端口为 8000,映射到宿主机方便访问。
3.3 启动并验证 Chroma 服务
# 启动服务(在docker-compose.yml所在目录)
docker compose up -d
# 查看容器状态
docker ps | grep chroma-vector-db
# 验证服务可用性(返回版本信息则成功)
curl http://localhost:8000/api/v1/version成功响应示例:
{"chroma_version": "0.4.15", "server_version": "0.4.15"}四、实战:3 步构建文本片段向量存储服务
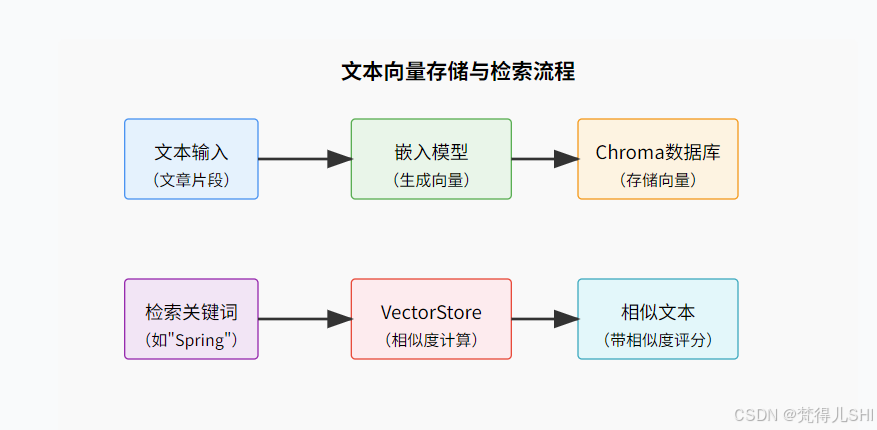
终于到了实战环节!我们将构建一个简单的 "文本片段存储与检索服务",支持将多篇文章片段存入向量库,并能根据输入文本检索最相似的片段。
4.1 第一步:搭建 Spring AI 项目基础架构
4.1.1 创建 Maven 项目,添加依赖
在pom.xml中添加核心依赖(Spring Boot 3.2+,Spring AI 0.8.1+):
org.springframework.boot
spring-boot-starter-parent
3.2.0
org.springframework.boot
spring-boot-starter
org.springframework.ai
spring-ai-vectorstore
org.springframework.ai
spring-ai-chroma
org.springframework.ai
spring-ai-transformers
org.springframework.boot
spring-boot-starter-test
test
spring-snapshots
Spring Snapshots
https://repo.spring.io/snapshot
false
4.1.2 配置应用参数
在application.yml中配置 Chroma 地址和嵌入模型:
spring:
ai:
vectorstore:
chroma:
url: http://localhost:8000 # 刚才部署的Chroma服务地址
embedding:
transformers:
model: all-MiniLM-L6-v2 # 轻量级嵌入模型(约90MB)说明:
all-MiniLM-L6-v2是一款轻量级开源嵌入模型,适合本地测试,首次启动会自动下载(需联网)。
4.2 第二步:实现文本向量的存储逻辑
4.2.1 创建服务类(核心业务逻辑)
import org.springframework.ai.document.Document;
import org.springframework.ai.vectorstore.VectorStore;
import org.springframework.stereotype.Service;
import java.util.List;
import java.util.stream.Collectors;
@Service
public class TextVectorService {
private final VectorStore vectorStore;
// 注入VectorStore(Spring自动选择Chroma实现)
public TextVectorService(VectorStore vectorStore) {
this.vectorStore = vectorStore;
}
/**
* 存储文本片段到向量库
* @param texts 文本列表
* @param category 文本类别(用于元数据过滤)
*/
public void storeTexts(List texts, String category) {
// 将文本转换为Document对象(添加元数据)
List documents = texts.stream()
.map(text -> {
Document doc = new Document(text);
// 添加元数据:类别、时间戳
doc.getMetadata().put("category", category);
doc.getMetadata().put("timestamp", System.currentTimeMillis());
return doc;
})
.collect(Collectors.toList());
// 存入向量库(自动生成向量)
vectorStore.add(documents);
System.out.println("成功存储 " + documents.size() + " 条文本");
}
} 代码说明:
- 通过构造函数注入
VectorStore,Spring 会根据依赖自动选择 Chroma 的实现;storeTexts方法接收文本列表和类别,将文本包装成Document并添加元数据;- 调用
vectorStore.add时,Spring AI 会自动使用配置的嵌入模型(all-MiniLM-L6-v2)将文本转换为向量,再存入 Chroma。
4.3 第三步:开发相似文本检索功能
在TextVectorService中添加检索方法:
/**
* 检索相似文本
* @param query 检索关键词
* @param topK 返回最相似的前K条
* @param category 可选:限定类别(null则不限定)
* @return 相似文本列表(含相似度评分)
*/
public List searchSimilarTexts(String query, int topK, String category) {
// 构建过滤条件(如果指定了类别)
Map filter = null;
if (category != null && !category.isEmpty()) {
filter = Map.of("category", category);
}
// 执行相似性检索
List similarDocs = filter != null
? vectorStore.similaritySearch(query, topK, filter)
: vectorStore.similaritySearch(query, topK);
// 打印检索结果(包含相似度评分,在metadata的"score"字段)
similarDocs.forEach(doc -> {
System.out.println("文本:" + doc.getContent());
System.out.println("相似度:" + doc.getMetadata().get("score"));
System.out.println("类别:" + doc.getMetadata().get("category") + "\n");
});
return similarDocs;
} 代码说明:
- 支持带类别的过滤检索,适合多维度数据场景;
- 检索结果的
metadata中会自动添加score字段(相似度评分,值越大越相似);- 实际应用中可根据
score设置阈值(如只返回评分 > 0.5 的结果),过滤低相似度数据。
4.4 测试:验证存储与检索功能
编写测试类TextVectorServiceTest:
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import java.util.List;
@SpringBootTest
class TextVectorServiceTest {
@Autowired
private TextVectorService textVectorService;
@Test
void testStoreAndSearch() {
// 1. 准备测试文本(3条AI相关,2条Java相关)
List aiTexts = List.of(
"Spring AI是Spring生态的AI组件,简化AI应用开发",
"向量数据库用于存储和检索高维向量,是大模型应用的核心",
"嵌入模型能将文本转换为向量,保留语义信息"
);
List javaTexts = List.of(
"Spring Boot简化了Spring应用的配置和部署",
"Java 17引入了密封类和模式匹配等新特性"
);
// 2. 存储文本(分别标记类别)
textVectorService.storeTexts(aiTexts, "ai");
textVectorService.storeTexts(javaTexts, "java");
// 3. 检索测试:查找与"Spring框架"相似的文本
System.out.println("=== 检索与'Spring框架'相似的文本 ===");
textVectorService.searchSimilarTexts("Spring框架", 2, null);
// 4. 带类别过滤的检索:查找AI类别中与"向量"相似的文本
System.out.println("=== 检索AI类别中与'向量'相似的文本 ===");
textVectorService.searchSimilarTexts("向量", 2, "ai");
}
} 预期输出:
成功存储 3 条文本
成功存储 2 条文本
=== 检索与'Spring框架'相似的文本 ===
文本:Spring AI是Spring生态的AI组件,简化AI应用开发
相似度:0.723
类别:ai
文本:Spring Boot简化了Spring应用的配置和部署
相似度:0.689
类别:java
=== 检索AI类别中与'向量'相似的文本 ===
文本:向量数据库用于存储和检索高维向量,是大模型应用的核心
相似度:0.891
类别:ai
文本:嵌入模型能将文本转换为向量,保留语义信息
相似度:0.812
类别:ai从结果可见:
- 与 "Spring 框架" 最相似的是两条含 "Spring" 的文本,符合语义预期;
- 带类别过滤的检索只返回 AI 类别的文本,精准度更高。
五、进阶思考:从 Demo 到生产的关键优化
完成基础实战后,我们需要思考生产环境的优化方向:
5.1 向量索引优化
- Chroma:默认使用暴力检索(Brute-force),数据量大时可切换为
hnsw索引(需在初始化时配置);- Milvus:根据数据量选择索引(百万级用 IVF_FLAT,亿级用 HNSW),并合理设置
nlist(聚类数量)参数。
5.2 嵌入模型选择
- 测试环境:用轻量级模型(如
all-MiniLM-L6-v2);- 生产环境:根据精度需求选择(如
text-embedding-ada-002精度高但需 API 调用,bge-large-en开源可本地部署)。
5.3 高可用设计
- Chroma:单节点适合小规模场景,大规模需考虑主从复制;
- Milvus:部署集群模式(含 Proxy、DataNode、IndexNode 等组件),配合 K8s 实现自动扩缩容。
六、总结
本文从向量数据库选型出发,对比了 Chroma 和 Milvus 的核心差异,然后通过 Spring AI 的 VectorStore 接口解析,让你理解向量操作的统一抽象,最后用 3 步实战完成了文本向量的存储与检索。
核心收获:
- 向量数据库是 AI 应用的 "语义搜索引擎",Chroma 适合入门,Milvus 适合生产;
- Spring AI 的 VectorStore 接口屏蔽了底层差异,让切换数据库变得简单;
- 实战中掌握了 "文本→向量→存储→检索" 的完整流程,可直接复用代码框架。
下一步建议:尝试集成 Milvus 实现分布式存储,或结合大模型实现 "检索增强生成(RAG)" 应用 ,这正是 Spring AI + 向量数据库的黄金组合场景。
附:关键流程示意图


 浙公网安备 33010602011771号
浙公网安备 33010602011771号