

Flink中的批和流 - 实践
好的,我们来清晰地解释一下Flink中批处理和流处理的区别与联系。
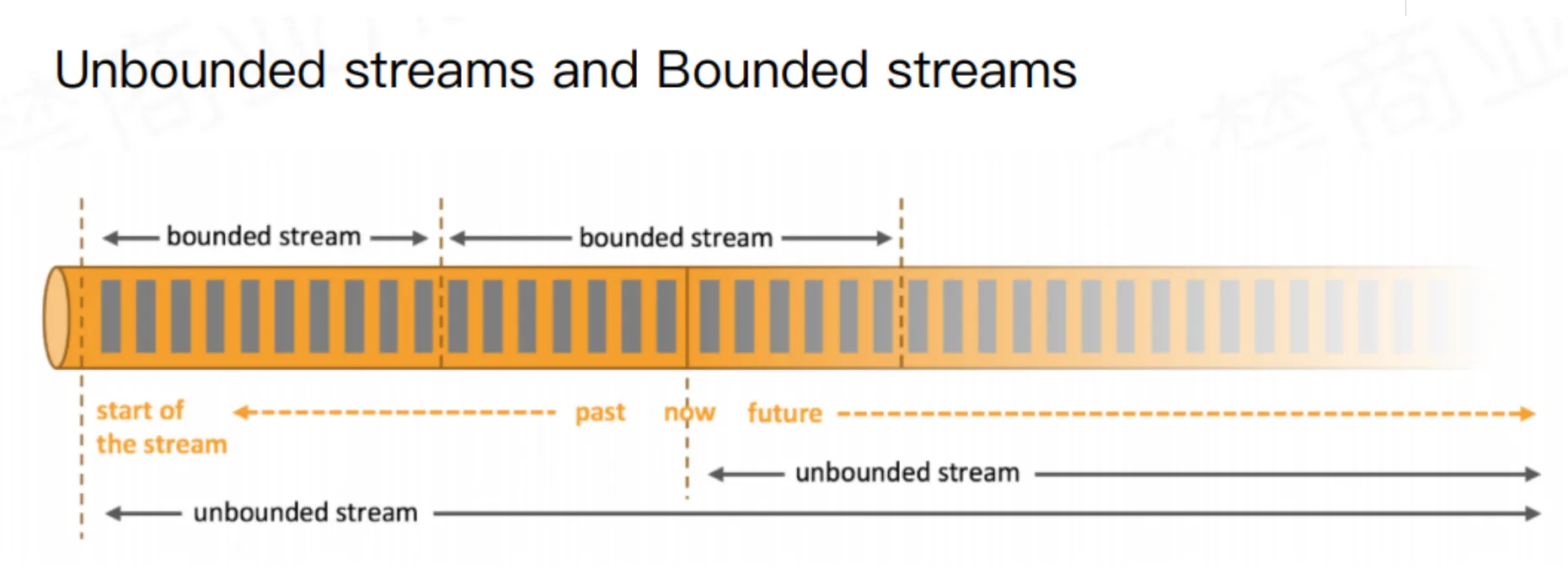
1. 核心概念
- 批处理: 处理的是有界数据集。这意味着内容集合是完整的、有限的、已知的。处理过程通常在内容集全部可用后才开始,目标是计算出最终的结果。例如,计算昨天一整天的销售总额。
- 流处理: 处理的是无界数据流。数据是连续不断地产生的,理论上没有终点。处理过程在数据到达时就开始,目标是提供低延迟的、持续更新的结果或洞察。例如,实时监控交易系统,检测欺诈行为。
2. Flink 的“批流统一”理念
Flink的核心设计哲学之一是批流统一。它认为:
- 批是流的特例:流处理(无界数据)的一种特殊情况,即流在某个时间点结束。就是批处理(有界数据)可以被看作
- 统一编程模型: Flink 提供了一个统一的运行时引擎和API(主要是
DataStream API),用于处理有界流(批)和无界流(流)。开发者允许用几乎相同的代码逻辑来处理批数据和流材料。
3. 实现层面的差异
尽管Flink在API和引擎层面力求统一,但在处理批和流时,底层运行时还是会根据数据特性进行一些优化:
- 数据源与时间概念:
- 批: 数据源通

 浙公网安备 33010602011771号
浙公网安备 33010602011771号